Перевод строки python: Работа со строками в Python: литералы
Содержание
Работа со строками в Python: литералы
Строки в Python — упорядоченные последовательности символов, используемые для хранения и представления текстовой информации, поэтому с помощью строк можно работать со всем, что может быть представлено в текстовой форме.
Это первая часть о работе со строками, а именно о литералах строк.
Литералы строк
Работа со строками в Python очень удобна. Существует несколько литералов строк, которые мы сейчас и рассмотрим.
Строки в апострофах и в кавычках
S = 'spam"s' S = "spam's"
Строки в апострофах и в кавычках — одно и то же. Причина наличия двух вариантов в том, чтобы позволить вставлять в литералы строк символы кавычек или апострофов, не используя экранирование.
Экранированные последовательности — служебные символы
Экранированные последовательности позволяют вставить символы, которые сложно ввести с клавиатуры.
| Экранированная последовательность | Назначение |
|---|---|
| \n | Перевод строки |
| \a | Звонок |
| \b | Забой |
| \f | Перевод страницы |
| \r | Возврат каретки |
| \t | Горизонтальная табуляция |
| \v | Вертикальная табуляция |
| \N{id} | Идентификатор ID базы данных Юникода |
| \uhhhh | 16-битовый символ Юникода в 16-ричном представлении |
| \Uhhhh… | 32-битовый символ Юникода в 32-ричном представлении |
| \xhh | 16-ричное значение символа |
| \ooo | 8-ричное значение символа |
| \0 | Символ Null (не является признаком конца строки) |
«Сырые» строки — подавляют экранирование
Если перед открывающей кавычкой стоит символ ‘r’ (в любом регистре), то механизм экранирования отключается.
S = r'C:\newt.txt'
Но, несмотря на назначение, «сырая» строка не может заканчиваться символом обратного слэша. Пути решения:
S = r'\n\n\\'[:-1] S = r'\n\n' + '\\' S = '\\n\\n'
Строки в тройных апострофах или кавычках
Главное достоинство строк в тройных кавычках в том, что их можно использовать для записи многострочных блоков текста. Внутри такой строки возможно присутствие кавычек и апострофов, главное, чтобы не было трех кавычек подряд.
>>> c = '''это очень большая ... строка, многострочный ... блок текста''' >>> c 'это очень большая\nстрока, многострочный\nблок текста' >>> print(c) это очень большая строка, многострочный блок текста
Это все о литералах строк и работе с ними. О функциях и методах строк я расскажу в следующей статье.
Для вставки кода на Python в комментарий заключайте его в теги <pre><code>Ваш код</code></pre>
Перевод текста на новую строка в python — симвод \n для печати текста
Символ новой строки используется в Python, чтобы отмечать конец одной строки и начало новой. Важно понимать, как использовать его для вывода в консоль и работы с файлами.
Важно понимать, как использовать его для вывода в консоль и работы с файлами.
В этом материале речь пойдет о следующем:
- Как определять символ новой строки в Python.
- Как использовать символ новой строки в строках и инструкциях вывода.
- Вывод текста без добавления символа новой строки в конце.
Символ новой строки
Символ новой строки в Python выглядит так \n. Он состоит из двух символов:
- Обратной косой черты.
- Символа n (в нижнем регистре).
Если встретили этот символ в строке, то знайте, что он указывает на то, что текущая строка заканчивается здесь, а новая начинается сразу после нее.
>>> print("Hello\nWorld!")
Hello
World!Его же можно использовать в f-строках: print(f"Hello\nWorld!").
Символ новой строки в print
По умолчанию инструкции вывода добавляют символ новой строки «за кулисами» в конце строки. Вот так:
Вот так:
Это поведение описано в документации Python. Значение параметра end встроенной функции print по умолчанию — \n. Именно таким образом символ новой строки добавляется в конце строки.
Вот определение функции:
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)Значением end='\n', поэтому именно этот символ будет добавлен к строке.
Если использовать только одну инструкцию print, то на такое поведение можно и не обратить внимание, потому что будет выведена лишь одна строка. Но если использовать сразу несколько таких инструкций:
print("Hello, World 1!")
print("Hello, World 2!")
print("Hello, World 3!")
print("Hello, World 4!")Вывод будет разбит на несколько строк, потому что символ
\nдобавится «за кулисами» в конце каждой строки:Hello, World 1! Hello, World 2! Hello, World 3! Hello, World 4!Как использовать print без символа новой строки
Изменить поведение по умолчанию можно, изменив значение параметра
endв функцииВ этом примере настройки по умолчанию приведут к такому результату:
>>> print("Hello")
>>> print("World")
Hello
WorldНо если указать значением
endпробел (" "), то этот он будет добавлен в конце строки вместо\n, поэтому вывод отобразится на одной строке:
>>> print("Hello", end=" ")
>>> print("World")
Hello WorldЭто можно использовать, например, для вывода последовательности значений в одной строке, как здесь:
for i in range(15):
if i < 14:
print(i, end=", ")
else:
print(i)Вывод будет такой:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14Примечание: условная конструкция нужна, чтобы не добавлять запятую после последнего символа.
Таким же образом можно использовать
data = [1, 2, 3, 4, 5]for num in range(len(data)):
print(data[num], end=" ")Вывод:
1 2 3 4 5Для вывода всех элементов списка списка , лучше использовать
join:" ".join([str(i) for i in data])Символ новой строки в файлах
Символ новой строки можно найти и в файлах, но он «скрыт». Создадим файл с именами. Каждое имя будет на новой строке.
names = ['Petr', 'Dima', 'Artem', 'Ivan']with open("names.txt", "w") as f:
for name in names[:-1]:
f.write(f"{name}\n")
f.write(names[-1])Если в текстовом файле есть разделение на несколько строк, то это значит, что в конце предыдущей символ
\n..readlines():
with open("names.txt", "r") as f:
print(f.readlines())Вывод:
['Petr\n', 'Dima\n', 'Artem\n', 'Ivan']Так, первые три строки текстового файла заканчиваются символом новой строки
\n, которая работает «за кулисами».Выводы
 В этом примере настройки по умолчанию приведут к такому результату:
В этом примере настройки по умолчанию приведут к такому результату:
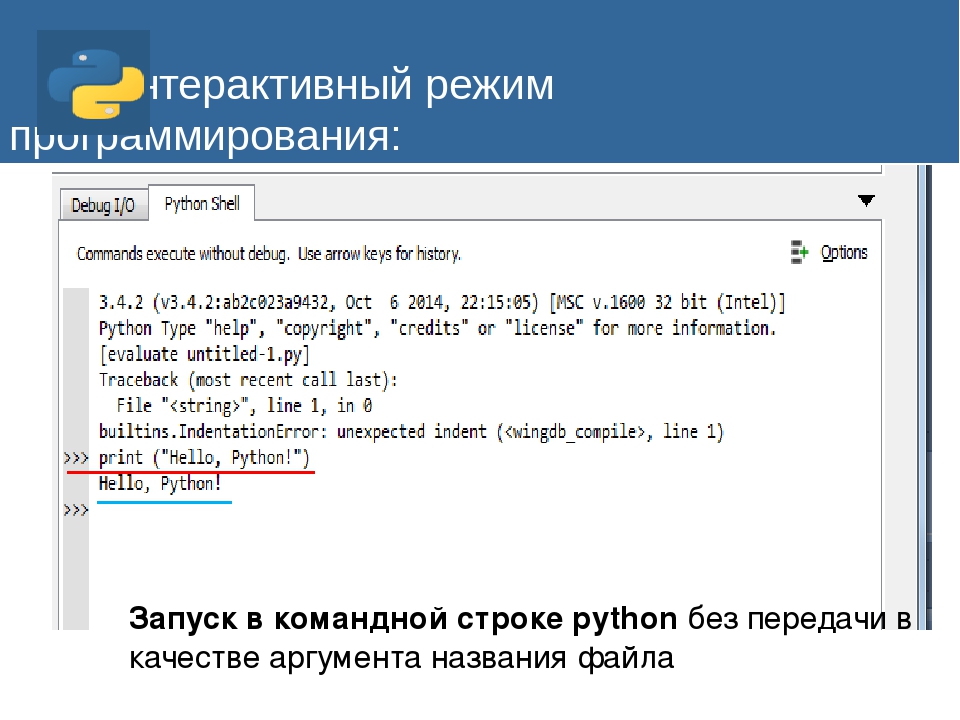 Проверить это можно с помощью функции
Проверить это можно с помощью функции - Символ новой строки в Python — это
\n. Он используется для обозначения окончания строки текста. - Вывести текст без добавления новой строки можно с помощью параметра
end ="<character>", где<character>— это символ, который дальше будет использоваться для разделения строк.
методы для форматирования и преобразование в строку
Строками в языках программирования принято называть упорядоченные последовательности символов, которые используются для представления любой текстовой информации. В Python они являются самостоятельным типом данных, а значит при помощи встроенных функций языка над ними можно производить различные операции и форматировать их для вывода.
В Python они являются самостоятельным типом данных, а значит при помощи встроенных функций языка над ними можно производить различные операции и форматировать их для вывода.
Создание
Получить новую строку можно несколькими способами: при помощи соответствующего литерала либо же вызвав готовую функцию. Для начала рассмотрим первый метод, который продемонстрирован ниже. Здесь переменная string получает значение some text, благодаря оператору присваивания. Вывести на экран созданную строку помогает функция print.
string = 'some text' print(string) some text
Как видно из предыдущего примера, строковый литерал обрамляется в одиночные кавычки. Если необходимо, чтобы данный символ был частью строки, следует применять двойные кавычки, как это показано в следующем фрагменте кода. Из результатов его работы видно, что новая строка включает в себя текст some ‘new’ text, который легко выводится на экран.
string = "some 'new' text" print(string) some 'new' text
Иногда возникает потребность в создании объектов, включающих в себя сразу несколько строк с сохранением форматирования. Эту задачу поможет решить троекратное применение символа двойных кавычек для выделения литерала. Объявив строку таким образом, можно передать ей текст с неограниченным количеством абзацев, что показано в данном коде.
Эту задачу поможет решить троекратное применение символа двойных кавычек для выделения литерала. Объявив строку таким образом, можно передать ей текст с неограниченным количеством абзацев, что показано в данном коде.
string = """some 'new' text with new line here""" print(string) some 'new' text with new line here
Специальные символы
Пользоваться тройными кавычками для форматирования строк не всегда удобно, так как это порой занимает слишком много места в коде. Чтобы задать собственное форматирование текста, достаточно применять специальные управляющие символы с обратным слэшем, как это показано в следующем примере. Здесь используется символ табуляции \t, а также знак перехода на новую строку \n. Метод print демонстрирует вывод нового объекта на экран.
string = "some\ttext\nnew line here" print(string) some text new line here
Служебные символы для форматирования строк выполняют свои функции автоматически, но иногда это мешает, к примеру, когда требуется сохранить путь к файлу на диске. Чтобы их отключить, необходимо применить специальный префикс r перед первой кавычкой литерала. Таким образом, обратные слэши будут игнорироваться программой во время ее запуска.
Чтобы их отключить, необходимо применить специальный префикс r перед первой кавычкой литерала. Таким образом, обратные слэши будут игнорироваться программой во время ее запуска.
string = r"D:\dir\new"
Следующая таблица демонстрирует перечень всех используемых в языке Python служебных символов для форматирования строк. Как правило, большинство из них позволяют менять положение каретки для выполнения перевода строки, табуляции или возврата каретки.
| Символ | Назначение |
| \n | Перевод каретки на новую строку |
| \b | Возврат каретки на один символ назад |
| \f | Перевод каретки на новую страницу |
| \r | Возврат каретки на начало строки |
| \t | Горизонтальная табуляция |
| \v | Вертикальная табуляция |
| \a | Подача звукового сигнала |
| \N | Идентификатор базы данных |
| \u, \U | 16-битовый и 32-битовый символ Unicode |
| \x | Символ в 16-ричной системе исчисления |
| \o | Символ в 8-ричной системе исчисления |
| \0 | Символ Null |
Очень часто испльзуется \n. С помощью него осуществляется в Python перенос строки. Рассмотрим пример:
С помощью него осуществляется в Python перенос строки. Рассмотрим пример:
print('first\nsecond')
first
secondФорматирование
Выполнить форматирование отдельных частей строки, задав в качестве ее компонентов некие объекты программы позволяет символ %, указанный после литерала. В следующем примере показано, как строковый литерал включает в себя не только текст, но также строку и целое число. Стоит заметить, что каждой переменной в круглых скобках должен соответствовать специальный символ в самом литерале, обладающий префиксом % и подходящим значением.
string = "text" number = 10 newString = "this is %s and digit %d" % (string, number) print(newString) this is text and digit 10
В приведенном ниже фрагменте кода демонстрируется использование форматирования для вывода строки с выравниванием по правому краю (общая длина символов указана как 10).
string = "text" newString = "%+10s" % string print(newString) text
Данная таблица содержит в себе все управляющие символы для форматирования строк в Python, каждый из которых обозначает определенный объект: числовой либо же символьный.
| Символ | Назначение |
| %d, %i, %u | Число в 10-ричной системе исчисления |
| %x, %X | Число в 16-ричной системе исчисления с буквами в нижнем и верхнем регистре |
| %o | Число в 8-ричной системе исчисления |
| %f, %F | Число с плавающей точкой |
| %e, %E | Число с плавающей точкой и экспонентой в нижнем и верхнем регистре |
| %c | Одиночный символ |
| %s, %r | Строка из литерала и обычная |
| %% | Символ процента |
Более удобное форматирование выполняется с помощью функции format. Ей необходимо передать в качестве аргументов объекты, которые должны быть включены в строку, а также указать места их расположения с помощью числовых индексов, начиная с нулевого.
string = "text"
number = 10
newString = "this is {0} and digit {1}". ’
Выравнивание строки по центру с символами-заполнителями с обеих сторон
‘+’
Применение знака для любых чисел
‘-‘
Применение знака для отрицательных чисел и ничего для положительных
‘ ‘
Применение знака для отрицательных чисел и пробела для положительных
Операции над строками
Прежде чем перейти к функциям для работы со строками, следует рассмотреть основные операции с ними, которые позволяют быстро преобразовывать любые последовательности символов. При помощи знака плюс можно производить конкатенацию строк, соединяя их вместе. В следующем примере продемонстрировано объединение this is new и text.
string = "text"
newString = "this is new " + string
print(newString)
this is new text
Пользуясь символом умножения, программист получает возможность дублировать строку любое количество раз. В данном коде слово text записывается в новую строку трижды.
string = "text "
newString = string * 3
print(newString)
text text text
Как и в случае с числами, со строками можно использовать операторы сравнения, например двойное равно. Очевидно, что литералы some text и some new text разные, поэтому вызов метода print выводит на экран булево значение False для строк string и newString.
string = "some text"
newString = "some new text"
print(string == newString)
False
Операции над строками позволяют получать из них подстроки, делая срезы, как с обычными элементами последовательностей. В следующем примере, необходимо лишь указать нужный интервал индексов в квадратных скобках, помня, что нумерация осуществляется с нуля.
string = "some text"
newString = string[2:4]
print(newString)
me
Отрицательный индекс позволяет обращаться к отдельным символами строки не с начала, а с конца. Таким образом, элемент под номером -2 в строке some text является буквой x.
string = "some text"
print(string[-2])
x
Методы и функции
Очень часто используется для приведения типов к строковому виду функция str. С ее помощью можно создать новую строку из литерала, который передается в качестве аргумента. Данный пример демонстрирует инициализацию переменной string новым значением some text.
string = str("some text")
print(string)
some textАргументом этой функции могут быть переменные разных типов, например числа или списки. Эта функция позволяет в Python преобразовать в строку разные типы данных. Если вы создаете свой класс, то желательно определить для него метод __str__. Этот метод должен возвращать строку, которая будет возвращена в случае, когда в качестве аргумента str будет использован объект вашего класса.
В Python получения длины строки в символах используется функция len. Как видно из следующего фрагмента кода, длина объекта some text равняется 9 (пробелы тоже считаются).
string = "some text"
print(len(string))
9
Метод find позволяет осуществлять поиск в строке. При помощи него в Python можно найти одиночный символ или целую подстроку в любой другой последовательности символов. В качестве результата своего выполнения он возвращает индекс первой буквы искомого объекта, при этом нумерация осуществляется с нуля.
string = "some text"
print(string.find("text"))
5Метод replace служит для замены определенных символов или подстрок на введенную программистом последовательность символов. Для этого необходимо передать функции соответствующие аргументы, как в следующем примере, где пробелы заменяются на символ ‘-‘.
string = "some text"
print(string.replace(" ", "-"))
some-textДля того чтобы разделить строку на несколько подстрок при помощи указанного разделителя, следует вызвать метод split. По умолчанию его разделителем является пробел. Как показано в приведенном ниже примере, some new text трансформируется в список строк strings.
string = "some new text"
strings = string.split()
print(strings)
['some', 'new', 'text']
Выполнить обратное преобразование, превратив список строк в одну можно при помощи метода join. В следующем примере в качестве разделителя для новой строки был указан пробел, а аргументом выступил массив strings, включающий some, new и text.
strings = ["some", "new", "text"]
string = " ".join(strings)
print(string)
some new text
Наконец, метод strip используется для автоматического удаления пробелов с обеих сторон строки, как это показано в следующем фрагменте кода для значения объекта string.
string = " some new text "
newString = string.strip()
print(newString)
some new text
Ознакомиться с функциями и методами, используемыми в Python 3 для работы со строками можно из данной таблицы. В ней также приведены методы, позволяющие взаимодействовать с регистром символов.
 ’
’


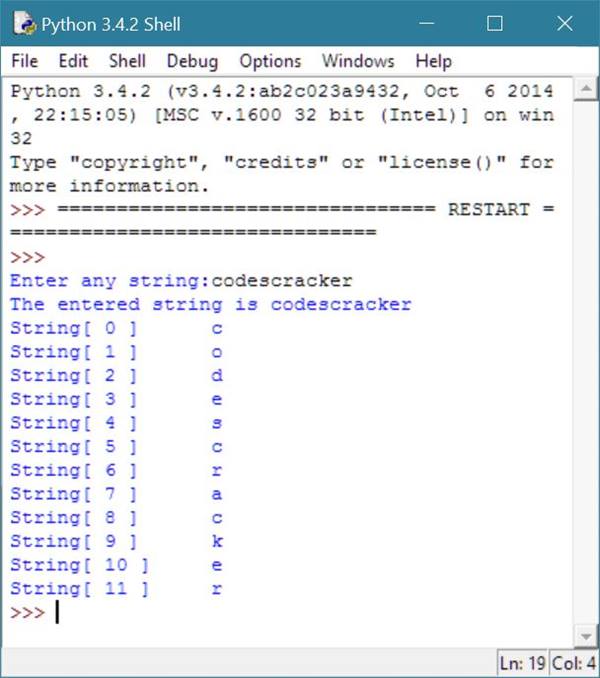
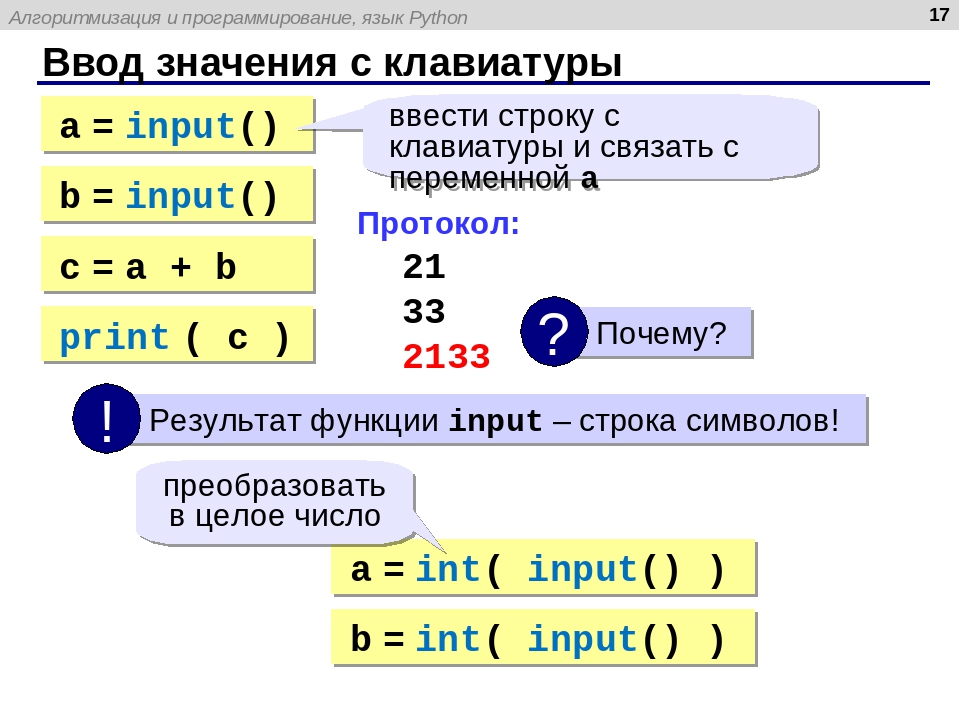
| Метод | Назначение |
| str(obj) | Преобразует объект к строковому виду |
| len(s) | Возвращает длину строки |
| find(s, start, end), rfind(s, start, end) | Возвращает индекс первого и последнего вхождения подстроки в s или -1, при этом поиск идет в границах от start до end |
| replace(s, ns) | Меняет выбранную последовательность символов в s на новую подстроку ns |
| split(c) | Разбивает на подстроки при помощи выбранного разделителя c |
| join(c) | Объединяет список строк в одну при помощи выбранного разделителя c |
| strip(s), lstrip(s), rstrip(s) | Убирает пробелы с обоих сторон s, только слева или только справа |
| center(num, c), ljust(num, c), rjust(num, c) | Возвращает отцентрированную строку, выравненную по левому и по правому краю с длиной num и символом c по краям |
| lower(), upper() | Перевод всех символов в нижний и верхний регистр |
| startwith(ns), endwith(ns) | Проверяет, начинается ли или заканчивается строка подстрокой ns |
| islower(), isupper() | Проверяет, состоит ли строка только из символов в нижнем и верхнем регистре |
| swapcase() | Меняет регистр всех символов на противоположный |
| title() | Переводит первую букву каждого слова в верхний регистр, а все остальные в нижний |
| capitalize() | Переводит первую букву в верхний регистр, а все остальные в нижний |
| isalpha() | Проверяет, состоит ли только из букв |
| isdigit() | Проверяет, состоит ли только из цифр |
| isnumeric() | Проверяет, является ли строка числом |
Кодировка
Чтобы задать необходимую кодировку для используемых в строках символов в Python достаточно поместить соответствующую инструкцию в начало файла с кодом, как это было сделано в следующем примере, где используется utf-8. С помощью префикса u, который стоит перед литералом, можно помечать его соответствующей кодировкой. В то же время префикс b применяется для литералов строк с элементами величиной в один байт.
С помощью префикса u, который стоит перед литералом, можно помечать его соответствующей кодировкой. В то же время префикс b применяется для литералов строк с элементами величиной в один байт.
# coding: utf-8 string = u'some text' newString = b'text'
Производить кодирование и декодирование отдельных строк с заданной кодировкой позволяют встроенные методы decode и encode. Аргументом для них является название кодировки, как в следующем примере кода, где применяется наименование utf-8.
string = string.decode('utf8')
newString = newString.encode('utf8')Работа со строками в Python
В общем говоря над строками нельзя производить такие же действия, что и с числами. Но оператор + работает с текстом и означает сцепление строк.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
def primer_3(): # Объявление функции primer_2()
a='Я'
b=' программирую на языке'
f=' Python'
print (a+b+f+' :)')
# сцепляем строковые переменные a,
# b, f и 'текст' :)
def main():
primer_3()
return 0
if __name__ == '__main__':
main()Оператор * тоже можно использовать, но при условии, что одним из операндов будет целое число. данный оператор символизирует операцию повторения строки. Пример:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
def primer_4(): # Объявление функции primer_4()
a='Я'
b=' программирую на языке'
f=' Python \n' # специальный символ \n
# означает переход на следующую
# строку
g=a+b+f
print (g * 3)
# распечатывам значение
# переменной g 3 раза
def main():
primer_4()
return 0
if __name__ == '__main__':
main()Здесь будут описаны особенности, расширенные возможности.
P = '' # Пустая строка
P = "C'est une pomme" # Строка в кавычках
block = """.......""" # Блоки в тройных кавычках
P = r'\tmp\home' # Неформатированные строки
P = u'pomme' # Строки с символами Юникода
P * 3 # Повторять строку (3 раза)
P [1] # Обратиться к символу (к 1-у)
P [:-1] # Текст без последнего символа
P [5:16] # Срез от 5 до 16 символа
P.find('Pa') # Поиск
P.rstrip() # Удаление пробельных символов
P.replace('Pa','xx') # Заменить (pa на xx)
P.split(',') # Разбитие по символу-разделителю
P.isdigit() # Проверка содержимого
P.lower() # Преобразование регистра символов
P.endswith('pomme') # Проверка окончания строки
P.encode('latin-1') # Кодирование строк Юникода
# ======= специальные символы =======
\newline # Продолжение на новой строке
\\ # Остаётся один символ \
\' # Апостроф (Остаётся один символ ')
\" # Кавычки (Остаётся один символ ")
\a # Звонок
\b # Забой
\f # Перевод формата
\n # Новая строка
\r # Возврат каретки
\t # Горизонтальная табуляция
\v # Вертикальная табуляция
\xhh # Символ с шестнадцатеричным кодом hh
\ooo # Символ с восьмеричным кодом 000
\0 # Символ Null
\N{id} # Id базы данных Юникода
\uhhhh # 16-битный символ Юникода
\Uhhhhhhhh # 32-битный символ ЮникодаПример программы:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
def primer_5(): # Объявление функции primer_5()
a='Я программирую на языке Python \n'
b='This is an apple'
print (a * 5)
print(b)
print (b[5:10]+' с 5 по 10 символ')
def main():
primer_5()
return 0
if __name__ == '__main__':
main()Если Вы живете в Волгограде или в близи данного города, советуем Вас теплым летним днем посетить список мест где есть в Волгограде бассейны для отличного время провождения вместе с друзьями и семьей.
Экранированные последовательности - Python
Мы хотим показать диалог Матери Драконов со своим ребенком:
- Are you hungry?
- Aaaarrrgh!
Если вывести на экран строку с таким текстом:
print("- Are you hungry?- Aaaarrrgh!")
то получится так:
- Are you hungry?- Aaaarrrgh!
Не то, что мы хотели. Строки расположены друг за другом, а не одна ниже другой. Нам нужно как-то сказать интерпретатору «нажать на энтер» — сделать перевод строки после вопросительного знака. Это можно сделать, используя символ перевода строки: \n.
print("- Are you hungry?\n- Aaaarrrgh!")
результат:
- Are you hungry?
- Aaaarrrgh!
\n - это пример экранированной последовательности (escape sequence). Их еще называют управляющими конструкциями. Эти конструкции не являются видимой частью строки, их нельзя увидеть глазами в том же виде, в котором они были набраны.
Набирая текст в каком-нибудь Word, вы нажимаете на Enter в конце строчки. Редактор при этом ставит в конец строчки специальный невидимый символ, который называется LINE FEED (LF, перевод строчки). В некоторых редакторах можно даже включить отображение невидимых символов. Тогда текст будет выглядеть примерно так:
- Привет!¶
- О, привет!¶
- Как дела?
Устройство, которое выводит соответствующий текст, учитывает этот символ. Например, принтер при встрече с LF протаскивает бумагу вверх на одну строку, а текстовый редактор переносит весь последующий текст ниже, также на одну строку.
Хотя таких символов не один десяток, в программировании часто встречаются всего несколько. Кроме перевода строки, к таким символам относятся табуляция \t (разрыв, получаемый при нажатии на кнопку Tab) и возврат каретки \r (только в Windows). Распознать управляющую конструкцию в тексте проще всего по символу \. Нам, программистам, часто нужно использовать, например, перевод строки \n для правильного форматирования текста.
print("Gregor Clegane\nDunsen\nPolliver\nChiswyck")
На экран выведется:
Gregor Clegane
Dunsen
Polliver
Chiswyck
Обратите внимание на следующие моменты:
1. Не имеет значения, что стоит перед или после \n: символ или пустая строка. Перевод будет обнаружен и выполнен в любом случае.
2. Помните, что строка может содержать лишь один символ или вообще ноль символов? А еще строка может содержать только \n:
print('Gregor Clegane')
print("\n")
print('Dunsen')
Здесь мы выводим одну строку с именем, потом одну строку «перевод строки», а потом еще одну строку. Программа выведет на экран:
Gregor Clegane
Dunsen
3. Несмотря на то, что в исходном тексте программы последовательность типа \n выглядит как два символа, с точки зрения интерпретатора это специальный один символ.
4. Если нам понадобится вывести \n именно как текст (два отдельных печатных символа), то можно воспользоваться уже известным нам способом экранирования, добавив еще один \ в начале. То есть последовательность \\n отобразится как символы \ и n, идущие друг за другом.
print("Joffrey loves using \\n")
на экран выйдет:
Joffrey loves using \n
Небольшое, но важное замечание про Windows. В Windows для перевода строк по умолчанию используется \r\n. Такая комбинация хорошо работает только в Windows, но создает проблемы при переносе в другие системы (например, когда в команде разработчиков есть пользователи как Windows, так и Linux). Дело в том, что последовательность \r\n имеет разную трактовку в зависимости от выбранной кодировки (рассматривается позже). По этой причине в среде разработчиков принято всегда использовать \n без \r, так как LF всегда трактуется одинаково и отлично работает в любой системе. Не забудьте настроить ваш редактор на использование \n.
Задание
Напишите программу, которая выводит на экран:
- Did Joffrey agree?
- He did. He also said "I love using \n".
При этом программа использует только один print, но результат на экране должен выглядеть в точности как показано выше.
Советы
Определения
Экранированная последовательность - специальная комбинация символов в тексте. Например,
— это перевод строки.
Нашли ошибку? Есть что добавить? Пулреквесты приветствуются https://github.com/hexlet-basics
Перенос строк кода Python - tirinox.ru
Подписывайтесь на мой канал в Телеграм @pyway , чтобы быть в курсе о новых статьях!
PEP-8 не рекомендует писать строки кода длиннее, чем 79 символов. С этим можно не согласиться, однако, встречаются строки, которые не влезают даже на наши широкоформатные мониторы.
👨🎓 Старайтесь не делать очень длинные строки, разбивая сложные условия или формулы на отдельные части, вынося их в переменные или функции с осмысленными названиями.
Если есть острая необходимость иметь длинное выражение, тогда приходится переносить код на следующие строки. Можно делать двумя способами: скобками и слэшем.
Если, перед выражением открыта скобка (круглая, квадратная или фигурная в зависимости от контекста), но она не закрыта в этой строке, то Python будет сканировать последующие строки, пока не найдет соответствующую закрывающую скобку (англ. implicit line joining). Примеры:
# вычисления
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)
if (student_loan_interest > ira_deduction
and qualified_dividends == 0):
...
# словари
d = {
"hello": 10,
"world": 20,
"abc": "foo"
}
# аргументы функции
some_func(arg1,
arg2,
more_arg,
so_on_and_on)Обратите внимание, что в первом примере скобки очень важны. Без скобок код не скомпилируется из-за отступов, а если их убрать, то результат будет неверен: income станет gross_wages, а последующие строки не будут иметь эффекта!
# неправильно! income = gross_wages + taxable_interest + (dividends - qualified_dividends) - ira_deduction - student_loan_interest
Метод переноса обратным слэшем. Ставим обратный слэш конце строки и сразу энтер (перенос строки): тогда следующая строка будет включена в текущую (англ. explicit line joining), не взирая на отступы, как будто бы они написаны в одну строку:
income = gross_wages \
+ taxable_interest \
+ (dividends - qualified_dividends) \
- ira_deduction \
- student_loan_interestЕще примеры со слэшем:
if student_loan_interest > ira_deduction \
and qualified_dividends == 0:
...
# допустимо, согласно PEP-8
with open('/path/to/some/file/you/want/to/read') as file_1, \
open('/path/to/some/file/being/written', 'w') as file_2:
file_2.write(file_1.read())
# пробелы в строку попадут, а энтер - нет!
str = "Фу\
< вот эти пробелы тоже в строке"Почему скобки лучше для переноса:
- Лучше восприятие
- Скобок две, а слэшей надо по одному на каждый перенос
- Можно забыть слэш и сломать код
- Можно поставить пробел после слэша и тоже сломать
🐉 Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈
14 729
Перевод текста на новую строку в Python. Как перенести текст на новую строку – инструкция
Для того чтобы в Python обозначить конец одной строки и начать новую, нужно использовать специальный символ. При этом важно знать, как его правильно использовать в работе с различными файлами Python, в требуемые моменты отображать его в консоли. Подробно необходимо разобраться с тем, как пользоваться разделительным знаком для новых строк при работе с программным кодом, можно ли добавлять текст без его применения.
Общая информация о символе новой строки
\n – обозначение переноса информации на новую строку и закрытия старой строчки в Python. Данный символ состоит из двух элементов:
- обратная косая;
- n – символ из нижнего регистра.
Для использования данного символа можно применить выражение “print(f”Hello\nWorld!”)”, за счет которого можно переносить информацию в f-строках.
Пример использования символа \n для распределения массива информации по новым строчкам
Что такое функция print
Без дополнительных настроек символ переноса данных на следующую строку добавляется в скрытом режиме. За счет этого его невозможно увидеть между строк без активации определенной функции. Пример отображение разделительного значка в программном коде:
Print (“Hello, World”!”) – “Hello, World!”\n
При этом такое нахождение данного символа прописано в базовых характеристиках Python. Функция “print” имеет стандартное значение для параметра “end” – \n. Именно благодаря данной функции этот символ выставляется в конце строк для переноса данных на следующие строчки. Расшифровка функции “print”:
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
Значение параметра “end” из функции “print” равняется символу “\n”. По автоматическому алгоритму программного кода он дополняет строчки на конце, перед которыми прописывается функция “print”. При использовании одной функции “print” можно не заметить суть ее работы, так как на экран будет выводиться только одна строка. Однако, если добавить несколько подобных инструкций, результат работы функции станет более явным:
print("Hello, World 1!")
print("Hello, World 2!")
print("Hello, World 3!")
print("Hello, World 4!")Пример результата, прописанного выше программного кода:
Hello, World 1! Hello, World 2! Hello, World 3! Hello, World 4!
Замена символа новой строки через print
Используя функцию “print”, можно не применять разделительный значок между строк. Для этого в самой функции необходимо изменить параметр “end”. При этом вместо значения “end” нужно добавить пробел. За счет этого именно пробелом будет заменен символ “end”. Результат при установленных настройках по умолчанию:
>>> print("Hello")
>>> print("World")
Hello
WorldОтображение результата после замены символа “\n” на пробел:
>>> print("Hello", end=" ")
>>> print("World")
Hello WorldПример использования данного способа замены символов для отображения последовательности значений через одну строчку:
for i in range(15): if i < 14: print(i, end=", ") else: print(i)
Использование разделительного символа в файлах
Символ, после которого текст программного кода переносится на следующую строчку, можно найти в готовых файлах. Однако без рассмотрения самого документа через программный код увидеть его невозможно, так как подобные символы по умолчанию скрыты. Для того чтобы использовать символ начала новых строк, необходимо создать файл, заполненный именами. После его открытия можно увидеть, что все имена будут начинаться с новой строки. Пример:
names = ['Petr', 'Dima', 'Artem', 'Ivan']
with open("names.txt", "w") as f:
for name in names[:-1]:
f.write(f"{name}\n")
f.write(names[-1])Так отображаться имена будут только в том случае, если в текстовом файле установлено разделение информации на отдельные строки. При этом в конце каждой предыдущей строки будет автоматически установлен скрытый символ “\n”. Чтобы увидеть скрытый знак, нужно активировать функцию – “.readlines()”. После этого все скрытые символы отобразятся на экране в программном коде. Пример активации функции:
with open("names.txt", "r") as f:
print(f.readlines())Назначение различных символов для работы в Python
Совет! Активно работая с Python, пользователи часто сталкиваются с ситуациями, когда программный код необходимо записать в одну длинную строку, однако рассматривать его и выявлять неточности крайне сложно без разделения. Чтобы после разделения длинной строчки на отдельные фрагменты компьютер считал ее цельной, в каждом свободном промежутке между значениями необходим вставить символ “\” – обратный слеш. После добавления символа можно перейти на другую строчку, продолжить писать код. Во время запуска программа сама соберет отдельные фрагменты в цельную строку.
Разделение строки на подстроки
Чтобы разделить одну длинную строчку на несколько подстрочек, можно воспользоваться методом split. Если не вносить дополнительных правок, стандартным разделителем является пробел. После выполнения данного метода выбранный текст разделяется на отдельные слова по подстрочкам, преобразуется в список strings. Как пример:
string = "some new text" strings = string.split() print(strings) ['some', 'new', 'text']
Для того чтобы провести обратное преобразование, с помощью которого список подстрочек превратится в одну длинную строку, необходимо воспользоваться методом join. Еще один полезный метод для работы со строками – strip. С его помощью можно удалять пробелы, которые расположены с двух сторон от строки.
Заключение
Чтобы при работе в Python выводить определенные данные с новой строки, необходимо заканчивать старую строчку символом “\n”. С его помощью информация, стоящая после знака, переносится на следующую строку, а старая закрывается. Однако для переноса данных не обязательно использовать данный символ. Для этого можно воспользоваться параметром end =”<character>”. Значение “character” и является разделительным символом.
Оцените качество статьи. Нам важно ваше мнение:
Python Новая строка и как Python печатать без новой строки
Добро пожаловать! Символ новой строки в Python используется для обозначения конца строки и начала новой строки. Знание того, как его использовать, очень важно, если вы хотите распечатать вывод на консоль и работать с файлами.
Из этой статьи вы узнаете:
- Как определить символ новой строки в Python.
- Как символ новой строки может использоваться в строках и операторах печати.
- Как можно писать операторы печати, которые не добавляют символ новой строки в конец строки.
Начнем! ✨
🔹 Символ новой строки
Символ новой строки в Python:
Он состоит из двух символов:
- Обратная косая черта.
- Письмо
н.
Если вы видите этот символ в строке, это означает, что текущая строка заканчивается в этой точке, а новая строка начинается сразу после нее:
Вы также можете использовать этот символ в f-строках :
> >> print (f "Hello \ nWorld!") 🔸 Символ новой строки в операторах печати
По умолчанию операторы печати добавляют символ новой строки «за кадром» в конец строки.
Как это:
Это происходит потому, что, согласно документации Python:
Значение по умолчанию параметра end встроенной функции print - \ n , поэтому добавляется новый символ строки к строке.
💡 Совет: Добавить означает «добавить в конец».
Это определение функции:
Обратите внимание, что значение end равно \ n , поэтому оно будет добавлено в конец строки.
Если вы используете только один оператор печати, вы не заметите этого, потому что будет напечатана только одна строка:
Но если вы используете несколько операторов печати один за другим в скрипте Python:
Вывод будет напечатан в отдельные строки, потому что \ n был добавлен «за кулисами» в конец каждой строки:
🔹 Как печатать без новой строки
Мы можем изменить это поведение по умолчанию, настроив значение параметра end функции print .
Если мы используем значение по умолчанию в этом примере:
Мы видим вывод, напечатанный в двух строках:
Но если мы настроим значение конец и установим его на ""
Будет добавлено пространство до конца строки вместо символа новой строки \ n , поэтому выходные данные двух операторов печати будут отображаться в одной строке:
Вы можете использовать это для печати последовательности значений в одной строке, например в этом примере:
Результат:
💡 Совет: Мы добавляем условный оператор, чтобы гарантировать, что запятая не будет добавлена к последнему номеру последовательности.
Точно так же мы можем использовать это для печати значений итерации в той же строке:
Результат:
🔸 Символ новой строки в файлах
Символ новой строки \ n также находится в файлах , но он «скрыт». Когда вы видите новую строку в текстовом файле, это означает, что был вставлен символ новой строки \ n .
Вы можете проверить это, прочитав файл с помощью , например:
с open ("names.txt "," r ") как f:
print (f.readlines ()) Результат:
Как видите, первые три строки текстового файла заканчиваются новой строкой \ n символ, который работает «за кадром».
💡 Совет: Обратите внимание, что только последняя строка файла не заканчивается символом новой строки.
🔹 Вкратце
- Символ новой строки в Python -
\ n. Он используется для обозначения конца строки текста. - Вы можете печатать строки без добавления новой строки с
end =, где
Я очень надеюсь, что вам понравилась моя статья и вы нашли ее полезной. Теперь вы можете работать с символом новой строки в Python.
Ознакомьтесь с моими онлайн-курсами. Подпишись на меня в Твиттере.
2.4.1 Строковые литералы
2.4.1 Строковые литералы
2.4.1 Строковые литералы
Строковые литералы описываются следующими лексическими определениями:
stringliteral: короткая строка | длинная струна shortstring: "'" shortstringitem * "'" | '"' shortstringitem * '"' longstring: "'' '" longstringitem * "' ''" | '"" "' longstringitem * '" ""' shortstringitem: shortstringchar | escapeseq longstringitem: longstringchar | escapeseq shortstringchar: <любой символ ASCII, кроме "\", новой строки или кавычки> longstringchar: <любой символ ASCII, кроме "\"> escapeseq: "\" <любой символ ASCII>
На простом английском языке: строковые литералы могут быть заключены в соответствующий одиночный
кавычки ( ') или двойные кавычки ( ").Они также могут быть
заключены в совпадающие группы из трех одинарных или двойных кавычек (эти
обычно называются строками в тройных кавычках (). В
обратная косая черта ( \ ) используется для экранирования символов, которые
в противном случае имеют особое значение, например, новую строку, обратную косую черту,
или символ кавычки. Строковые литералы необязательно могут иметь префикс
с буквой "r" или "R"; такие строки называются необработанными строками и используют
разные правила для escape-последовательностей с обратной косой чертой.
В строках с тройными кавычками
неэкранированные символы новой строки и кавычки разрешены (и сохраняются), за исключением
что три неэкранированных кавычки подряд завершают строку.(А
`` цитата '' - это символ, используемый для открытия строки, т. е. либо
' или ".)
Если не указан префикс `r 'или` R', escape-последовательности в строках
интерпретируются в соответствии с правилами, аналогичными
к тем, которые используются в Стандарте C. Распознанные escape-последовательности:
\ перевод строки | Игнорируется |
\ | Обратная косая черта ( \ ) |
\ ' | Одинарная кавычка ( ') |
\ " | Двойная кавычка ( ") |
\ а | Колокол ASCII (BEL) |
\ b | ASCII Backspace (BS) |
\ f | ASCII Formfeed (FF) |
\ п | ASCII перевод строки (LF) |
\ r | возврат каретки ASCII (CR) |
\ т | Горизонтальная вкладка ASCII (TAB) |
\ v | Вертикальная вкладка ASCII (VT) |
\ ооо | символ ASCII с восьмеричным значением ooo |
\ x чч... | символ ASCII с шестнадцатеричным значением hh ... |
В строгой совместимости со Стандартом C до трех восьмеричных цифр являются
принято, но неограниченное количество шестнадцатеричных цифр считается частью
шестнадцатеричный escape (а затем младшие 8 бит полученного шестнадцатеричного числа
используются в 8-битных реализациях).
В отличие от Standard C,
все нераспознанные escape-последовательности остаются в строке без изменений,
то есть в строке остается обратная косая черта. (Это поведение
полезно при отладке: если escape-последовательность ошибочна,
итоговый результат легче распознать как сломанный.)
Когда присутствует префикс `r 'или` R', обратная косая черта все еще используется для
процитируйте следующий символ, но все обратные косые черты оставлены в
строка . Например, строковый литерал r "\ n" состоит
из двух символов: обратная косая черта и строчная буква `n '. Строковые кавычки могут
экранировать обратную косую черту, но обратная косая черта остается в строке;
например, r "\" " - допустимый строковый литерал, состоящий из двух
символы: обратная косая черта и двойная кавычка; r "\" не является значением
строковый литерал (даже необработанная строка не может заканчиваться нечетным числом
обратная косая черта).В частности, необработанная строка не может заканчиваться одним
обратная косая черта (поскольку обратная косая черта не использовалась бы в следующей цитате
персонаж). Также обратите внимание, что одиночная обратная косая черта, за которой следует новая строка
интерпретируется как эти два символа как часть строки,
, а не как продолжение строки.
См. Об этом документе ... для получения информации о предложениях изменений.
Обработка разрывов строк в Python (создание, объединение, разделение, удаление, замена)
В этой статье описывается, как обрабатывать строки, включая разрывы строк (переводы строк, новые строки) в Python.
- Создать строку, содержащую разрывы строк
- Код новой строки
\ n(LF),\ r \ n(CR + LF) - Тройная цитата
'' 'или"" " - С отступом
- Код новой строки
- Объединить список строк в новые строки
- Разделить строку на список по разрывам строки:
splitlines () - Удалить или заменить разрывы строк
- Вывод с
print ()без конечной новой строки
Создать строку, содержащую разрывы строк
Код новой строки \ n (LF), \ r \ n (CR + LF)
Вставка кода новой строки \ n , \ r \ n в строку приведет к разрыву строки в этом месте.
s = 'Line1 \ nLine2 \ nLine3'
печать (и)
# Линия 1
# Line2
# Line3
s = 'Line1 \ r \ nLine2 \ r \ nLine3'
печать (и)
# Линия 1
# Line2
# Line3
В Unix, включая Mac, часто используется \ n (LF), а в Windows \ r \ n (CR + LF) часто используется как код новой строки. Некоторые текстовые редакторы позволяют выбрать код новой строки.
Тройная цитата '' ', "" "
Вы можете записать строку, включая разрывы строк, с тройными кавычками '' ' или "" ".
s = '' 'Строка1
Строка 2
Строка3 '' '
печать (и)
# Линия 1
# Line2
# Line3
С отступом
Если вы используете тройные кавычки и отступ, как показано ниже, будут вставлены ненужные пробелы.
с = '' '
Линия 1
Строка 2
Строка 3
'' '
печать (и)
#
# Линия 1
# Line2
# Line3
#
Заключив каждую строку в '' или "" и добавив разрыв строки \ n в конце и используя обратную косую черту \ , вы можете написать следующее:
s = 'Строка1 \ n' \
'Line2 \ n' \
'Line3'
печать (и)
# Линия 1
# Line2
# Line3
Он использует механизм конкатенации последовательных строковых литералов.Подробнее см. В следующей статье.
Если вы хотите добавить отступ в строке, добавьте пробел в строку в каждой строке.
s = 'Строка1 \ n' \
'Line2 \ n' \
'Line3'
печать (и)
# Линия 1
# Line2
# Line3
Поскольку вы можете свободно разбивать строки в круглых скобках () , вы также можете написать следующее, используя круглые скобки () без использования обратной косой черты \ .
s = ('Строка1 \ n'
'Line2 \ n'
'Line3')
печать (и)
# Линия 1
# Line2
# Line3
s = ('Строка1 \ n'
'Line2 \ n'
'Line3')
печать (и)
# Линия 1
# Line2
# Line3
Если вы просто хотите выровнять начало строки, вы можете просто добавить обратную косую черту \ к первой строке тройных кавычек.
s = '' '\
Линия 1
Строка 2
Строка3 '' '
печать (и)
# Линия 1
# Line2
# Line3
s = '' '\
Линия 1
Строка 2
Строка3 '' '
печать (и)
# Линия 1
# Line2
# Line3
Объединить список строк в новые строки
Вы можете использовать строковый метод join () , чтобы объединить список строк в одну строку.
При вызове join () из кода новой строки \ n или \ r \ n каждый элемент объединяется в новые строки.
l = [«Строка1», «Строка2», «Строка3»]
s_n = '\ n'.join (l)
печать (s_n)
# Линия 1
# Line2
# Line3
печать (repr (s_n))
# 'Line1 \ nLine2 \ nLine3'
s_rn = '\ r \ n'.join (l)
печать (s_rn)
# Линия 1
# Line2
# Line3
печать (repr (s_rn))
# 'Line1 \ r \ nLine2 \ r \ nLine3'
Как и в приведенном выше примере, вы можете проверить строку с неповрежденными кодами новой строки с помощью встроенной функции repr () .
Разделить строку на список по разрывам строки: splitlines ()
Строковый метод splitlines () может использоваться для разделения строки по разрывам строки в список.
s = 'Line1 \ nLine2 \ r \ nLine3'
печать (s.splitlines ())
# ['Line1', 'Line2', 'Line3']
В дополнение к \ n и \ r \ n , он также разделен на \ v (табуляция строк) или \ f (подача страницы) и т. Д.
См. Также следующую статью для получения дополнительной информации о splitlines () .
Удалить или заменить разрывы строк
С помощью splitlines () и join () вы можете удалить коды новой строки из строки или заменить ее другой строкой.
s = 'Line1 \ nLine2 \ r \ nLine3'
print (''. join (s.splitlines ()))
# Line1Line2Line3
print ('.join (s.splitlines ()))
# Line1 Line2 Line3
print (','. join (s.splitlines ()))
# Line1, Line2, Line3
Также можно сразу изменить код новой строки. Даже если код новой строки смешанный или неизвестный, вы можете разделить его на splitlines () , а затем объединить с желаемым кодом.
s_n = '\ n'.join (s.splitlines ())
печать (s_n)
# Линия 1
# Line2
# Line3
печать (repr (s_n))
# 'Line1 \ nLine2 \ nLine3'
Поскольку splitlines () разделяет как \ n (LF), так и \ r \ n (CR + LF), как упомянуто выше, вам не нужно беспокоиться о том, какой код новой строки используется в строке.
Вы также можете заменить код новой строки replace () .
s = 'Line1 \ nLine2 \ nLine3'
печать (s.replace ('\ n', ''))
# Line1Line2Line3
печать (s.replace ('\ n', ','))
# Line1, Line2, Line3
Однако обратите внимание, что он не будет работать, если он содержит код новой строки, отличный от ожидаемого.
s = 'Line1 \ nLine2 \ r \ nLine3'
s_error = s.replace ('\ п', ',')
печать (s_error)
#, Line3Line2
печать (repr (s_error))
# 'Line1, Line2 \ r, Line3'
s_error = s.replace ('\ r \ n', ',')
печать (s_error)
# Линия 1
# Line2, Line3
печать (repr (s_error))
# 'Line1 \ nLine2, Line3'
Вы можете повторить replace () , чтобы заменить несколько кодов новой строки, но \ r \ n содержит \ n , это не сработает, если вы сделаете это в неправильном порядке. Как упоминалось выше, использование splitlines (), и join () безопасно, потому что вам не нужно беспокоиться о кодах перевода строки.
s = 'Line1 \ nLine2 \ r \ nLine3'
печать (s.replace ('\ r \ n', ','). replace ('\ n', ','))
# Line1, Line2, Line3
s_error = s.replace ('\ n', ','). replace ('\ r \ n', ',')
печать (s_error)
#, Line3Line2
печать (repr (s_error))
# 'Line1, Line2 \ r, Line3'
print (','. join (s.splitlines ()))
# Line1, Line2, Line3
Вы можете использовать rstrip () для удаления завершающего кода новой строки.
s = 'ааа \ п'
печать (s + 'bbb')
# ааа
# bbb
печать (s.rstrip () + 'bbb')
# aaabbb
Вывод с print () без символа новой строки в конце
По умолчанию print () добавляет в конец новую строку.Следовательно, если вы выполняете print () непрерывно, каждый результат вывода будет отображаться с разрывом строки.
печать ('а')
печать ('b')
печать ('c')
# а
# б
# c
Это связано с тем, что значение по умолчанию аргумента end для print () , которое определяет строку символов, которая должна быть добавлена в конце, составляет '\ n' .
Если пустая строка '' указана в end , разрыв строки в конце не произойдет.
печать ('а', конец = '')
печать ('б', конец = '')
печать ('c', конец = '')
# abc
Любая строка может быть указана в конце .
print ('a', end = '-')
print ('b', конец = '-')
печать ('c')
# a-b-c
Однако, если вы хотите объединить строки символов и вывод, проще объединить исходные строки символов. См. Следующую статью.
Добавить символ новой строки в Python - 6 простых способов!
Привет, ребята! Надеюсь, у вас все хорошо.В этой статье мы представим . Различные способы добавления символа новой строки в Python (\ n) к выходным данным для печати .
Итак, приступим!
Метод 1. Добавление символа новой строки в многострочную строку
Многострочная строка Python обеспечивает эффективный способ представления нескольких строк выровненным образом. В многострочную строку можно добавить символ новой строки (\ n), как показано ниже -
Синтаксис:
строка = '' 'str1 \ nstr2.... \ nstrN '' '
Мы можем легко использовать «\ n» перед каждой строкой, которую мы хотим отобразить на новой строке в многострочной строке.
Пример:
str = '' 'Всем привет !! \ nЯ Pythoner \ nДобро пожаловать в учебник AskPython '' ' печать (str)
Выход:
Всем привет!! Я питонист Добро пожаловать в учебное пособие AskPython
Метод 2: Добавление новой строки в список Python
Список Python можно рассматривать как динамический массив, который сохраняет в нем разнородные элементы во время динамического выполнения.
Функцию string.join () можно использовать для добавления новой строки среди элементов списка, как показано ниже -
Синтаксис:
Пример :
lst = ['Python', 'Java', 'Kotlin', 'Cpp']
print ("Список перед добавлением в него символа новой строки:", lst)
lst = '\ n'.join (lst)
print ("Список после добавления к нему символа новой строки: \ n", lst)
Выход:
Перечислить перед добавлением в него символа новой строки: ['Python', 'Java', 'Kotlin', 'Cpp'] Список после добавления к нему символа новой строки: Python Ява Котлин Cpp
Метод 3: Отображение новой строки на консоли
На самом начальном этапе важно знать выполнение функций на консоли.Чтобы добавить новую строку в консоль, используйте следующий код -
Пример:
Python newline с консолью
Метод 4: Отображение новой строки с помощью оператора печати
Символ новой строки может быть добавлен в функцию print () для отображения строки на новой строке, как показано ниже -
Синтаксис:
print ("str1 \ nstr2 \ n ... \ strN")
Пример:
print ("Здравствуйте, народ! Давайте начнем учиться.")
print ("Оператор после добавления новой строки с помощью функции print () ....")
print ("Здравствуйте, народ! \ nДавайте приступим к обучению.")
Выход:
Привет, народ! Начнем учиться. Оператор после добавления новой строки с помощью функции print () .... Привет, народ! Начнем учиться.
Метод 5: Добавление символа новой строки через f-строку Python
f-строка Python также представляет строковые операторы в отформатированном виде на консоли. Чтобы добавить символ новой строки через f-строку, следуйте синтаксису ниже:
новая строка = '\ п'
строка = f "str1 {новая строка} str2"
Пример:
новая строка = '\ п'
str = f "Python {newline} Java {newline} Cpp"
печать (str)
Вывод:
Метод 6: Запись новой строки в файл
Символ новой строки может быть добавлен к файлу Python, используя следующий синтаксис:
Синтаксис:
Пример:
Здесь мы использовали Python.txt с предварительно определенным содержимым, как показано ниже -
Python Text-file
импорт ОС
file = "/Python.txt"
с open (file, 'a') как файл:
file.write ("\ n")
Вывод:
Как видно ниже, к содержимому файла добавляется новая строка.
Добавить новую строку в файл Python
Заключение
На этом мы подошли к концу этой темы. Не стесняйтесь комментировать ниже, если у вас возникнут какие-либо вопросы.
До тех пор, удачного обучения !!
Ссылки
Как новая строка обрабатывается в Python и различных редакторах?
Каждый программист знает символ новой строки, но может быть не так знаком.В этом
пост, я хочу поделиться тем, что я узнал об обработке новой строки в различных
случаи.
По историческим причинам на разных платформах используются разные персонажи для
означает новую строку. В Windows (байтовый код 0x0D0x0A ) используется для
представляют новую строку. В Linux (байт-код 0x0A ) используется для представления
новая линия. На старых Mac используется (байт-код 0x0D ).
и восходят к старым временам, когда пишущие машинки использовались для
печать текстов на бумаге. представляет собой возврат каретки , что означает
переместите каретку в крайнее левое положение. представляет перевод строки ,
что означает переместить бумагу немного выше, чтобы вы могли печатать на новом
линия. Вы можете видеть, что эти два действия вместе начнут готовую новую строку.
для набора текста.
Python 2 и Python 3 по-разному обрабатывают символы новой строки. В Python 2
есть универсальный перевод строки
режим, который
означает, что независимо от того, чем заканчивается строка файла, все это будет переведено на
\ n при чтении файлов со спецификатором режима rU .
В Python 3 все изменилось. Старый спецификатор режима U был
устарело в пользу параметра новой строки в методе open () . В соответствии
к документации:
newline определяет, как работает универсальный режим новой строки (применяется только к текстовому режиму). Это может быть None, ‘’, ‘\ n’, ‘\ r’ и ‘\ r \ n’. Он работает следующим образом:
- При чтении ввода из потока, если символ новой строки отсутствует, включается универсальный режим новой строки. Строки во входных данных могут заканчиваться на «\ n», «\ r» или «\ r \ n», и они переводятся в «\ n» перед возвратом вызывающей стороне.Если это «», то включен универсальный режим новой строки, но окончания строк возвращаются вызывающей стороне в непереведенном виде.
- При записи вывода в поток, если новая строка имеет значение Нет, любые записанные символы «\ n» переводятся в системный разделитель строк по умолчанию,
os.linesep. Если новая строка - "" или "\ n", перевод не выполняется.
при чтении текстовых файлов новая строка по умолчанию Нет , что означает, что
системно-зависимая новая строка будет незаметно заменена на \ n .Если вы не в курсе
из-за такого поведения у вас могут возникнуть проблемы. Например, когда вы читаете файл
с окончанием строки \ r \ n и хотите разбить текст на строки в Windows
платформа, если вы используете следующий фрагмент:
с open ("some_file.txt", "r") как f:
текст = f.read ()
lines = text.split (os.linesep)
у вас не получится разбить текст на строки. Это потому, что в Windows
платформа, os.linesep is \ r \ n . Но Python тайно перевел \ r \ n
в файле на \ n !
При записи файлов вы также должны знать, что \ n будет переведен на
зависящие от платформы окончания строк.
Vim
При чтении файла в буфер Vim автоматически обнаружит файл
формат . Затем Vim заменит зависящие от платформы символы новой строки
специальной меткой для обозначения конца каждой строки. При записи буфера
содержимое обратно в файл, Vim запишет фактические символы новой строки на основе
об обнаруженном формате файла.
Например, если вы откроете файл с окончанием строки в стиле Windows, Vim будет
заменить все на собственный знак новой строки.Если вы попытаетесь найти эти
два символа с использованием их байтового кода ( \% x0A для и \% x0D для
), вы ничего не найдете. Вы также не можете найти символов, используя \ r в
Файл Windows в Vim (предположим, что файловых форматов включают dos ). При поиске в
Vim, \ n используется для указания конца строки, независимо от того, какой на самом деле символ новой строки
символ для этого файла. Таким образом, вы можете искать конец строки с помощью \ n .M . Ты сможешь
увидеть это сейчас.
Вы также можете нажать , а затем нажать , чтобы ввести каретку
символ возврата. Затем вы можете выполнить поиск этого символа, используя \ r .
Ловушка при поиске и замене новой строки
В Vim, \ n используется для представления новой строки только тогда, когда вы ее ищете. Если
если вы хотите заменить новую строку, используйте \ r вместо . Этот
не имеет смысла, но именно так работает Vim.
Sublime Text
Согласно обсуждениям
здесь,
Sublime Text также преобразует платформенно-зависимую новую строку в \ n в памяти.
При записи в файлы он будет писать новые строки на основе обнаруженного типа файла.
(Windows, Unix или Mac).
Notepad ++
Notepad ++ также является популярным редактором кода. Это
может определить окончания вашей строки, но не заменит новую строку на \ n . К
показать символы новой строки в файле, перейти к View -> Show Symbol и переключить
на опции Показать конец строки вы сможете увидеть символы новой строки.
В Vim вы можете использовать set ff = , чтобы преобразовать текущий файл в желаемый.
формат, где может быть unix , dos или mac .
В Sublime Text просто выберите нужный формат в правом нижнем углу.
бар.
В Notepad ++ перейдите в Edit -> EOL Conversion и выберите нужный файл
формат.
Существуют также такие инструменты, как dos2unix и
unix2dos , которые конвертируют
между разными форматами файлов.
Название изображения взято отсюда.
На этой странице: комментирование с #, многострочные строки с "" "" "", печать нескольких объектов, обратная косая черта "\" в качестве escape-символа, '\ t', '\ n', '\ r' и '\\'. Начать
Сводка видео
Узнать больше
Изучить |
Тайный мир персонажей новой строки | Ян Ян | Enigma Engineering
Исправляя недавнюю регрессию в приеме CSV-файлов Enigma Public (несколько совершенно хороших CSV-файлов теперь отклонялись), я наткнулся на некоторые любопытные несоответствия между идиомами Python для обработки символов новой строки.Это привело меня в кроличью нору компьютерной истории и в мир экзотических особенностей новой строки, настолько захватывающих, что, по предложению моей коллеги Евы, я решил, что стоит поделиться ими.
Первое, что нужно знать о новых строках, это то, что даже в повседневных вычислениях они имеют много представлений символов. Каждая из трех традиционных операционных систем использует разные:
\ n : стиль Unix и Linux,
\ r \ n : стиль Microsoft Windows и
\ r : несколько более редкий классический MacOS style,
, где \ n и \ r - обычные управляющие последовательности для символов ASCII Line Feed (LF) и возврата каретки (CR), соответственно.Уже сейчас следует задаться вопросом, почему в стиле Windows используются два символа, в то время как другие обходятся только одним. Фактически это возвращает нас к соглашению о пишущей машинке, в котором новая строка включает в себя два действия: возвращение каретки в левую сторону и перемещение бумаги на одну строку.
Эти три последовательности ASCII учитывают символы новой строки почти во всех текстовых документах, особенно среди тех, которые вы можете отправить по электронной почте или загрузить из Интернета. Таким образом, несмотря на периодические сбой, современное кроссплатформенное программное обеспечение довольно хорошо обрабатывает символы новой строки, и Python не является исключением.Он имеет концепцию универсальных новых строк, которая относится ко всем вариантам с равенством. Кроме того, документация для программы чтения CSV Python рекомендует единственный предпочтительный способ работы с универсальными символами новой строки.
Иногда Python пытается быть более полезным. Предположим, у вас есть многострочная строка, которую необходимо разбить, где бы ни встречались символы новой строки, на несколько строк. К счастью, для этого есть функция с метко названным str.splitlines , которую вы вызываете, и вот, все просто работает.Итак, вы отправляете строки в программу чтения CSV, которая предпочитает получать отдельные строки одну за другой, и все просто работает. И, кстати, Requests (легко входит в пятерку наиболее широко используемых библиотек Python) также вызывает эту функцию, когда вы запрашиваете строки, и все просто работает.
Затем в один прекрасный день все не работает, и в этот момент вы дважды проверяете документацию и понимаете, что str.splitlines имеет свои собственные представления о том, что может быть новой строкой:
\ n Line Feed (LF)
\ r Возврат каретки (CR)
\ r \ n Возврат каретки + перевод строки (CR + LF)
\ x0b Таблица строк (VT)
\ x0c Подача формы (FF)
\ x1c Разделитель файлов (FS)
\ x1d Разделитель групп ( GS)
\ x1e Разделитель записей (RS)
\ x85 Следующая строка (NEL)
\ u2028 Разделитель строк (LS)
\ u2029 Разделитель абзацев (PS)
Посмотрите, три могут быть или не могут быть приемлемым количеством вариантов новой строки , но одиннадцать - это определенно, однозначно слишком много.