1251 кодировка: html — Отличие кодировки windows-1251 от utf-8
Содержание
Таблица Windows-1251
Windows-1251 (cp1251) — это стандартная 8-битная кодировка, разработанная компанией Microsoft. Она содержит практически все символы, которые Вы можете встретить на стандартной русской клавиатуре. Также 1251 имеет символы для таких языков, как белорусский, украинский, болгарский и сербский.
DEC | HEX | СИМВ | DEC | HEX | СИМВ | DEC | HEX | СИМВ |
000 | 00 | NOP | 086 | 56 | V | 171 | AB | « |
001 | 01 | SOH | 087 | 57 | W | 172 | AC | ¬ |
002 | 02 | STX | 088 | 58 | X | 173 | AD | |
003 | 03 | ETX | 089 | 59 | Y | 174 | AE | ® |
004 | 04 | EOT | 090 | 5A | Z | 175 | AF | Ї |
005 | 05 | ENQ | 091 | 5B | [ | 176 | B0 | ° |
006 | 06 | ACK | 092 | 5C | \ | 177 | B1 | ± |
007 | 07 | BEL | 093 | 5D | ] | 178 | B2 | І |
008 | 08 | BS | 094 | 5E | ^ | 179 | B3 | і |
009 | 09 | Табуляция | 095 | 5F | _ | 180 | B4 | ґ |
010 | 0A | LF | 096 | 60 | ` | 181 | B5 | µ |
011 | 0B | VT | 097 | 61 | a | 182 | B6 | ¶ |
012 | 0C | FF | 098 | 62 | b | 183 | B7 | · |
013 | 0D | CR | 099 | 63 | c | 184 | B8 | Ё |
014 | 0E | SO | 100 | 64 | d | 185 | B9 | № |
015 | 0F | SI | 101 | 65 | e | 186 | BA | Є |
016 | 10 | DLE | 102 | 66 | f | 187 | BB | » |
017 | 11 | DC1 | 103 | 67 | g | 188 | BC | ј |
018 | 12 | DC2 | 104 | 68 | h | 189 | BD | Ѕ |
019 | 13 | DC3 | 105 | 69 | i | 190 | BE | Ѕ |
020 | 14 | DC4 | 106 | 6A | j | 191 | BF | Ї |
021 | 15 | NAK | 107 | 6B | k | 192 | C0 | А |
022 | 16 | SYN | 108 | 6C | l | 193 | C1 | Б |
023 | 17 | ETB | 109 | 6D | m | 194 | C2 | В |
024 | 18 | CAN | 110 | 6E | n | 195 | C3 | Г |
025 | 19 | EM | 111 | 6F | o | 196 | C4 | Д |
026 | 1A | SUB | 112 | 70 | p | 197 | C5 | Е |
027 | 1B | ESC | 113 | 71 | q | 198 | C6 | Ж |
028 | 1C | FS | 114 | 72 | r | 199 | C7 | З |
029 | 1D | GS | 115 | 73 | s | 200 | C8 | И |
030 | 1E | RS | 116 | 74 | t | 201 | C9 | Й |
031 | 1F | US | 117 | 75 | u | 202 | CA | К |
032 | 20 | Пробел | 118 | 76 | v | 203 | CB | Л |
033 | 21 | ! | 119 | 77 | w | 204 | CC | М |
034 | 22 | « | 120 | 78 | x | 205 | CD | Н |
035 | 23 | # | 121 | 79 | y | 206 | CE | О |
036 | 24 | $ | 122 | 7A | z | 207 | CF | П |
037 | 25 | % | 123 | 7B | { | 208 | D0 | Р |
038 | 26 | & | 124 | 7C | | | 209 | D1 | С |
039 | 27 | ‘ | 125 | 7D | } | 210 | D2 | Т |
040 | 28 | ( | 126 | 7E | ~ | 211 | D3 | У |
041 | 29 | ) | 127 | 7F | | 212 | D4 | Ф |
042 | 2A | * | 128 | 80 | Ђ | 213 | D5 | Х |
043 | 2B | + | 129 | 81 | Ѓ | 214 | D6 | Ц |
044 | 2C | , | 130 | 82 | ‚ | 215 | D7 | Ч |
045 | 2D | — | 131 | 83 | ѓ | 216 | D8 | Ш |
046 | 2E | . | 132 | 84 | „ | 217 | D9 | Щ |
047 | 2F | / | 133 | 85 | … | 218 | DA | Ъ |
048 | 30 | 0 | 134 | 86 | † | 219 | DB | Ы |
049 | 31 | 1 | 135 | 87 | ‡ | 220 | DC | Ь |
050 | 32 | 2 | 136 | 88 | € | 221 | DD | Э |
051 | 33 | 3 | 137 | 89 | ‰ | 222 | DE | Ю |
052 | 34 | 4 | 138 | 8A | Љ | 223 | DF | Я |
053 | 35 | 5 | 139 | 8B | ‹ | 224 | E0 | а |
054 | 36 | 6 | 140 | 8C | Њ | 225 | E1 | б |
055 | 37 | 7 | 141 | 8D | Ќ | 226 | E2 | в |
056 | 38 | 8 | 142 | 8E | Ћ | 227 | E3 | г |
057 | 39 | 9 | 143 | 8F | Џ | 228 | E4 | д |
058 | 3A | : | 144 | 90 | Ђ | 229 | E5 | е |
059 | 3B | ; | 145 | 91 | ‘ | 230 | E6 | ж |
060 | 3C | < | 146 | 92 | ’ | 231 | E7 | з |
061 | 3D | = | 147 | 93 | “ | 232 | E8 | и |
062 | 3E | > | 148 | 94 | ” | 233 | E9 | й |
063 | 3F | ? | 149 | 95 | • | 234 | EA | к |
064 | 40 | @ | 150 | 96 | – | 235 | EB | л |
065 | 41 | A | 151 | 97 | — | 236 | EC | м |
066 | 42 | B | 152 | 98 | 237 | ED | н | |
067 | 43 | C | 153 | 99 | ™ | 238 | EE | о |
068 | 44 | D | 154 | 9A | љ | 239 | EF | п |
069 | 45 | E | 155 | 9B | › | 240 | F0 | р |
070 | 46 | F | 156 | 9C | њ | 241 | F1 | с |
071 | 47 | G | 157 | 9D | ќ | 242 | F2 | т |
072 | 48 | H | 158 | 9E | ћ | 243 | F3 | у |
073 | 49 | I | 159 | 9F | џ | 244 | F4 | ф |
074 | 4A | J | 160 | A0 | 245 | F5 | х | |
075 | 4B | K | 161 | A1 | Ў | 246 | F6 | ц |
076 | 4C | L | 162 | A2 | ў | 247 | F7 | ч |
077 | 4D | M | 163 | A3 | Ј | 248 | F8 | ш |
078 | 4E | N | 164 | A4 | ¤ | 249 | F9 | щ |
079 | 4F | O | 165 | A5 | Ґ | 250 | FA | ъ |
080 | 50 | P | 166 | A6 | ¦ | 251 | FB | ы |
081 | 51 | Q | 167 | A7 | § | 252 | FC | ь |
082 | 52 | R | 168 | A8 | Ё | 253 | FD | э |
083 | 53 | S | 169 | A9 | © | 254 | FE | ю |
084 | 54 | T | 170 | AA | Є | 255 | FF | я |
085 | 55 | U |

Похожие записи:
Кодировка windows 1251 в сайтостроении
Кодировка windows 1251 была создана в начале 90 годов для русификации программных продуктов, выпускаемых корпорацией Microsoft:
Кодировка является 8-битной и включает в себя символы славянской группы языков, в которую входят русский, белорусский, украинский, болгарский, македонский, сербский – это дает преимущество перед остальными кириллическими кодировками (ISO 8859-5, KOI8-R, CP866). Однако у 1251-кодировки имеются и весомые недостатки:
Однако у 1251-кодировки имеются и весомые недостатки:
- 0xFF (25510) – это код, который зарезервирован для символа «я». В программах, которые не поддерживают чистый 8-ой бит, часто возникают непредсказуемые проблемы;
- Нет псевдографики, которая присутствует в KOI8, CP866.
Ниже приведены символы из Code Page 1251 или сокращенно СР1251 (числа под символами являются кодом в шестнадцатеричной системе такого же символа в Юникоде):
Нередко у web-разработчиков и блогеров, обладающих различной квалификацией возникает проблема с кодировкой страниц: вместо подготовленного текста появляются неизвестные, нечитаемые символы. Чтобы разобраться с данной проблемой, необходимо понимать суть термина «кодировка страницы».
Текст в памяти компьютера хранится в виде определенного количества байт, а не в том виде, в котором он отображается в текстовом редакторе. Каждый байт является кодом, который соответствует одному символу. Для того чтобы текст на странице отображался как следует, нужно сообщить браузеру, какую таблицу кодов для расшифровки и отображения он должен использовать.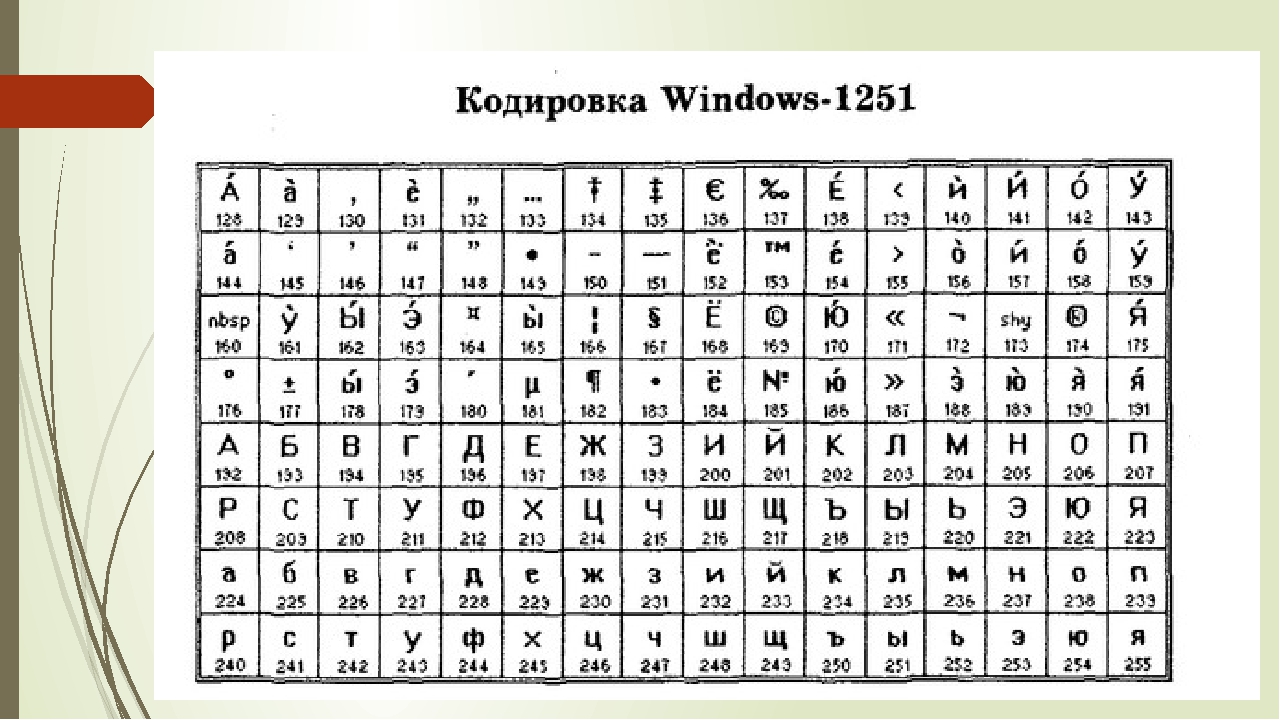
Таблица кодировок не является универсальной, то есть, для расшифровки текста необходимо использовать ту, которая соответствует кодировке символов:
Для того чтобы html-документ корректно отобразился в браузере, необходимо указать используемую кодировку. Делается это следующим образом:
— между тегом <head> и закрывающим его </head> нужно прописать <meta http-equiv=»Content-Type» content=»text/html; charset=windows-1251″> — исходя из этой строки, браузер будет использовать символы русского алфавита для отображения текста на странице.
Ни для кого не является тайной, что генерация страниц проходит путем выборки и использования какой-то части информации, которая хранится в базе данных. При написании сайта на PHP, чаще всего это mysql:
Нередко при смене хостинга возникает проблема: различные кодировки информации в базе данных и в шаблонах страниц. Из-за этого одна сгенерированная страница может одновременно содержать несколько кодировок. Если информация на сайте представлена в кодировке виндовс 1251, то и чтение из базы данных должно осуществляться с помощью таблицы, в которой представлена win 1251 кодировка.
Для согласования расшифровки необходимо выполнить функцию mysql_query(«SET NAMES cp1251») – это означает, что преобразование из машинного кода будет осуществляться согласно таблице cp1251.
При создании сайта, предварительно настроив кодировки в шаблонах и базах данных, все равно может всплыть проблема некорректного отображения информации в браузере.
Для того чтобы для веб-ресурса была задана кодировка виндовс-1251, необходимо найти (или создать) файл .htaccess. Это файл, который хранит в себе дополнительные настройки и описания конфигураций web-сервера.
В нем для установки кодировки следует прописать следующие строки:
- DefaultLanguage ru;
- AddDefaultCharset windows-1251;
- php_value default_charset «cp1251».
Таким образом, для корректного отображения текста должны совпадать его кодировка и таблица кодов, с помощью которой браузер будет расшифровывать символы. Для текстов, написанных на славянских языках, необходима win 1251 кодировка. Важно помнить, что элементы страниц и баз данных должны быть описаны с помощью одной таблицы кодов.
Важно помнить, что элементы страниц и баз данных должны быть описаны с помощью одной таблицы кодов.
Как настроить кодировку сайта самостоятельно
Как кодировка влияет на отображение сайта, чем отличается UTF-8 от Windows 1251 и где указать кодировку.
Разбираем, на что влияет кодировка, нужно ли указывать ее самостоятельно, и почему могут появиться так называемые «кракозябры» на сайте.
Зачем нужна кодировка
Кодировка (Charset) — способ отображения кода на экране, соответствие набора символов набору числовых значений. О ней сообщает строка Content-Type и сервер в header запросе.
Несовпадение кодировок сервера и страницы будет причиной появления ошибок. Если они не совпадают, информация декодируется некорректно, так что контент на сайте будет отображаться в виде набора бессвязных букв, иероглифов и символов, в народе называемых «кракозябрами». Такой текст прочитать невозможно, так что пользователь просто уйдет с сайта и найдет другой ресурс. Или останется, если ему не очень важно содержание:
Или останется, если ему не очень важно содержание:
Студентка списывала реферат с формулами, а на сайте слетела кодировка. Реальная история
Google рекомендует всегда указывать сведения о кодировке, чтобы текст точно корректно отображался в браузере пользователя.
Кодировка влияет на SEO?
Разберемся, как кодировка на сайте влияет на индексацию в Яндекс и Google.
Яндекс четко заявляет:
«Тип используемой на сайте кодировки не влияет на индексирование сайта. Если ваш сервер не передает в заголовке кодировку, робот Яндекса также определит ее самостоятельно».
Позиция Google такая же. Поисковики не рассматривают Charset как фактор ранжирования или сигнал для индексирования, тем не менее, она косвенно влияет на трафик и позиции.
Если кодировка сервера не совпадает с той, что указана на сайте, пользователи увидят нечитабельные символы вместо контента. На таком сайте сложно что-либо понять, так что скорее всего пользователи сбегут, а на сайте будут расти отказы.
Пример страницы со слетевшей кодировкой
Поэтому она важна для SEO, хоть и влияет на него косвенно через поведенческие. Пользователи должны видеть читабельный текст на человеческом языке, чтобы работать с сайтом.
Виды кодировок
Существует довольно много видов, но сейчас распространены два:
UTF-8
Unicode Transformation Format — универсальный стандарт кодирования, который работает с символами почти всех языков мира. Символы могут занимать от 1 до 4 байт, такое кодирование позволяет создавать мультиязычные сайты.
Есть несколько вариантов — UTF-8, 16, 32, но чаще используют восьмибитное.
Windows-1251
Этот вид занимает второе место по популярности после UTF-8. Windows-1251 — кодирование для кириллицы, созданное на базе кодировок, использовавшихся в русификаторах операционной системы Windows. В ней есть все символы, которые используются в русской типографике, кроме значка ударения. Символы занимают 1 байт.
Выбор кодировки остается на усмотрение веб-мастера, но UTF-8 используют намного чаще — ее поддерживают все популярные браузеры и распознают поисковики, а еще ее удобнее использовать для сайтов на разных языках.
Определить кодировку страницы своего или чужого сайта можно через исходный код страницы. Откройте страницу сайта, выберите «Просмотр кода страницы» (сочетание горячих клавиш Ctrl+U» в Google Chrome) и найдите упоминание «charset» внутри тега head.
На странице сайта используется кодировка UTF-8:
Указание кодировки в коде страницы
Узнать вид кодирования можно с помощью «Анализа сайта». Сервис проверяет в том числе и техническую сторону ресурса: анализирует серверную информацию, определяет кодировку, проверяет редиректы и другие пункты.
Фрагмент анализа серверной информации сайта
С помощью этого же сервиса можно проверить корректность указанного кодирования. Аудит внутренних страниц «Анализа сайта» проверяет кодировку сервера и сравнивает ее с той, которая указана на внутренней странице. Найденные ошибки Анализ покажет в результатах проверки, и вы сразу узнаете, где нужно исправить.
Отчет о технических данных
Кодировка сервера и страницы
Проверить кодировку еще можно через сервис Validator. w3, о котором писали в статье о проверке валидации кода. Нужная надпись находится внизу страницы.
w3, о котором писали в статье о проверке валидации кода. Нужная надпись находится внизу страницы.
Кодировка сайта в валидаторе
Если валидатор не обнаружит Charset, он покажет ошибку:
Ошибка указания кодировки
Но валидатор работает не точно: он проверяет только синтаксис разметки, поэтому может не показать ошибку, даже если кодирование указано неправильно.
Если кодировка не отображается
Если вы зашли на чужой сайт с абракадаброй, а вам все равно очень интересно почитать контент, то в Справке Google объясняют, как исправить кодирование текста через браузер.
О проблеме возникновения абракадабры на вашем сайте будут сигнализировать метрики поведения: вырастут отказы, уменьшится глубина просмотров. Но скорее всего вы и раньше заметите, что что-то пошло не так.
Главное правило — для всех файлов, скриптов, баз данных сайта и сервера должна быть указана одна кодировка. Ошибка может возникнуть, если вы случайно указали на сайте разные виды кодировки.
Яндекс советует использовать одинаковую кодировку для страниц и кириллических адресов структуры. К примеру, если робот встретит ссылку href=»/корзина» на странице с кодировкой UTF-8, он сохранит ее в этом же UTF-8, так что страница должна быть доступна по адресу «/%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0».
Где указать кодировку сайта
Если проблема возникла на вашем сайте, способ исправления зависит от вида сайта. Для одностраничника достаточно указать кодировку в мета-теге страницы, а для большого сайта есть разные варианты:
- кодировка в мета-теге;
- кодировка в .htaccess;
- кодировка документа;
- кодировка в базе данных MySQL.
Кодировка в мета-теге
Добавьте указание кодировки в head файла шаблона сайта.
При создании документа HTML укажите тег meta в начале в блоке head. Некоторые браузеры могут не распознать указание кодировки, если оно будет ниже.
Мета-тег может выглядеть так:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">или так:
<meta charset="utf-8">В HTML5 они эквивалентны.
Тег кодировки в HTML
В темах WordPress обычно тег «charset» с кодировкой указан по умолчанию, но лучше проверить.
Кодировка в файле httpd.conf
Инструкции для сервера находятся в файле httpd.conf, обычно его можно найти на пути «/usr/local/apache/conf/».
Если вам нужно сменить кодировку Windows-1251 на UTF-8, замените строчку «AddDefaultCharset windows-1251» на «AddDefaultCharset utf-8».
Осторожнее: если вы измените в файле кодировку по умолчанию, то она изменится для всех проектов на этом сервере.
Убедитесь, что сервер не передает HTTP-заголовки с конфликтующими кодировками.
Кодировка в .htaccess
Добавьте кодировку в файл .htaccess:
- Откройте панель управления хостингом.
- Перейдите в корневую папку сайта.
- В файле .htaccess добавьте в самое начало код:
- для указания кодировки UTF-8 — AddDefaultCharset UTF-8;
- для указания кодировки Windows-1251 — AddDefaultCharset WINDOWS-1251.

- Перейдите на сайт и очистите кэш браузера.
Кодировка документа
Готовые файлы HTML важно сохранять в нужной кодировке сайта. Узнать текущую кодировку файла можно через Notepad++: откройте файл и зайдите в «Encoding». Меняется она там же: чтобы сменить кодировку на UTF-8, выберите «Convert to UTF-8 without BOOM». Нужно выбрать «без BOOM», чтобы не было пустых символов.
Кодировка Базы данных
Выбирайте нужную кодировку сразу при создании базы данных. Распространенный вариант — «UTF-8 general ci».
Где менять кодировку у БД:
- Кликните по названию нужной базы в утилите управления БД phpMyAdmin и откройте ее.
- Кликните на раздел «Операции»:
- Введите нужную кодировку для базы данных MySQL:
- Перейдите на сайт и очистите кэш.
С новой БД проще, но если вы меняете кодировку у существующей базы, то у созданных таблиц и колонок заданы свои кодировки, которые тоже нужно поменять.
Для всех таблиц, колонок, файлов, сервера и вообще всего, что связано с сайтом, должна быть одна кодировка.
Проблема может не решиться, если все дело в кодировке подключения к базе данных. Что делать:
- Подключитесь к серверу с правами mysql root пользователя:
mysql -u root -p - Выберите нужную базу:
USE имя_базы; - Выполните запрос:
SET NAMES ‘utf8’;
Если вы хотите указать Windows-1251, то пишите не «utf-8», а «cp1251» — обозначение для кодировки Windows-1251 у MySQL.
Чтобы установить UTF-8 по умолчанию, откройте на сервере my.cnf и добавьте следующее:
В области [client]:
default-character-set=utf8
В области [mysql]:
default-character-set=utf8
В области [mysqld]:
collation-server = utf8_unicode_ci
init-connect='SET NAMES utf8'
character-set-server = utf8Вы когда-нибудь сталкивались с проблемами кодировки на сайте?
Таблица ASCII (кодировка Windows-1251)
Таблица ASCII (кодировка Windows-1251)
| (0) | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | (10) | (11) | (12) | (13) | (14) | (15) | (16) |
| (17) | (18) | (19) | (20) | (21) | (22) | (23) | (24) | (25) | (26) | (27) | (28) | (29) | (30) | (31) | (32) | !(33) |
| «(34) | #(35) | $(36) | %(37) | &(38) | ‘(39) | ((40) | )(41) | *(42) | +(43) | ,(44) | —(45) | . (46) (46) | /(47) | 0(48) | 1(49) | 2(50) |
| 3(51) | 4(52) | 5(53) | 6(54) | 7(55) | 8(56) | 9(57) | :(58) | ;(59) | (60) | =(61) | >(62) | ?(63) | @(64) | A(65) | B(66) | C(67) |
| D(68) | E(69) | F(70) | G(71) | H(72) | I(73) | J(74) | K(75) | L(76) | M(77) | N(78) | O(79) | P(80) | Q(81) | R(82) | S(83) | T(84) |
| U(85) | V(86) | W(87) | X(88) | Y(89) | Z(90) | [(91) | \ (92) | ](93) | ^(94) | _(95) | `(96) | a(97) | b(98) | c(99) | d(100) | e(101) |
| f(102) | g(103) | h(104) | i(105) | j(106) | k(107) | l(108) | m(109) | n(110) | o(111) | p(112) | q(113) | r(114) | s(115) | t(116) | u(117) | v(118) |
| w(119) | x(120) | y(121) | z(122) | {(123) | |(124) | }(125) | ~(126) | (127) | Ђ(128) | Ѓ(129) | ‚(130) | ѓ(131) | „(132) | …(133) | †(134) | ‡(135) |
| €(136) | ‰(137) | Љ(138) | ‹(139) | Њ(140) | Ќ(141) | Ћ(142) | Џ(143) | ђ(144) | ‘(145) | ’(146) | “(147) | ”(148) | •(149) | –(150) | —(151) | (152) |
| ™(153) | љ(154) | ›(155) | њ(156) | ќ(157) | ћ(158) | џ(159) | (160) | Ў(161) | ў(162) | Ј(163) | ¤(164) | Ґ(165) | ¦(166) | §(167) | Ё(168) | ©(169) |
| Є(170) | «(171) | ¬(172) | (173) | ®(174) | Ї(175) | °(176) | ±(177) | І(178) | і(179) | ґ(180) | µ(181) | ¶(182) | ·(183) | ё(184) | №(185) | є(186) |
| »(187) | ј(188) | Ѕ(189) | ѕ(190) | ї(191) | А(192) | Б(193) | В(194) | Г(195) | Д(196) | Е(197) | Ж(198) | З(199) | И(200) | Й(201) | К(202) | Л(203) |
| М(204) | Н(205) | О(206) | П(207) | Р(208) | С(209) | Т(210) | У(211) | Ф(212) | Х(213) | Ц(214) | Ч(215) | Ш(216) | Щ(217) | Ъ(218) | Ы(219) | Ь(220) |
| Э(221) | Ю(222) | Я(223) | а(224) | б(225) | в(226) | г(227) | д(228) | е(229) | ж(230) | з(231) | и(232) | й(233) | к(234) | л(235) | м(236) | н(237) |
| о(238) | п(239) | р(240) | с(241) | т(242) | у(243) | ф(244) | х(245) | ц(246) | ч(247) | ш(248) | щ(249) | ъ(250) | ы(251) | ь(252) | э(253) | ю(254) |
| я(255) | (256) | (257) | (258) | (259) | (260) | (261) | (262) | (263) | (264) | (265) | (266) | (267) | (268) | (269) | (270) | (271) |
— версия для печати
- Определение
- ASCII (англ. American Standard Code for Information Interchange) — американская стандартная таблица для кодирования печатных символов и некоторых специальных кодов.
 American Standard Code for Information Interchange) — американская стандартная таблица для кодирования печатных символов и некоторых специальных кодов.
American Standard Code for Information Interchange) — американская стандартная таблица для кодирования печатных символов и некоторых специальных кодов.| Если у вас есть мысли по поводу данной страницы или предложение по созданию математической (см. раздел «Математика») вспомогательной памятки, мы обязательно рассмотрим ваше предложение. Просто воспользуйтесь обратной связью. |
© Школяр. Математика (при поддержке «Ветвистого древа») 2009—2016
Онлайн калькулятор: Кодировка файла
В предыдущей статье я уже затрагивал тему кодировок текста, более подробно описал Юникод и представление его в виде последовательности символов переменной длины UTF-8. Данный калькулятор позволяет преобразовать текст в другие исторические кодировки. Я называю их историческими, потому, что в современных решениях везде, где это можно следует использовать Юникод и его самое удобное представление UTF-8.
Однако старые кодировки также могут быть полезны, когда требуется компактно закодировать текст, например для последующего сжатия и передачи, в том случае, когда принимающая сторона гарантированно знает в какой кодировке передается текст. Например русский текст в в кодировке Windows-1251 будет занимать вдвое меньше места, чем текст в UTF-8.
Например русский текст в в кодировке Windows-1251 будет занимать вдвое меньше места, чем текст в UTF-8.
Итак калькулятор ниже позволяет скачать файл в выбранной кодировке или просмотреть шестнадцатеричный дамп закодированного текста.
Скачать текст как файл с выбором кодировки
КодировкаAtari STCP 856 HebrewDOS Arabic (CP864)DOS Baltic Rim (CP775)DOS Cyrillic (CP855)DOS Cyrillic Russian (CP866)DOS French Canada (CP863)DOS Greek (CP737)DOS Greek 2 (CP869)DOS Hebrew (CP862)DOS Icelandic (CP861)DOS Latin 1 (CP850)DOS Latin 2 (CP852)DOS Latin US (CP437)DOS Nordic (CP865)DOS Portuguese (CP860)DOS Turkish (CP857)EBCDIC 037 USA/CanadaEBCDIC 1026 TurkishEBCDIC 424 HebrewEBCDIC 500 InternationalEBCDIC 875 GreekGSM 03.38ISO 8-bit Urdu (IBM CP1006)ISO 8859-2 (Latin-2)ISO 8859-5ISO 8859-6ISO 8859-7ISO-IR-68ISO/IEC 8859-1 (Latin-1)ISO/IEC 8859-10 (Latin-6)ISO/IEC 8859-11 ISO/IEC 8859-13 (Latin-7)ISO/IEC 8859-14ISO/IEC 8859-15 (Latin-9)ISO/IEC 8859-16 (Latin-10)ISO/IEC 8859-3ISO/IEC 8859-4 (Latin-4)ISO/IEC 8859-8ISO/IEC 8859-9KOI8-RKOI8-UKPS 9566KZ-1048 Mac OS CelticMac OS Central EuropeanMac OS CroatianMac OS CyrillicMac OS DingbatsMac OS GaelicMac OS GreekMac OS IcelandicMac OS InuitMac OS RomanMac OS RomanianMac OS TurkishUTF-8Windows-1250Windows-1251Windows-1252Windows-1253Windows-1254Windows-1255Windows-1256Windows-1257Windows-1258Windows-874Windows-932Windows-936Windows-949Windows-950Чу, я слышу пушек гром!
Входной текст
Шестнадцатеричный дамп
content_copy Ссылка save Сохранить extension Виджет
Просмотреть созданный файл можно при помощи калькулятора Прочитать файл в старой кодировке.
Калькулятор вернет ошибку, в том случае, если выбрана неверная кодировка. В случае с Юникодом, это невозможно — в нем представлены символы всех современных языков. А вот устаревшие 8-битные кодировки содержат ограниченный набор символов и для текста на нескольких языках может вполне не найтись нужной кодировки.
За годы до появления Юникода было придумано множество кодировок для разных языков и наборов символов, поэтому сама задача выбора правильной кодировки для вашего текста может быть непростой. Следующий калькулятор позволяет подобрать кодировки для введенного текста. В результирующей таблице будут выданы, только те кодировки, при помощи которых можно гарантированно закодировать заданный текст.
В какой кодировке можно представить текст?
Чу, я слышу пушек гром!
Входной текст
КодировкаAtari STCP 856 HebrewDOS Arabic (CP864)DOS Baltic Rim (CP775)DOS Cyrillic (CP855)DOS Cyrillic Russian (CP866)DOS French Canada (CP863)DOS Greek (CP737)DOS Greek 2 (CP869)DOS Hebrew (CP862)DOS Icelandic (CP861)DOS Latin 1 (CP850)DOS Latin 2 (CP852)DOS Latin US (CP437)DOS Nordic (CP865)DOS Portuguese (CP860)DOS Turkish (CP857)EBCDIC 037 USA/CanadaEBCDIC 1026 TurkishEBCDIC 424 HebrewEBCDIC 500 InternationalEBCDIC 875 GreekGSM 03. 38ISO 8-bit Urdu (IBM CP1006)ISO 8859-2 (Latin-2)ISO 8859-5ISO 8859-6ISO 8859-7ISO-IR-68ISO/IEC 8859-1 (Latin-1)ISO/IEC 8859-10 (Latin-6)ISO/IEC 8859-11 ISO/IEC 8859-13 (Latin-7)ISO/IEC 8859-14ISO/IEC 8859-15 (Latin-9)ISO/IEC 8859-16 (Latin-10)ISO/IEC 8859-3ISO/IEC 8859-4 (Latin-4)ISO/IEC 8859-8ISO/IEC 8859-9KOI8-RKOI8-UKPS 9566KZ-1048 Mac OS CelticMac OS Central EuropeanMac OS CroatianMac OS CyrillicMac OS DingbatsMac OS GaelicMac OS GreekMac OS IcelandicMac OS InuitMac OS RomanMac OS RomanianMac OS TurkishUTF-8Windows-1250Windows-1251Windows-1252Windows-1253Windows-1254Windows-1255Windows-1256Windows-1257Windows-1258Windows-874Windows-932Windows-936Windows-949Windows-950
38ISO 8-bit Urdu (IBM CP1006)ISO 8859-2 (Latin-2)ISO 8859-5ISO 8859-6ISO 8859-7ISO-IR-68ISO/IEC 8859-1 (Latin-1)ISO/IEC 8859-10 (Latin-6)ISO/IEC 8859-11 ISO/IEC 8859-13 (Latin-7)ISO/IEC 8859-14ISO/IEC 8859-15 (Latin-9)ISO/IEC 8859-16 (Latin-10)ISO/IEC 8859-3ISO/IEC 8859-4 (Latin-4)ISO/IEC 8859-8ISO/IEC 8859-9KOI8-RKOI8-UKPS 9566KZ-1048 Mac OS CelticMac OS Central EuropeanMac OS CroatianMac OS CyrillicMac OS DingbatsMac OS GaelicMac OS GreekMac OS IcelandicMac OS InuitMac OS RomanMac OS RomanianMac OS TurkishUTF-8Windows-1250Windows-1251Windows-1252Windows-1253Windows-1254Windows-1255Windows-1256Windows-1257Windows-1258Windows-874Windows-932Windows-936Windows-949Windows-950
Файл очень большой, при загрузке и создании может наблюдаться торможение браузера.
Загрузить
close
content_copy Ссылка save Сохранить extension Виджет
В калькуляторах поддерживаются 70 различных кодировок:
Кодировки IBM EBCDIC
EBCDIC — стандартный 8-битный код, разработанный корпорацией IBM для использования на мэйнфреймах IBM и совместимых с ними.
| Кодировка | Языки / Страны использования |
|---|---|
| EBCDIC 424 Hebrew | Иврит |
| EBCDIC 037 USA/Canada | США, Канада, Португалия, Бразилия, Австралия, Новой Зеландия и Южной Африка |
| EBCDIC 1026 Turkish | Турция |
| EBCDIC 500 International | Интернациональный |
| EBCDIC 875 Greek | Греческий |
Кодировки в стандарте ISO 8859
Семейство ASCII совместимых кодировок, разработанных международными организациями ISO и IEC
| Кодировка | Языки/Страны |
|---|---|
| ISO 8859-2 (Latin-2) | Восточноевропейские языки, использующие латиницу |
| ISO 8859-5 | Кириллица |
| ISO 8859-6 | Арабский |
| ISO 8859-7 | Современный греческий |
| ISO/IEC 8859-1 (Latin-1) | Западноевропейские языки |
| ISO/IEC 8859-10 (Latin-6) | Североевропейские языки |
| ISO/IEC 8859-11 | Тайский |
| ISO/IEC 8859-13 (Latin-7) | Эстонский, латышский, литовский |
| ISO/IEC 8859-14 | Кельтские языки |
| ISO/IEC 8859-15 (Latin-9) | Западноевропейские языки |
| ISO/IEC 8859-16 (Latin-10) | Восточноевропейские языки, использующие латиницу |
| ISO/IEC 8859-3 | Турецкий, мальтийский, эсперанто |
| ISO/IEC 8859-4 (Latin-4) | Эстонский, латышский, литовский, гренландский, саамский |
| ISO/IEC 8859-8 | Иврит |
| ISO/IEC 8859-9 | Турецкий |
Кодировки KOI8
KOI8 — 8-битовая кодировка совместимая с ASCII для представления букв кириллических алфавитов
| Кодировка | Языки |
|---|---|
| KOI8-R | Русский |
| KOI8-U | Украинский |
Кодировки Mac OS
| Кодировка | Языки/Страны |
|---|---|
| Mac OS Celtic | Кельтские языки |
| Mac OS Gaelic | Гэльский |
| Mac OS Central European | Языки Центральной Европы |
| Mac OS Croatian | Сербско/Хорватский |
| Mac OS Cyrillic | Кириллица |
| Mac OS Greek | Греческй |
| Mac OS Icelandic | Исландский |
| Mac OS Inuit | Инуктитут |
| Mac OS Roman | Западноевропейские языки |
| Mac OS Romanian | Румынский |
| Mac OS Turkish | Турецкий |
Кодировки DOS
Кодировки для MS-DOS и подобных ей операционных систем.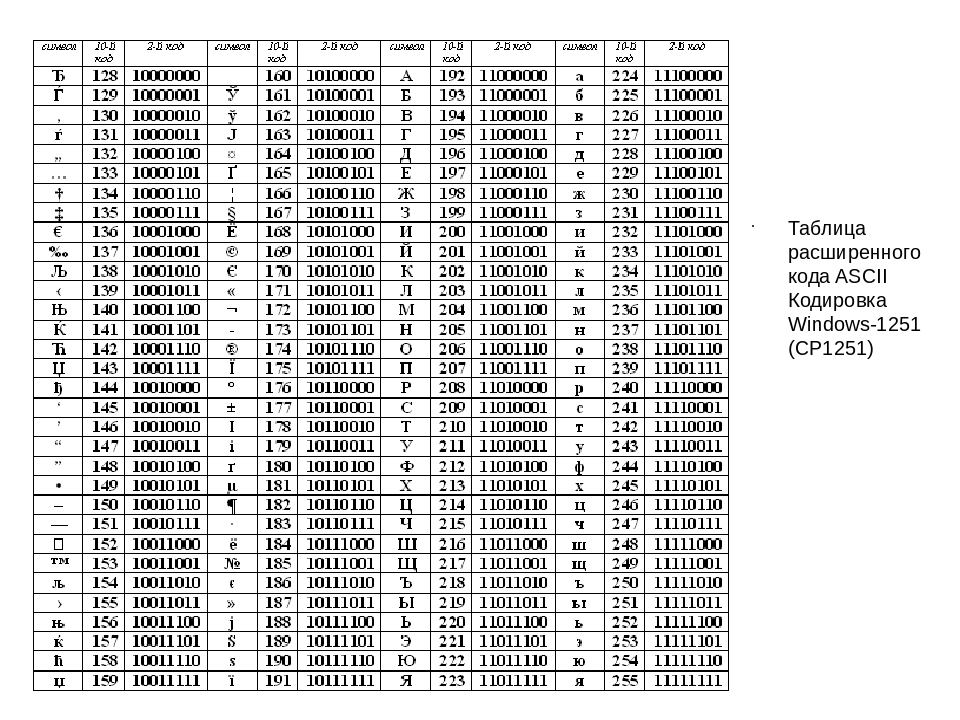
| Кодировка | Языки/Страны |
|---|---|
| DOS Latin US (CP437) | Восточноевропейские языки, использующие латиницу |
| DOS Greek (CP737) | Греческий |
| DOS Baltic Rim (CP775) | Эстонский, латышский, литовский |
| DOS Latin 1 (CP850) | Западноевропейские языки |
| DOS Latin 2 (CP852) | Восточноевропейские языки, использующие латиницу |
| DOS Cyrillic (CP855) | Кириллица |
| CP 856 Hebrew | Иврит |
| DOS Turkish (CP857) | Турецкий |
| DOS Portuguese (CP860) | Португальский |
| DOS Icelandic (CP861) | Исландский |
| DOS Hebrew (CP862) | Иврит |
| DOS French Canada (CP863) | Французский |
| DOS Arabic (CP864) | Арабский |
| DOS Nordic (CP865) | Норвежский |
| DOS Cyrillic Russian (CP866) | Русский |
| DOS Greek 2 (CP869) | Греческий |
Кодировки Windows
| Кодировка | Языки/Страны |
|---|---|
| Windows-1250 | Языки Центральной и Восточной Европы |
| Windows-1251 | Русский, украинский белорусский, сербский, македонский, болгарский |
| Windows-1252 | Западноевропейские языки |
| Windows-1253 | Современный греческий |
| Windows-1254 | Турецкий |
| Windows-1255 | Иврит |
| Windows-1256 | Арабский |
| Windows-1257 | Эстонский, латышский, литовский |
| Windows-1258 | Вьетнамский |
| Windows-874 | Тайский |
| Windows-932 | Японский |
| Windows-936 | Упрощенный китайский |
| Windows-949 | Корейский |
| Windows-950 | Традиционный китайский |
| KZ-1048 | Казахский |
Прочие кодировки
| Кодировка | Описание |
|---|---|
| Atari ST | Кодировка, использовалась в домашних персональных компьютерах фирмы Atari |
GSM 03.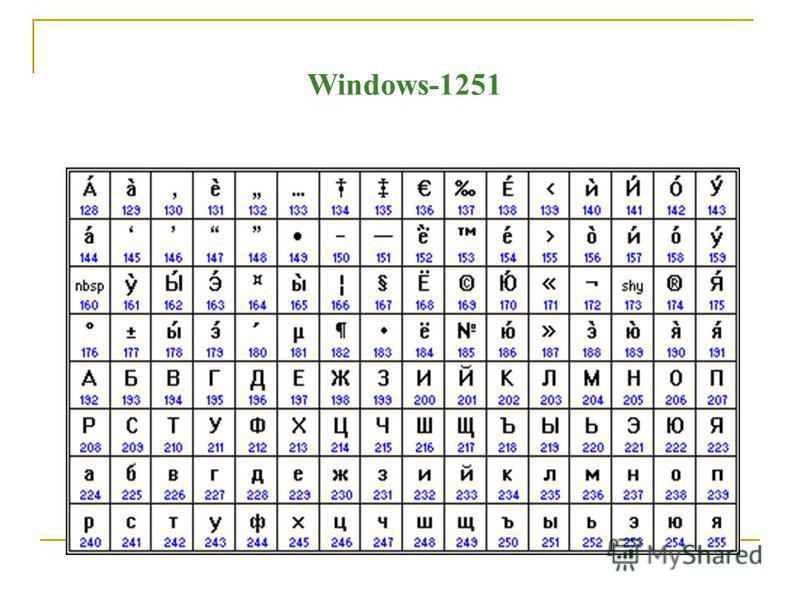 38 38 | Кодировка использовалась в сетях GSM для SMS (коротких сообщений), CB (широковещательная передача коротких сообщений) and USSD (Сервис для организации интерактивных взаимодействий) |
| KPS 9566 | Кодировка, разработанная в Северной Корее для поддержки символов корейского языка Хангыль |
| ISO 8-bit Urdu (IBM CP1006) | Использовалась компанией IBM в операционной системе AIX в Пакистане для языка Урду |
| ISO-IR-68 | Кодировка для представления символов в языке программирования APL |
Правила преобразования исторических кодировок в Юникод были получены с сайта unicode.org
Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.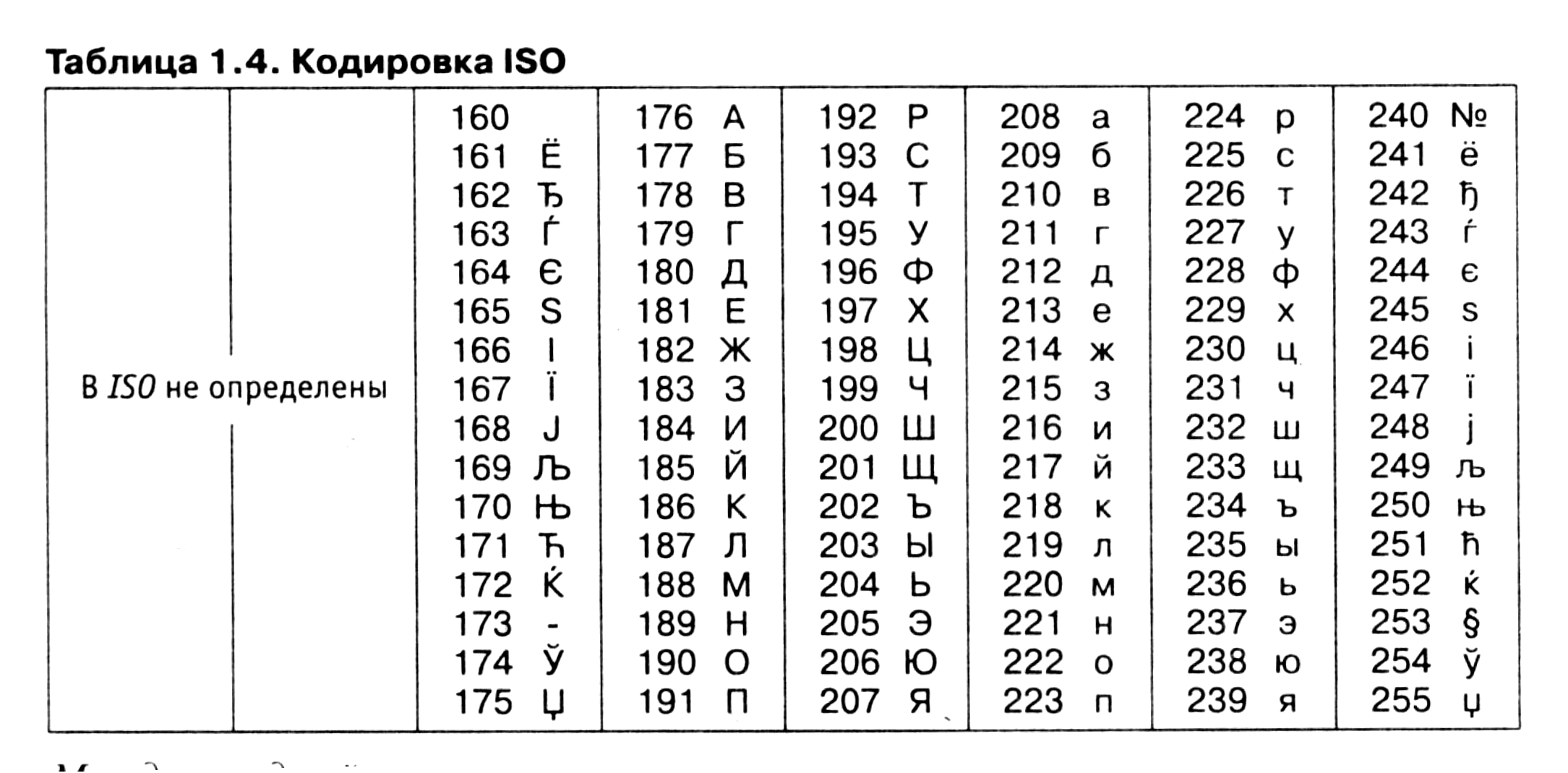
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему — 01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт.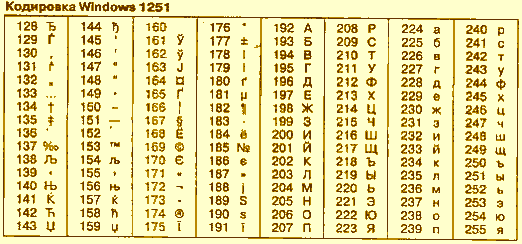 То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом.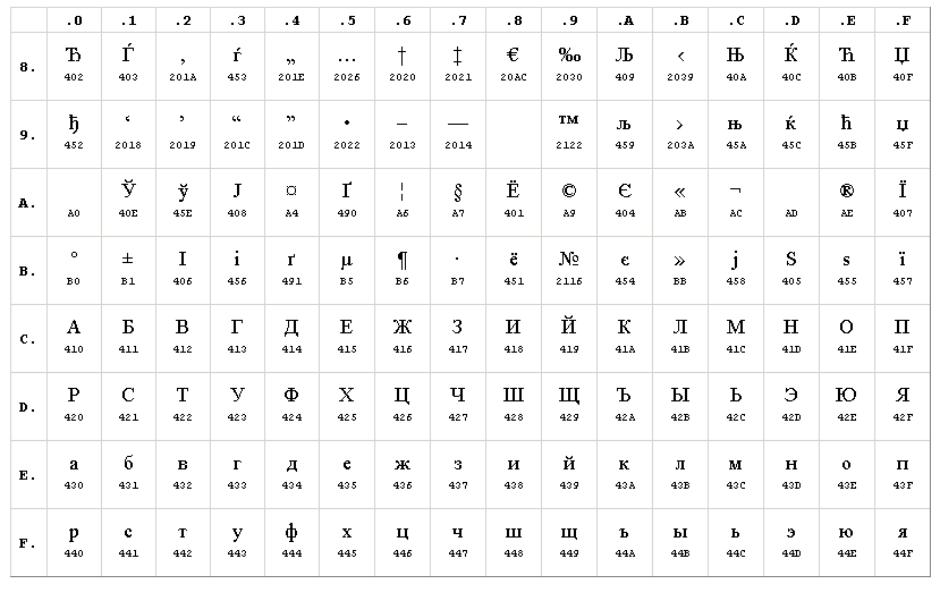 То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.
В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.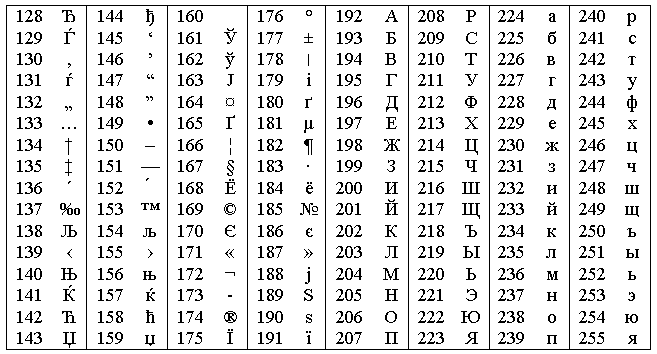
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16
Unicode с cp1251 и utf-8 на windows
Я играю с unicode в python.
Итак есть простой скрипт:
# -*- coding: cp1251 -*-
print 'юникод'.decode('cp1251')
print unicode('юникод', 'cp1251')
print unicode('юникод', 'utf-8')
В cmd я переключил кодировку на Active code page: 1251 .
И есть выход:
СЋРЅРёРєРѕРґ
СЋРЅРёРєРѕРґ
юникод
Я немного сбит с толку.
Поскольку я указал кодировку cp1251 , я ожидаю, что она будет декодирована правильно.
Но в результате там были интерпретированы некоторые мусорные кодовые точки.
Я понимаю, что 'юникод' -это просто байт, как:
'\xd1\x8e\xd0\xbd\xd0\xb8\xd0\xba\xd0\xbe\xd0\xb4' .
Но есть ли способ получить правильный вывод в terminal с cp1251 ?
Должен ли я строить байтовую строку вручную?
Похоже, я что-то не так понял.
python
python-2.7
unicode
encoding
Поделиться
Источник
xiº
04 марта 2016 в 15:29
3 ответа
- Как сделать dired в Emacs использовать cp1251 под Windows?
Я хочу, чтобы моя кодировка по умолчанию оставалась utf-8. Но когда под Windows-я хочу видеть некоторые из моих имен файлов в dired с помощью cp1251. (Из-за отсутствия поддержки utf в Windows) Все отображается следующим образом: \361\345\354 Так как же я могу это сделать: (setq…
- Какую кодировку unicode (UTF-8, UTF-16, other) использует Windows для своих типов данных Unicode?
Существуют различные кодировки одной и той же таблицы Unicode (стандартизированной). Например, для кодировки UTF-8 A соответствует 0x0041 , но для кодировки UTF-16 тот же самый A представлен как 0xfeff0041 . Из этой блестящей статьи я узнал, что когда я программирую на C++ для платформы Windows и…
5
Думаю, я могу понять, что с тобой случилось. Последняя строка дала мне намек, что ваши мусорные кодовые точки подтверждены. Вы пытаетесь отобразить символы cp1251, но ваш редактор настроен на использование utf8.
# -*- coding: cp1251 -*- используется интерпретатором Python только для преобразования символов из исходных файлов python, которые находятся за пределами диапазона ASCII. И в любом случае он используется только для unicode литералов, потому что байты из исходного источника дают er… точно такие же байты в байтовых строках. Некоторые текстовые редакторы достаточно любезны, чтобы автоматически использовать эту строку (редактор IDLE), но я мало уверен в этом и всегда переключаюсь вручную на правильную кодировку, когда использую, например, gvim. Короткая история: # -*- coding: cp1251 -*- не используется в вашем коде и может только ввести читателя в заблуждение, так как это не фактическая кодировка.
Если вы хотите быть уверены в том, что находится в вашем источнике, вам лучше использовать явные побеги. На кодовой странице 1251 это слово юникод состоит из следующих символов: '\xfe\xed\xe8\xea\xee\xe4'
Если вы напишете этот источник:
txt = '\xfe\xed\xe8\xea\xee\xe4'
print txt
print txt.decode('cp1251')
print unicode(txt, 'cp1251')
print unicode(txt, 'utf-8')
и выполните его в консоли, настроенной на использование кодировки CP1251, первые три строки выведут юникод, а последняя выдаст исключение UnicodeDecodeError, потому что ввод больше не является допустимым ‘utf8’.
В качестве альтернативы, если вы чувствуете себя комфортно с вашим текущим редактором, вы можете написать:
# -*- coding: utf8 -*-
txt = 'юникод'.decode('utf8').encode('cp1251') # or simply txt = u'юникод'.encode('cp1251')
print txt
print txt.decode('cp1251')
print unicode(txt, 'cp1251')
print unicode(txt, 'utf-8')
что должно дать те же результаты — но теперь объявленная исходная кодировка должна быть фактической кодировкой вашего источника python.
BTW, a Python 3.5 IDLE, который изначально использует unicode, подтвердил, что:
>>> 'СЋРЅРёРєРѕРґ'.encode('cp1251').decode('utf8')
'юникод'
Поделиться
Serge Ballesta
04 марта 2016 в 16:00
1
Ваша проблема заключается в том, что объявление кодировки неверно: ваш редактор использует кодировку utf-8 символов для сохранения исходного кода. Используйте # -*- coding: utf-8 -*- , чтобы исправить это.
>>> u'юникод'
u'\u044e\u043d\u0438\u043a\u043e\u0434'
>>> u'юникод'.encode('utf-8')
'\xd1\x8e\xd0\xbd\xd0\xb8\xd0\xba\xd0\xbe\xd0\xb4'
>>> print _.decode('cp1251') # mojibake due to the wrong encoding
СЋРЅРёРєРѕРґ
>>> print u'юникод'
юникод
Не используйте bytestrings ( '' literals create bytes object on Python 2) для представления текста; вместо этого используйте Unicode strings (u'' literals — unicode type).
Если ваш код использует строки Unicode, то кодовая страница, используемая вашей консолью Windows, не имеет значения, если выбранный шрифт может отображать соответствующие (не BMP) символы. См . Python, Unicode и консоль Windows
Вот полный код, для справки:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
print(u'юникод')
Примечание: нет .decode(), unicode() . Если вы используете литерал для создания строки; вы должны использовать литералы Unicode, если строка содержит текст. Это единственный вариант на Python 3, где вы не можете поместить не ascii символов внутри литерала bytes , и это хорошая практика (использовать Unicode для текста вместо байтовых строк) и на Python 2.
Если вы получаете bytestring в качестве входного сигнала (не литерала) от некоторого API, то его кодировка не имеет ничего общего с объявлением кодировки. Какая именно кодировка будет использоваться, зависит от источника данных.
Поделиться
jfs
05 марта 2016 в 18:34
0
Просто используйте следующее, но убедитесь , что вы сохранили исходный код в объявленной кодировке. Это может быть любая кодировка, поддерживающая символы, которые вы хотите напечатать. terminal может быть в другой кодировке, если он также поддерживает символы, которые вы хотите напечатать:
#coding:utf8
print u'юникод'
Преимущество в том, что вам не нужно знать кодировку terminal. Python обычно 1 обнаруживает кодировку terminal и правильно кодирует вывод печати.
1 Если ваш terminal-это неправильно.
Поделиться
Mark Tolonen
05 марта 2016 в 17:08
- Unicode для UTF-8 до Unicode?
Я читаю некоторые данные, включая строки CDATA из XML. В XML порождается linux машина, и, закодированных в utf-8. Текст в XML снова создается человеком на машине windows и может содержать символы windows unicode, такие как „ и “. теперь эти символы каким-то образом искажаются во всем процессе….
- Преобразование кодировки элемента DOM из CP1251 в UTF-8
У меня есть простой серверный код, который принимает запрос xml и вставляет его в виде строки в столбец Clob базы данных Oracle. Проблема в том, что клиентская сторона отправляет запрос xml с кодированным текстом CP1251, но мне нужно вставить его в Oracle с кодировкой UTF-8. Теперь код, который я…
Похожие вопросы:
Как преобразовать cp1251 в utf-8 программно в Java?
Возможный Дубликат : Преобразование кодировки в java На самом деле мне нужен пример, метод преобразования из кодировки cp1251 в utf-8 в Java. Например, у меня не болит голова в PHP с этим вопросом…
UNICODE, UTF-8 и Windows беспорядок
Я пытаюсь реализовать текстовую поддержку в Windows с намерением также перейти на платформу Linux позже. Было бы идеально поддерживать международные языки единообразным образом, но это, по-видимому,…
Разница между MBCS и UTF-8 на Windows
Я читаю о наборе символов и кодировках на Windows. Я заметил, что в компиляторе Visual Studio (для C++) есть два флага компилятора, которые называются MBCS и UNICODE. В чем разница между ними ? Чего…
Как сделать dired в Emacs использовать cp1251 под Windows?
Я хочу, чтобы моя кодировка по умолчанию оставалась utf-8. Но когда под Windows-я хочу видеть некоторые из моих имен файлов в dired с помощью cp1251. (Из-за отсутствия поддержки utf в Windows) Все…
Какую кодировку unicode (UTF-8, UTF-16, other) использует Windows для своих типов данных Unicode?
Существуют различные кодировки одной и той же таблицы Unicode (стандартизированной). Например, для кодировки UTF-8 A соответствует 0x0041 , но для кодировки UTF-16 тот же самый A представлен как…
Unicode для UTF-8 до Unicode?
Я читаю некоторые данные, включая строки CDATA из XML. В XML порождается linux машина, и, закодированных в utf-8. Текст в XML снова создается человеком на машине windows и может содержать символы…
Преобразование кодировки элемента DOM из CP1251 в UTF-8
У меня есть простой серверный код, который принимает запрос xml и вставляет его в виде строки в столбец Clob базы данных Oracle. Проблема в том, что клиентская сторона отправляет запрос xml с…
Существует ли транслитерация с UTF-8 на CP1251, когда один символ заменяется несколькими символами?
Я использовать функцию iconv функции с опцией транслит. Существует ли транслитерация с UTF-8 на CP1251, когда один символ заменяется несколькими символами? Где я могу найти эту информацию? Я…
Python (запросы) проблема кодирования (UTF-8-CP1251)
Я пытаюсь получить такой вид URL http://example.com/?param=%DD%CC%C0-15 с расширением requests python, как это: group = ЭМА-15.encode(‘cp1251’) r = requests.get(‘http://example.com/?param=’ + group)…
Как преобразовать строку из cp1251 в UTF-8 в Python3?
Нужна помощь с довольно простым скриптом Python 3.6. Во-первых, он загружает файл HTML со старомодного сервера, который использует кодировку cp1251. Затем мне нужно поместить содержимое файла в…
| Каноническое имя для java.nio API | Каноническое имя для API java.io и API java.lang | Псевдоним или псевдоним | Описание |
|---|---|---|---|
| ЦЭСУ-8 | CESU8 | CESU8 CSCESU-8 | Юникод CESU-8 |
| IBM00858 | Cp858 | cp858 858 PC-Multilingual-850 + евро cp00858 ccsid00858 | Вариант CP850 с символом евро |
| IBM437 | Cp437 | ibm437 437 ibm-437 cspc8codepage437 cp437 windows-437 | MS-DOS США, Австралия, Новая Зеландия, Южная Африка |
| IBM775 | Cp775 | ibm-775 ibm775 775 cp775 | PC Baltic |
| IBM850 | Cp850 | cp850 cspc850 многоязычный ibm850 850 ibm-850 | MS-DOS Latin-1 |
| IBM852 | Cp852 | csPCp852 ibm-852 ibm852 852 cp852 | MS-DOS Latin-2 |
| IBM855 | Cp855 | ibm855 855 IBM-855 cp855 cspcp855 | IBM Кириллица |
| IBM857 | Cp857 | ibm857 857 cp857 csIBM857 ibm-857 | IBM Турецкий |
| IBM862 | Cp862 | csIBM862 cp862 ibm862 862 cspc862latinhebrew ibm-862 | PC Еврейский |
| IBM866 | Cp866 | ibm866 866 ibm-866 csIBM866 cp866 | MS-DOS Русский |
| ISO-8859-1 | ISO8859_1 | 819 ISO8859-1 l1 ISO_8859-1: 1987 ISO_8859-1 8859_1 iso-ir-100 latin1 cp819 ISO8859_1 IBM819 ISO_8859_1 IBM-819 csISOLatin1 | ISO-8859-1, латинский алфавит No.1 |
| ISO-8859-2 | ISO8859_2 | ISO8859-2 ibm912 l2 ISO_8859-2 8859_2 cp912 ISO_8859-2: 1987 iso8859_2 iso-ir-101 latin2 912 csISOLatin2 ibm-912 | Латинский алфавит № 2 |
| ISO-8859-4 | ISO8859_4 | 8859_4 латинский4 l4 cp914 ISO_8859-4: 1988 ibm914 ISO_8859-4 iso-ir-110 iso8859_4 csISOLatin4 iso8859-4 914 ibm-914 | Латинский алфавит № 4 |
| ISO-8859-5 | ISO8859_5 | ISO_8859-5: 1988 csISOLatinCyrillic iso-ir-144 iso8859_5 cp915 8859_5 ibm-915 ISO_8859-5 ibm915 915 кириллица ISO8859-5 | Латинский алфавит / кириллица |
| ISO-8859-7 | ISO8859_7 | греческий 8859_7 греческий8 ibm813 ISO_8859-7 iso8859_7 ELOT_928 cp813 ISO_8859-7: 1987 sun_eu_greek csISOLatinGreek iso-ir-126813 iso8859-7 ECMA-118 ibm-813 | Латинский / греческий алфавит (ISO-8859-7: 2003) |
| ISO-8859-9 | ISO8859_9 | ibm-920 ISO_8859-9 8859_9 ISO_8859-9: 1989 ibm920 latin5 l5 iso8859_9 cp920 920 iso-ir-148 ISO8859-9 csISOLatin5 | Латинский алфавит No.5 |
| ISO-8859-13 | ISO8859_13 | iso_8859-13 ISO8859-13 iso8859_13 8859_13 | Латинский алфавит № 7 |
| ISO-8859-15 | ISO8859_15 | ISO8859-15 LATIN0 ISO8859_15_FDIS ISO8859_15 cp923 8859_15 L9 ISO-8859-15 IBM923 csISOlatin9 ISO_8859-15 IBM-923 csISOlatin0 923 LATIN9 | Латинский алфавит № 9 |
| КОИ8-Р | KOI8_R | koi8_r koi8 cskoi8r | КОИ8-Р, Россия |
| КОИ8-У | КОИ8_У | koi8_u | КОИ8-У, Украинский |
| US-ASCII | ASCII | ANSI_X3.4-1968 cp367 csASCII iso-ir-6 ASCII iso_646.irv: 1983 ANSI_X3.4-1986 ascii7 по умолчанию ISO_646.irv: 1991 ISO646-US IBM367 646 us | Американский стандартный код для обмена информацией |
| UTF-8 | UTF8 | юникод-1-1-utf-8 UTF8 | Восьмибитный формат преобразования Unicode (или UCS) |
| UTF-16 | UTF-16 | UTF_16 юникод utf16 UnicodeBig | Шестнадцатиразрядный формат преобразования Unicode (или UCS), порядок байтов идентифицируется необязательной меткой порядка байтов |
| UTF-16BE | UnicodeBig Без маркировки | X-UTF-16BE UTF_16BE ISO-10646-UCS-2 UnicodeBigUnmarked | Шестнадцатиразрядный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов |
| UTF-16LE | UnicodeLittleUnmarked | UnicodeLittleUnmarked UTF_16LE X-UTF-16LE | Шестнадцатибитный формат преобразования Unicode (или UCS), порядок байтов с прямым порядком байтов |
| UTF-32 | UTF_32 | UTF_32 UTF32 | 32-битный формат преобразования Unicode (или UCS), порядок байтов идентифицируется необязательной меткой порядка байтов |
| UTF-32BE | UTF_32BE | X-UTF-32BE UTF_32BE | 32-битный формат преобразования Unicode (или UCS), с прямым порядком байтов заказ |
| UTF-32LE | UTF_32LE | X-UTF-32LE UTF_32LE | 32-битный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов |
| x-UTF-32BE-BOM | UTF_32BE_BOM | UTF_32BE_BOM UTF-32BE-BOM | 32-битный формат преобразования Unicode (или UCS), с прямым порядком байтов порядок, с пометкой порядка байтов |
| x-UTF-32LE-BOM | UTF_32LE_BOM | UTF_32LE_BOM UTF-32LE-BOM | 32-битный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов с отметкой порядка байтов |
| окна-1250 | Cp1250 | cp1250 cp5346 | Окна Восточноевропейская |
| окна-1251 | Cp1251 | cp5347 ansi-1251 cp1251 | Окна Кириллица |
| окна-1252 | Cp1252 | cp5348 cp1252 | Окна Latin-1 |
| окна-1253 | Cp1253 | cp1253 cp5349 | Окна Греческая |
| окна-1254 | Cp1254 | cp1254 cp5350 | Окна Турецкая |
| окна-1257 | Cp1257 | cp1257 cp5353 | Окна Балтика |
| Нет в наличии | UnicodeBig | Не доступен | Шестнадцатибитный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов с отметкой порядка байтов |
| x-IBM737 | Cp737 | cp737 ibm737 737 ibm-737 | PC Греческий |
| x-IBM874 | Cp874 | ibm-874 ibm874 874 cp874 | IBM Тайский |
| x-UTF-16LE-BOM | Юникод, Литтл | Юникод, Литтл | Шестнадцатибитный формат преобразования Unicode (или UCS), порядок байтов с прямым порядком байтов, с меткой порядка байтов |
| Каноническое имя для java.nio API | Каноническое имя для API java.io и API java.lang | Псевдоним или псевдоним | Описание |
| Большой5 | Большой5 | csBig5 | Big5, традиционный китайский |
| Big5-HKSCS | Big5_HKSCS | big5-hkscs big5hk Big5_HKSCS big5hkscs | Big5 с расширениями для Гонконга, традиционный китайский (включая редакцию 2001 г.) |
| EUC-JP | EUC_JP | csEUCPkdFmtjapanese x-euc-jp eucjis Extended_UNIX_Code_Packed_Format_for_Японский euc_jp eucjp x-eucjp | JISX 0201, 0208 и 0212, кодировка EUC, японская |
| EUC-KR | EUC_KR | ksc5601-1987 csEUCKR ksc5601_1987 ksc5601 5601 euc_kr ksc_5601 ks_c_5601-1987 euckr | KS C 5601, кодировка EUC, корейский язык |
| ГБ18030 | ГБ18030 | гб18030-2000 | Упрощенный китайский, стандарт КНР |
| ГБ 2312 | EUC_CN | GB2312 EUC-CN X-EUC-CN EUCCN EUC_CN GB2312-80 GB2312-1980 | GB2312, кодировка EUC, упрощенный китайский |
| ГБК | ГБК | CP936 окна-936 | GBK, упрощенный китайский |
| IBM-Thai | Cp838 | ibm-838 ibm838 838 cp838 | IBM Thailand расширенный SBCS |
| IBM01140 | Cp1140 | cp1140 1140 cp01140 ebcdic-us-037 + евро ccsid01140 | Вариант Cp037 с символом евро |
| IBM01141 | Cp1141 | 1141 cp1141 cp01141 ccsid01141 ebcdic-de-273 + евро | Вариант Cp273 с символом евро |
| IBM01142 | Cp1142 | 1142 cp1142 cp01142 ccsid01142 ebcdic-no-277 + евро ebcdic-dk-277 + евро | Вариант Cp277 с символом евро |
| IBM01143 | Cp1143 | 1143 cp01143 ccsid01143 cp1143 ebcdic-fi-278 + евро ebcdic-se-278 + евро | Вариант Cp278 с символом евро |
| IBM01144 | Cp1144 | cp01144 ccsid01144 ebcdic-it-280 + евро cp1144 1144 | Вариант Cp280 с символом евро |
| IBM01145 | Cp1145 | ccsid01145 ebcdic-es-284 + евро 1145 cp1145 cp01145 | Вариант CP284 с символом евро |
| IBM01146 | Cp1146 | ebcdic-gb-285 + евро 1146 cp1146 cp01146 ccsid01146 | Вариант CP285 с символом евро |
| IBM01147 | Cp1147 | cp1147 1147 cp01147 ccsid01147 ebcdic-fr-277 + евро | Вариант Cp297 с символом евро |
| IBM01148 | Cp1148 | cp1148 ebcdic-international-500 + евро 1148 cp01148 ccsid01148 | Вариант CP500 с символом евро |
| IBM01149 | Cp1149 | ebcdic-s-871 + евро 1149 cp1149 cp01149 ccsid01149 | Вариант Cp871 с символом евро |
| IBM037 | Cp037 | cp037 ibm037 ibm-037 csIBM037 ebcdic-cp-us ebcdic-cp-ca ebcdic-cp-nl ebcdic-cp-wt 037 cpibm37 cs-ebcdic-cp-wt ibm-37 cs-ebcdic-cp-us cs-ebcdic-cp-ca cs-ebcdic-cp-nl | США, Канада (двуязычный, французский), Нидерланды, Португалия, Бразилия, Австралия |
| IBM1026 | Cp1026 | cp1026 ibm-1026 1026 ibm1026 | IBM Latin-5, Турция |
| IBM1047 | Cp1047 | ibm-1047 1047 cp1047 | Набор символов Latin-1 для хостов EBCDIC |
| IBM273 | Cp273 | ibm-273 ibm273 273 cp273 | IBM Австрия, Германия |
| IBM277 | Cp277 | ibm277 277 cp277 ibm-277 | IBM Дания, Норвегия |
| IBM278 | Cp278 | cp278 278 ibm-278 ebcdic-cp-se csIBM278 ibm278 ebcdic-sv | IBM Финляндия, Швеция |
| IBM280 | Cp280 | ibm280 280 cp280 ibm-280 | IBM Италия |
| IBM284 | Cp284 | csIBM284 ibm-284 cpibm284 ibm284 284 cp284 | IBM Каталонский / Испания, Испанский Латинская Америка |
| IBM285 | Cp285 | csIBM285 cp285 ebcdic-gb ibm-285 cpibm285 ibm285 285 ebcdic-cp-gb | IBM Великобритания, Ирландия |
| IBM290 | Cp290 | ibm290 290 cp290 EBCDIC-JP-кана csIBM290 ibm-290 | IBM Japanese Katakana Host Extended SBCS |
| IBM297 | Cp297 | 297 csIBM297 cp297 ibm297 ibm-297 cpibm297 ebcdic-cp-fr | IBM Франция |
| IBM420 | Cp420 | ibm420 420 cp420 csIBM420 ibm-420 ebcdic-cp-ar1 | IBM арабский |
| IBM424 | Cp424 | ebcdic-cp-he csIBM424 ibm-424 ibm424 424 cp424 | IBM Еврейский |
| IBM500 | Cp500 | ibm-500 ibm500 500 ebcdic-cp-bh ebcdic-cp-ch csIBM500 cp500 | EBCDIC 500V1 |
| IBM860 | Cp860 | ibm860 860 cp860 csIBM860 ibm-860 | MS-DOS Португальский |
| IBM861 | Cp861 | cp861 ibm861 861 ibm-861 cp-is csIBM861 | MS-DOS Исландский |
| IBM863 | Cp863 | csIBM863 ibm-863 ibm863 863 cp863 | MS-DOS Канадский французский |
| IBM864 | Cp864 | csIBM864 ibm-864 ibm864 864 cp864 | PC Арабский |
| IBM865 | Cp865 | ibm-865 csIBM865 cp865 ibm865 865 | MS-DOS Nordic |
| IBM868 | Cp868 | ibm868 868 cp868 csIBM868 ibm-868 cp-ar | MS-DOS Пакистан |
| IBM869 | Cp869 | cp869 ibm869 869 ibm-869 cp-gr csIBM869 | IBM Современный греческий |
| IBM870 | Cp870 | 870 cp870 csIBM870 ibm-870 ibm870 ebcdic-cp-roece ebcdic-cp-yu | IBM Multilingual Latin-2 |
| IBM871 | Cp871 | ibm871 871 cp871 ebcdic-cp-is csIBM871 ibm-871 | IBM Исландия |
| IBM918 | Cp918 | 918 ibm-918 ebcdic-cp-ar2 cp918 | IBM, Пакистан (урду) |
| ISO-2022-CN | ISO2022CN | csISO2022CN ISO2022CN | GB2312 и CNS11643 в форме ISO 2022 CN, упрощенной и Традиционный китайский (только преобразование в Unicode) |
| ISO-2022-JP | ISO2022JP | csjisencoding iso2022jp jis_encoding jis csISO2022JP | JIS X 0201, 0208, в форме ISO 2022, японский |
| ISO-2022-JP-2 | ISO2022JP2 | csISO2022JP2 iso2022jp2 | JIS X 0201, 0208, 0212 в форме ISO 2022, японский |
| ISO-2022-KR | ISO2022KR | csISO2022KR ISO2022KR | ISO 2022 KR, корейский |
| ISO-8859-3 | ISO8859_3 | ISO8859-3 ibm913 8859_3 l3 cp913 ISO_8859-3 iso8859_3 latin3 csISOLatin3 913 ISO_8859-3: 1988 ibm-913 iso-ir-109 | Латинский алфавит No.3 |
| ISO-8859-6 | ISO8859_6 | ASMO-708 8859_6 iso8859_6 ISO_8859-6 csISOLatin Арабский ibm1089 арабский ibm-1089 1089 ECMA-114 iso-ir-127 ISO_8859-6: 1987 ISO8859-6 cp1089 | Латинский / арабский алфавит |
| ISO-8859-8 | ISO8859_8 | 8859_8 ISO_8859-8 ISO_8859-8: 1988 cp916 iso-ir-138 ISO8859-8 иврит iso8859_8 ibm-916 csISOLatin иврит 916 ibm916 | Латинский / еврейский алфавит |
| JIS_X0201 | JIS_X0201 | JIS0201 csHalfWidthKatakana X0201 JIS_X0201 | JIS X 0201 |
| JIS_X0212-1990 | JIS_X0212-1990 | JIS0212 iso-ir-159 x0212 jis_x0212-1990 csISO159JISX02121990 | JIS X 0212 |
| Shift_JIS | SJIS | shift_jis x-sjis sjis shift-jis ms_kanji csShiftJIS | Shift-JIS, японский |
| ТИС-620 | TIS620 | тис620 тис620.2533 | TIS620, тайский |
| окна-1255 | Cp1255 | cp1255 | Windows Иврит |
| окна-1256 | Cp1256 | cp1256 | Windows арабский |
| окна-1258 | Cp1258 | cp1258 | Windows Вьетнамский |
| окна-31j | MS932 | MS932 Windows-932 CSWindows31J | Окна японские |
| x-Big5-Solaris | Big5_Solaris | Big5_Solaris | Big5 с семью дополнительными отображениями идеограммы Ханзи для Solaris zh_TW.BIG5 язык |
| x-euc-jp-linux | EUC_JP_LINUX | euc_jp_linux euc-jp-linux | JISX 0201, 0208, кодировка EUC, японская |
| x-EUC-TW | EUC_TW | euctw cns11643 EUC-TW euc_tw | CNS11643 (плоскость 1-7,15), кодировка EUC, традиционный китайский |
| x-eucJP-Open | EUC_JP_Solaris | eucJP-open EUC_JP_Solaris | JISX 0201, 0208, 0212, кодировка EUC японская |
| х-IBM1006 | Cp1006 | ibm1006 ibm-1006 1006 cp1006 | IBM AIX Пакистан (урду) |
| x-IBM1025 | Cp1025 | ibm-1025 1025 cp1025 ibm1025 | IBM Multilingual Cyrillic: Болгария, Босния, Герцеговина, Македония (FYR) |
| x-IBM1046 | Cp1046 | ibm1046 ibm-1046 1046 cp1046 | IBM Arabic — Windows |
| х-IBM1097 | Cp1097 | ibm1097 ibm-1097 1097 cp1097 | IBM Иран (фарси) / персидский |
| x-IBM1098 | Cp1098 | ibm-1098 1098 cp1098 ibm1098 | IBM Иран (фарси) / персидский (ПК) |
| х-IBM1112 | Cp1112 | ibm1112 ibm-1112 1112 cp1112 | IBM Латвия, Литва |
| х-IBM1122 | Cp1122 | cp1122 ibm1122 ibm-1122 1122 | IBM Эстония |
| х-IBM1123 | Cp1123 | ibm1123 ibm-1123 1123 cp1123 | IBM Украина |
| x-IBM1124 | Cp1124 | ibm-1124 1124 cp1124 ibm1124 | IBM AIX Украина |
| x-IBM1166 | Cp1166 | cp1166 ibm1166 ibm-1166 1166 | IBM Cyrillic Multilingual с евро для Казахстана |
| x-IBM1364 | Cp1364 | cp1364 ibm1364 ibm-1364 1364 | IBM EBCDIC KS X 1005-1 |
| х-IBM1381 | Cp1381 | cp1381 ibm-1381 1381 ibm1381 | IBM OS / 2, DOS Китайская Народная Республика (КНР) |
| x-IBM1383 | Cp 1383 | ibm1383 ibm-1383 1383 cp1383 | IBM AIX Китайская Народная Республика (КНР) |
| х-IBM300 | CP300 | cp300 ibm300 300 ibm-300 | IBM Японский двухбайтовый латинский хост |
| x-IBM33722 | Cp33722 | 33722 ibm-33722 cp33722 ibm33722 ibm-5050 ibm-33722_vascii_vpua | IBM-eucJP — японский (расширенный набор 5050) |
| x-IBM833 | Cp833 | ibm833 cp833 ibm-833 | IBM Korean Host Extended SBCS |
| x-IBM834 | Cp834 | ibm834 834 cp834 ibm-834 | IBM EBCDIC DBCS-only Korean |
| x-IBM856 | Cp856 | ibm856 856 cp856 ibm-856 | IBM Еврейский |
| x-IBM875 | Cp875 | ibm-875 ibm875 875 cp875 | IBM Греческий |
| х-IBM921 | Cp921 | ibm921 921 ibm-921 cp921 | IBM Латвия, Литва (AIX, DOS) |
| x-IBM922 | Cp922 | ibm922 922 cp922 ibm-922 | IBM Эстония (AIX, DOS) |
| x-IBM930 | Cp930 | ibm-930 ibm930 930 cp930 | Японские катакана и кандзи смешанные с 4370 УДК, расширенный набор из 5026 |
| x-IBM933 | Cp933 | ibm933 933 cp933 ibm-933 | Корейский смешанный с 1880 УДК, расширенный набор 5029 |
| х-IBM935 | Cp935 | cp935 ibm935 935 ibm-935 | Узел на упрощенном китайском, смешанный с 1880 UDC, расширенный набор 5031 |
| x-IBM937 | Cp937 | ibm-937 ibm937 937 cp937 | Традиционный китайский хост, соединенный с 6204 UDC, расширенный набор 5033 |
| x-IBM939 | Cp939 | ibm-939 cp939 ibm939 939 | (Японские латинские кандзи), смешанные с 4370 УДК, расширенный набор из 5035 |
| х-IBM942 | Cp942 | ibm-942 cp942 ibm942 942 | IBM OS / 2 Japanese, расширенный набор Cp932 |
| x-IBM942C | Cp942C | ibm942C cp942C ibm-942C 942C | Вариант Cp942 |
| x-IBM943 | Cp943 | ibm943 943 ibm-943 cp943 | IBM OS / 2 Japanese, расширенный набор Cp932 и Shift-JIS |
| х-IBM943C | Cp943C | 943C cp943C ibm943C ibm-943C | Вариант Cp943 |
| x-IBM948 | Cp948 | ibm-948 ibm948 948 cp948 | OS / 2 Китайский (Тайвань) расширенный набор 938 |
| x-IBM949 | Cp949 | ibm-949 ibm949 949 cp949 | ПК Корейский |
| x-IBM949C | Cp949C | ibm949C ibm-949C cp949C 949C | Вариант Cp949 |
| x-IBM950 | CP950 | cp950 ibm950 950 ibm-950 | ПК Китайский (Гонконг, Тайвань) |
| x-IBM964 | Cp964 | ibm-964 cp964 ibm964 964 | AIX китайский (Тайвань) |
| х-IBM970 | CP970 | ibm970 ibm-eucKR 970 cp970 ibm-970 | AIX корейский |
| x-ISCII91 | ISCII91 | ISCII91 iso-ir-153 iscii ST_SEV_358-88 csISO153GOST1976874 | ISCII91 кодировка индийских скриптов |
| х-ISO2022-CN-CNS | ISO2022_CN_CNS | Не доступен | CNS11643 в форме ISO 2022 CN, традиционный китайский (преобразование только из Unicode) |
| x-ISO2022-CN-GB | ISO2022_CN_GB | Не доступен | GB2312 в форме ISO 2022 CN, упрощенный китайский (преобразование из Только Unicode) |
| x-iso-8859-11 | х-iso-8859-11 | iso-8859-11 iso8859_11 | Латинский / тайский алфавит |
| x-JIS0208 | х-JIS0208 | JIS0208 JIS_C6226-1983 iso-ir-87 x0208 JIS_X0208-1983 csISO87JISX0208 | JIS X 0208 |
| x-JISAutoDetect | JISAutoDetect | JISAutoDetect | Обнаруживает и преобразует Shift-JIS, EUC-JP, ISO 2022 JP (преобразование только в Unicode) |
| x-Johab | x-Johab | ms1361 ksc5601_1992 johab ksc5601-1992 | Корейский, набор символов Джохаб |
| x-Mac Арабский | Макарабский | Макарабский | Macintosh Арабский |
| x-MacCentralEurope | MacCentralEurope | MacCentralEurope | Macintosh Latin-2 |
| x-MacCroatian | МакКроат | МакКроат | Macintosh Хорватский |
| х-MacCyrillic | MacCyrillic | MacCyrillic | Macintosh Кириллица |
| х-MacDingbat | MacDingbat | MacDingbat | Macintosh Dingbat |
| x-MacGreek | MacGreek | MacGreek | Macintosh Греческий |
| x-Mac Иврит | MacHebrew | MacHebrew | Macintosh Иврит |
| x-MacIceland | MacIceland | MacIceland | Macintosh Исландия |
| x-MacRoman | MacRoman | MacRoman | Macintosh Roman |
| x-Mac Румыния | MacRomania | MacRomania | Macintosh Румыния |
| x-MacSymbol | MacSymbol | MacSymbol | Macintosh Symbol |
| x-MacThai | MacThai | MacThai | Тайский Macintosh |
| x-Mac Турецкий | MacTurkish | MacTurkish | Macintosh Турецкий |
| x-Mac Украина | Mac Украина | Mac Украина | Macintosh Украина |
| x-MS932_0213 | x-MS950-HKSCS MS950_HKSCS | Не доступен | Shift_JISX0213 Windows MS932 вариант |
| x-MS950-HKSCS | MS950_HKSCS | MS950_HKSCS | Windows Традиционный китайский с расширениями для Гонконга |
| x-MS950-HKSCS-XP | x-mswin-936 MS936 | MS950_HKSCS_XP | HKSCS Windows XP вариант |
| x-mswin-936 | MS936 | мс936 мс_936 | Windows (упрощенный китайский) |
| x-PCK | PCK | уп | Версия Shift_JIS для Solaris |
| x-SJIS_0213 | x-SJIS_0213 | Не доступен | Shift_JISX0213 |
| x-окна-50220 | Cp50220 | cp50220 ms50220 | Кодовая страница Windows 50220 (7-битная реализация) |
| x-windows-50221 | Cp50221 | cp50221 ms50221 | Кодовая страница Windows 50221 (7-разрядная реализация) |
| x-окна-874 | MS874 | мс-874 мс874 окна-874 | Windows тайский |
| x-окна-949 | MS949 | windows949 ms949 windows-949 ms_949 | Windows корейский |
| x-окна-950 | MS950 | ms950 windows-950 | Windows Традиционный китайский |
| x-windows-iso2022jp | x-windows-iso2022jp | окна-iso2022jp | Вариант ISO-2022-JP (на основе MS932) |
mathiasbynens / windows-1251: надежная реализация JavaScript кодировки символов windows-1251, как определено стандартом кодирования.
windows-1251 — это надежная реализация JavaScript кодировки символов windows-1251, как определено стандартом кодирования.
Эта кодировка известна под следующими именами: cp1251, windows-1251 и x-cp1251.
Установка
Через npm:
В браузере:
В Node.js, io.js, Narwhal и RingoJS:
var windows1251 = require ('windows-1251'); В Rhino:
Использование загрузчика AMD, например RequireJS:
требуется (
{
'paths': {
'windows-1251': 'путь / к / windows-1251'
}
},
['windows-1251'],
function (windows1251) {
приставка.журнал (windows1251);
}
); API
windows1251.версия
Строка, представляющая семантический номер версии.
окна1251 ярлыки
Массив строк, каждая из которых представляет метку для данной кодировки.
windows1251.encode (ввод, опции)
Эта функция принимает простую текстовую строку (параметр input ) и кодирует ее в соответствии с windows-1251. Возвращаемое значение — «байтовая строка», т.е.е. строка, каждый элемент которой представляет октет согласно windows-1251.
const encodedData = windows1251.encode (текст);
Дополнительный объект options и его свойство mode можно использовать для установки режима ошибки. Для кодирования режим ошибки может быть «фатальный» (по умолчанию) или «html» .
const encodedData = windows1251.encode (текст, {
'режим': 'HTML'
});
// Если `text` содержит символ, который не может быть представлен в windows-1251,
// вместо того, чтобы выдавать ошибку, он вернет объект HTML для символа. windows1251.decode (ввод, опции)
Эта функция принимает байтовую строку (параметр input ) и декодирует ее в соответствии с windows-1251.
константный текст = windows1251.decode (encodedData);
Дополнительный объект options и его свойство mode можно использовать для установки режима ошибки. Для декодирования режим ошибки может быть «замена» (по умолчанию) или «фатальный» .
const text = windows1251.декодировать (encodedData, {
'режим': 'смертельный'
});
// Если `encodedData` содержит недопустимый байт для кодировки windows-1251,
// вместо того, чтобы заменить его на U + FFFD в выводе, выдается ошибка. Для декодирования буфера (например, из fs.readFile ) используйте buffer.toString ('binary') , чтобы получить строку байтов, которую принимает decode .
Поддержка
windows-1251 предназначен для работы как минимум в Node.js v0.10.0, io.js v1.0.0, Narwhal 0.3.2, RingoJS 0.8-0.11, PhantomJS 1.9.0, Rhino 1.7RC4, а также старые и современные версии Chrome, Firefox, Safari, Opera, Edge и Internet Explorer.
Банкноты
Доступны аналогичные модули для других однобайтовых устаревших кодировок.
Автор
Лицензия
windows-1251 доступен по лицензии MIT.
черновик-winitzki-koi8c-encoding-00
Internet Draft Serge Winitzki
проект-winitzki-koi8c-кодировка-00.текст
Истекает: Апрель 2002
Расширенный набор символов кириллицы
KOI8-C
Статус этого меморандума
Эта памятка является Интернет-проектом и регулируется всеми положениями.
раздела 10 RFC2026.
Интернет-проекты - это рабочие документы Интернета.
Инженерная рабочая группа (IETF), ее области и работа
группы. Обратите внимание, что другие группы также могут распределять рабочие
документы как Интернет-проекты.
Интернет-проекты - это черновики документов, действительные не более шести лет.
месяцев и может быть обновлен, заменен или устарел другими
документы в любое время.Неуместно использовать
Интернет-проекты в качестве справочного материала или для их цитирования, кроме
как «незавершенное производство».
Со списком текущих Интернет-проектов можно ознакомиться по адресу
http://www.ietf.org/ietf/1id-abstracts.txt Список
Доступ к Интернет-черновикам теневых каталогов можно получить по адресу
http://www.ietf.org/shadow.html.
Автор
Серж Виницки
Абстрактный
В этом документе содержится информация о кодировке символов.
KOI8-C (KOI8 Cyrillic) предлагается для использования с русским языком (в том числе
старая орфография), украинский, белорусский, сербский, македонский
языки со специальными знаками препинания.KOI8-C совместим
с КОИ8-Р [1] и КОИ8-У [2] в зоне русского, украинского
и белорусскими буквами, и дополняет их буквами для старых
Русская орфография, югославские буквы кириллицы и
типографские символы в позициях, совместимых с CP1251 для использования
в устаревших приложениях.
Предлагаемое имя набора символов MIME: koi8-c
Вступление
В этом документе содержится информация о предлагаемом новом персонаже.
кодирование KOI8-C, расширение стандартов KOI8-R и KOI8-U.
Это расширение поддерживает все русские буквы.
(в том числе необходимые для древнерусской орфографии), а также
Кириллица в белорусском, македонском, сербском и белорусском языках.
Украинские языки и некоторые часто используемые типографские
символы заимствованы из кодировки CP1251.Кодировка KOI8-C
совместим с существующими кодировками KOI8-RU и CP1251 в
соответствующие персонажи.
Мотивация
Семейство кодировок KOI8 издавна используется для электронных
обмен кириллическими текстами [1,2]. Следующие соображения
заставили автора предложить расширение KOI8.
1) Большая область таблицы кодирования KOI8 (большая часть 0x80-0xBF
диапазон) по историческим причинам занят символами
псевдографика, которая не используется в современном ПО. Эти символы
отсутствуют в большинстве реализаций шрифтов KOI8 без какого-либо влияния
по производительности пользователей.Эти места в таблице кодирования могут быть
используется для представления наиболее часто используемых символов.
2) Недавнее доминирование операционной среды "MS Windows".
привело к широкому распространению текстовых процессоров, использующих код
страница 1251 "для отображения кириллицы. Многие Интернет-документы
таким образом преобразуются в KOI8 из CP1251 и часто включают
определенные типографские знаки, такие как апострофы, цитаты или
тире, не представленные в кодировках KOI8, но оставленные без
изменение автоматическими преобразователями.Эти типографские символы падают
в неиспользуемой области псевдографики KOI8.
3) Тексты в древнерусской орфографии (до 1918 г.) содержат четыре
Кириллические буквы не представлены ни одним из широко используемых
Кириллические кодировки. Хотя инструменты на основе Unicode будут в
принцип адекватен для рендеринга этих символов, текущий
программное обеспечение в основном не имеет необходимой поддержки. Это было бы
удобно иметь 8-битную кодировку, представляющую старый русский язык
символы и иметь возможность помещать их прямо в шрифт
карта кодирования и раскладка клавиатуры, совместимая с широким диапазоном
текущего программного обеспечения.Выполнение
Автор реализовал кодировку KOI8-C в соответствии с этими
рекомендации: (1) совместимость с символом KOI8-R и KOI8-U
наборов, (2) совместимость с набором символов CP1251 в области
типографские символы и югославская кириллица; (3) должно быть
умеет конвертировать шрифты в другие кодировки кириллицы.
Нижняя часть набора символов KOI8-C является полной копией
ASCII в диапазоне печатаемых символов (0x20 - 0x7F). В
диапазон (0x00 - 0x1F) занят псевдографикой и прочими
редко используются специальные символы.Верхняя часть набора символов KOI8-C содержит весь русский язык,
Белорусские и украинские буквы в позициях, определенных в KOI8-R
и КОИ8-У; часто используемые типографские символы (кавычки,
тире и символы валют) и югославской кириллицы как
определяется кодировкой CP1251; и старинные русские буквы. Большая коробка
рисование персонажей из KOI8-R, а также некоторые математические
символы, были удалены.
Результирующий набор символов содержит все символы ISO 8859-5.
кроме SOFT HYPHEN и охватывает CP1251 за исключением 5 знаков препинания
персонажей (все также в CP1252).Веб-страница
содержит авторские разработки, связанные с KOI8-C
кодировка и тексты в древнерусской орфографии. Бесплатное растровое изображение
адаптированы шрифты семейства Cronyx для оконной системы X
в кодировку KOI8-C, реализующую полную карту KOI8-C (256
символов) во всех шрифтах (проект "xcyr"). Расширение
раскладка клавиатуры, содержащая старые русские буквы, была
предложил. Словарь для проверки орфографии для древнерусского языка
орфография с использованием кодировки KOI8-C.Отношение к другим усилиям
Эта кодировка была разработана как модификация [1,2]. An
независимый проект разработки шрифтов "CYR-RFX" использует
альтернативное кодирование «КОИ8-О» с аналогичными целями
совместимость с KOI8-R и CP1251, но не содержит
Югославские символы кириллицы.
Спецификация кодовой страницы KOI8-C
Описание всех персонажей верхней половины KOI8-C
кодовая страница задается в соответствии с набором символов Unicode ISO 10646
(ПСК).
# <описание>
0x01 U25C6 # ЧЕРНЫЙ АЛМАЗ
0x02 U2592 # СРЕДНИЙ ОТТЕНК
0x03 U00D7 # ЗНАК УМНОЖЕНИЯ
0x04 U00F7 # ЗНАК РАЗДЕЛЕНИЯ
0x05 U2030 # ЗНАК НА МЕЛЬНИЦУ
0x06 U2248 # ПОЧТИ РАВНО
0x07 U00B5 # МИКРОЗНАК
0x08 U00B1 # ЗНАК ПЛЮС-МИНУС
0x09 U00B6 # ЗНАК ПИЛКРОУ
0x0A U2021 # ДВОЙНОЙ КИНЖАЛ
0x0B U2518 # ЧЕРТЕЖИ КОРОБКИ СВЕТИЛЬНИКИ ВВЕРХ И ВЛЕВО
0x0C U2510 # ЧЕРТЕЖИ НА КОРОБКЕ СВЕТЛЫЙ ВНИЗ И ВЛЕВО
0x0D U250C # ЧЕРТЕЖИ КОРОБКИ СВЕТЛЫЙ ВНИЗ И ВПРАВО
0x0E U2514 # ЧЕРТЕЖИ КОРОБКИ ГОРЯЧИМИСЯ И ВПРАВО
0x0F U253C # КОРОБКА ЧЕРТЕЖЕЙ СВЕТЛАЯ ВЕРТИКАЛЬНАЯ И ГОРИЗОНТАЛЬНАЯ
0x10 UFFFD # ХАРАКТЕР ЗАМЕНЫ
0x11 UFFFD # ХАРАКТЕР ЗАМЕНЫ
0x12 U2500 # КОРОБКА ЧЕРТЕЖЕЙ СВЕТЛАЯ ГОРИЗОНТАЛЬНАЯ
0x13 UFFFD # ХАРАКТЕР ЗАМЕНЫ
0x14 UFFFD # ХАРАКТЕР ЗАМЕНЫ
0x15 U251C # ЧЕРТЕЖИ КОРОБКИ СВЕТЛЫЕ ВЕРТИКАЛЬНО И ПРАВО
0x16 U2524 # ЧЕРТЕЖИ КОРОБКИ СВЕТЛЫЕ ВЕРТИКАЛЬНО И СЛЕВА
0x17 U2534 # ЧЕРТЕЖИ КОРОБКИ СВЕТИЛЬНО И ГОРИЗОНТАЛЬНО
0x18 U252C # ЧЕРТЕЖИ НА КОРОБКЕ СВЕТЛЫЙ ВНИЗ И ГОРИЗОНТАЛЬНО
0x19 U2502 # КОРОБКА ЧЕРТЕЖЕЙ СВЕТЛАЯ ВЕРТИКАЛЬНАЯ
0x1A U2264 # МЕНЬШЕ ИЛИ РАВНО
0x1B U2265 # БОЛЬШЕ ИЛИ РАВНО
0x1C U03C0 # ГРЕЧЕСКАЯ СТРОЧНАЯ БУКВА PI
0x1D U2260 # НЕ РАВНО
0x1E U00A4 # ЗНАК ВАЛЮТЫ
0x1F U00B2 # СУПЕРСКРИПТ ДВА
0x20 U0020 # ПРОБЕЛ
0x21 U0021 # Восклицательный знак
0x22 U0022 # ЦИТАТНЫЙ ЗНАК
0x23 U0023 # НОМЕРНЫЙ ЗНАК
0x24 U0024 # ЗНАК ДОЛЛАРА
0x25 U0025 # ЗНАК ПРОЦЕНТА
0x26 U0026 # АМПЕРСАНД
0x27 U0027 # АПОСТРОФ
0x28 U0028 # ЛЕВЫЙ ПАРЕНТЕЗ
0x29 U0029 # ПРАВЫЙ ПАРЕНТЕЗ
0x2A U002A # ASTERISK
0x2B U002B # ПЛЮС ЗНАК
0x2C U002C # ЗАПЯТАЯ
0x2D U002D # ДЕФИС-МИНУС
0x2E U002E # ПОЛНАЯ ОСТАНОВКА
0x2F U002F # SOLIDUS
0x30 U0030 # ЦИФРОВОЙ НУЛЬ
0x31 U0031 # ЦИФРА ОДИН
0x32 U0032 # ЦИФРА ДВА
0x33 U0033 # ЦИФРА ТРИ
0x34 U0034 # ЦИФРА ЧЕТЫРЕ
0x35 U0035 # ЦИФРА ПЯТЬ
0x36 U0036 # ШЕСТЬ ЦИФРОВ
0x37 U0037 # ЦИФРА СЕМЬ
0x38 U0038 # ЦИФРА ВОСЬМАЯ
0x39 U0039 # ЦИФРА ДЕВЯТЬ
0x3A U003A # COLON
0x3B U003B # СЕМИКОЛОН
0x3C U003C # МЕНЬШЕ ЗНАКА
0x3D U003D # ЗНАК РАВНО
0x3E U003E # БОЛЬШЕ, ЧЕМ ЗНАК
0x3F U003F # ВОПРОСНЫЙ ЗНАК
0x40 U0040 # КОММЕРЧЕСКИЙ АТ
0x41 U0041 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A
0x42 U0042 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА B
0x43 U0043 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА C
0x44 U0044 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА D
0x45 U0045 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E
0x46 U0046 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА F
0x47 U0047 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА G
0x48 U0048 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА H
0x49 U0049 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I
0x4A U004A # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА J
0x4B U004B # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА K
0x4C U004C # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L
0x4D U004D # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА M
0x4E U004E # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА N
0x4F U004F # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O
0x50 U0050 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА P
0x51 U0051 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Q
0x52 U0052 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА R
0x53 U0053 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА S
0x54 U0054 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА T
0x55 U0055 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U
0x56 U0056 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА V
0x57 U0057 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА W
0x58 U0058 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА X
0x59 U0059 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Y
0x5A U005A # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Z
0x5B U005B # КВАДРАТНЫЙ КРОНШТЕЙН ЛЕВЫЙ
0x5C U005C # ОБРАТНЫЙ SOLIDUS
0x5D U005D # КРОНШТЕЙН ПРАВЫЙ КВАДРАТНЫЙ
0x5E U005E # CIRCUMFLEX ACCENT
0x5F U005F # НИЗКАЯ СТРОКА
0x60 U0060 # GRAVE ACCENT
0x61 U0061 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A
0x62 U0062 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА B
0x63 U0063 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C
0x64 U0064 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА D
0x65 U0065 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E
0x66 U0066 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА F
0x67 U0067 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G
0x68 U0068 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА H
0x69 U0069 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I
0x6A U006A # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА J
0x6B U006B # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА K
0x6C U006C # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L
0x6D U006D # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА M
0x6E U006E # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N
0x6F U006F # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O
0x70 U0070 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА P
0x71 U0071 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Q
0x72 U0072 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R
0x73 U0073 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S
0x74 U0074 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА T
0x75 U0075 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U
0x76 U0076 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА V
0x77 U0077 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА W
0x78 U0078 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА X
0x79 U0079 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y
0x7A U007A # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z
0x7B U007B # КРОНШТЕЙН ЛЕВЫЙ ИЗОГНУТЫЙ
0x7C U007C # ВЕРТИКАЛЬНАЯ ЛИНИЯ
0x7D U007D # ПРАВЫЙ КРОНШТЕЙН
0x7E U007E # ТИЛЬДА
0x7F U00AC # НЕ ПОДПИСАТЬ
0x80 U0402 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА DJE
0x81 U0403 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА GJE
0x82 U00B8 # CEDILLA
0x83 U0453 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА GJE
0x84 U201E # ДВОЙНОЙ ЦИТАТНЫЙ ЗНАК НИЗКОГО-9
0x85 U2026 # ГОРИЗОНТАЛЬНЫЙ ЭЛЛИПСИС
0x86 U2020 # КИНЖАЛ
0x87 U00A7 # ЗНАК РАЗДЕЛА
0x88 U20AC # ЗНАК ЕВРО
0x89 U00A8 # ДИАРЕЗИС
0x8A U0409 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА LJE
0x8B U2039 # ОДИН ЛЕВЫЙ УГОЛ ЦИТАТЫ
0x8C U040A # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА NJE
0x8D U040C # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА KJE
0x8E U040B # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА TSHE
0x8F U040F # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ДЖЕ
0x90 U0452 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА DJE
0x91 U2018 # ОДИН ЦИТАТНЫЙ МАРК ЛЕВЫЙ
0x92 U2019 # ОДИНОЧНЫЙ ЦИТАТНЫЙ ЗНАК ПРАВЫЙ
0x93 U201C # ЛЕВЫЙ ДВОЙНОЙ ЦИТАТНЫЙ МАРК
0x94 U201D # ПРАВЫЙ ДВОЙНОЙ ЦИТАТНЫЙ МАРК
0x95 U2022 # ПУЛЯ
0x96 U2013 # EN DASH
0x97 U2014 # EM DASH
0x98 U00A3 # ЗНАК ФУНТА
0x99 U00B7 # СРЕДНЯЯ ТОЧКА
0x9A U0459 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА LJE
0x9B U203A # ОДИН УКАЗАТЕЛЬ ПРАВЫЙ УГОЛ ЦИТАТЫ
0x9C U045A # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА NJE
0x9D U045C # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА KJE
0x9E U045B # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА TSHE
0x9F U045F # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ДЖЕ
0xA0 U00A0 # ПРОБЕЛ БЕЗ ПЕРЕРЫВА
0xA1 U0475 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ИЖИЦА
0xA2 U0463 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА YAT '
0xA3 U0451 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА IO
0xA4 U0454 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА УКРАИНСКИЙ IE
0xA5 U0455 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА DZE
0xA6 U0456 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА БЕЛОРУССКО-УКРАИНСКОЕ I
0xA7 U0457 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА YI
0xA8 U0458 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА JE
0xA9 U00AE # ЗАРЕГИСТРИРОВАННЫЙ ЗНАК
0xAA U2122 # ЗНАК ТОВАРНОЙ МАРКИ
0xAB U00AB # ДВОЙНОЙ УГЛОВОЙ ЦИТАТНЫЙ МАРК, УКАЗАННЫЙ ВЛЕВО
0xAC U0473 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА FITA
0xAD U0491 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА GHE С ПОВОРОТОМ
0xAE U045E # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА КОРОТКАЯ U
0xAF U00B4 # ОСТРЫЙ АКЦЕНТ
0xB0 U00B0 # ЗНАК СТЕПЕНИ
0xB1 U0474 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ИЖИЦА
0xB2 U0462 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА YAT '
0xB3 U0401 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА IO
0xB4 U0404 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА УКРАИНСКИЙ IE
0xB5 U0405 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА DZE
0xB6 U0406 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА БЕЛОРУССКО-УКРАИНСКОЕ I
0xB7 U0407 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА YI
0xB8 U0408 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА JE
0xB9 U2116 # ЗНАК ЧИСЛА
0xBA U00A2 # ЦЕНТРАЛЬНЫЙ ЗНАК
0xBB U00BB # ДВОЙНОЙ УГЛОВОЙ ЦИТАТНЫЙ МАРК, УКАЗАННЫЙ ВПРАВО
0xBC U0472 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА FITA
0xBD U0490 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА GHE С ПОВОРОТОМ
0xBE U040E # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА КОРОТКАЯ U
0xBF U00A9 # ЗНАК АВТОРСКОГО ПРАВА
0xC0 U044E # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА YU
0xC1 U0430 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА A
0xC2 U0431 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА BE
0xC3 U0446 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА TSE
0xC4 U0434 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА DE
0xC5 U0435 # КИРИЛИЧЕСКАЯ СТРОЧНАЯ БУКВА IE
0xC6 U0444 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА EF
0xC7 U0433 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА GHE
0xC8 U0445 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА HA
0xC9 U0438 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА I
0xCA U0439 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА КОРОТКАЯ I
0xCB U043A # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА KA
0xCC U043B # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА EL
0xCD U043C # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА EM
0xCE U043D # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА EN
0xCF U043E # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА O
0xD0 U043F # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА PE
0xD1 U044F # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА YA
0xD2 U0440 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ER
0xD3 U0441 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ES
0xD4 U0442 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА TE
0xD5 U0443 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА U
0xD6 U0436 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ZHE
0xD7 U0432 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА VE
0xD8 U044C # КИРИЛИЧЕСКАЯ СТРОЧНАЯ БУКВА МЯГКИЙ ЗНАК
0xD9 U044B # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА YERU
0xDA U0437 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ZE
0xDB U0448 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА SHA
0xDC U044D # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА E
0xDD U0449 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ЩА
0xDE U0447 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА CHE
0xDF U044A # КИРИЛИЧЕСКАЯ СТРОЧНАЯ БУКВА ЖЕСТКИЙ ЗНАК
0xE0 U042E # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА YU
0xE1 U0410 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА A
0xE2 U0411 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА BE
0xE3 U0426 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА TSE
0xE4 U0414 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА DE
0xE5 U0415 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА IE
0xE6 U0424 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EF
0xE7 U0413 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА GHE
0xE8 U0425 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА HA
0xE9 U0418 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА I
0xEA U0419 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА КОРОТКАЯ I
0xEB U041A # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА KA
0xEC U041B # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EL
0xED U041C # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EM
0xEE U041D # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EN
0xEF U041E # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА O
0xF0 U041F # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА PE
0xF1 U042F # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА YA
0xF2 U0420 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ER
0xF3 U0421 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ES
0xF4 U0422 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА TE
0xF5 U0423 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА U
0xF6 U0416 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ZHE
0xF7 U0412 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА VE
0xF8 U042C # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА МЯГКИЙ ЗНАК
0xF9 U042B # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ЙЕРУ
0xFA U0417 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ZE
0xFB U0428 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА SHA
0xFC U042D # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА E
0xFD U0429 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ЩА
0xFE U0427 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА CHE
0xFF U042A # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ЖЕСТКИЙ ЗНАК
Соображения безопасности
Эта памятка не поднимает известных проблем безопасности.Благодарности
Автор благодарит Маркуса Куна (Computer Science
Лаборатория Кембриджского университета, Великобритания) за помощь в создании
Таблица кодировки KOI8-C.
Рекомендации
[1] Чернов А., «Регистрация набора символов кириллицы», RFC.
1489 г., июль 1993 г.
[2] Набор украинских символов KOI8-U, RFC 2319. 1998.
Адрес автора
Серж Виницки
4 Аризона Тер. # 2
Арлингтон, Массачусетс 02474
США
Инструмент кодирования / декодирования. Анализируйте проблемы и ошибки кодировки символов.
Что такое кодовая страница?
Кодовая страница - это еще одно название для кодировки символов. Он состоит из таблицы значений
который описывает набор символов для определенного языка.
Что такое кодировка символов?
Кодировка символов - это процесс кодирования набора символов в соответствии с системой кодирования. Этот процесс обычно объединяет числа с символами для кодирования информации, которую может использовать компьютер.
Зачем нужно кодировать символы?
Поскольку компьютеры могут интерпретировать только необработанные нули и единицы (например, 01100110), слова и предложения необходимо кодировать при вводе информации в компьютер. Символы в этих словах и предложениях сгруппированы в набор символов, который компьютер может распознать.
Что такое кодировки символов?
Кодировки символов позволяют нам понять кодировку, используемую в компьютерах. Из-за наличия множества кодировок символов могут возникать ошибки при кодировании с помощью одной кодировки символов и декодировании с помощью другой.Вышеупомянутый инструмент можно использовать для моделирования, если возникнут какие-либо ошибки при кодировании с любой кодировкой символов и декодировании с помощью другой.
Типы кодировок символов
Существует множество кодировок, которые можно использовать для кодирования или декодирования строки символов, включая UTF-8, ASCII и ISO 9959-1.
Примеры популярных кодировок символов:
- ASCII: Американский стандартный код для обмена информацией
- ANSI: Американский национальный институт стандартов
- Unicode (внутренние текстовые коды, используемые операционными системами)
- UTF -8 (формат преобразования Unicode, в котором для представления символов используется 1 байт)
- UTF-16 (формат преобразования Unicode, который использует 2 байта для представления символов)
- UTF-32 (формат преобразования Unicode, который использует 4 байта для представления символов)
Хотя это, безусловно, популярные кодировки, которые используются, бывают случаи, когда строки кода кодируются с помощью кодировок, которые не так широко используются, например x-IA5-Norgwegian или DOS-720.Это может вызвать путаницу и возможные ошибки, поэтому важно понимать, как уменьшить эти ошибки, предварительно моделируя их с помощью инструмента кодирования / декодирования символов String Functions.
Как использовать инструмент кодирования / декодирования символов
Чтобы использовать инструмент кодирования / декодирования символов String Functions, начните с ввода строки символов в текстовое поле. Затем выберите из раскрывающихся меню, какую систему кодирования и декодирования вы хотите использовать для моделирования.
Посмотрите наш индекс кодировки символов
Для просмотра таблиц кодировки от одной кодировки к другой используйте наш индекс таблицы кодировки символов.
Политика конфиденциальности
Карта сайта
окна-1251 - npm
windows-1251 - это надежная реализация JavaScript кодировки символов windows-1251, как определено стандартом кодирования.
Эта кодировка известна под следующими именами: cp1251, windows-1251 и x-cp1251.
Установка
Через npm:
npm установить windows-1251
В браузере:
В Node.js, io.js, Narwhal и RingoJS:
var windows1251 = require ('windows-1251');
В Rhino:
Использование загрузчика AMD, например RequireJS:
требуется (
{
'пути': {
'windows-1251': 'путь / к / windows-1251'
}
},
['windows-1251'],
функция (windows1251) {
console.log (windows1251);
}
);
API
окна1251.версия
Строка, представляющая семантический номер версии.
окна1251 ярлыки
Массив строк, каждая из которых представляет метку для данной кодировки.
windows1251.encode (ввод, опции)
Эта функция принимает простую текстовую строку (параметр input ) и кодирует ее в соответствии с windows-1251. Возвращаемое значение - это «байтовая строка», то есть строка, каждый элемент которой представляет октет согласно windows-1251.
const encodedData = windows1251.encode (текст);
Дополнительный объект options и его свойство mode можно использовать для установки режима ошибки. Для кодирования режим ошибки может быть «фатальный» (по умолчанию) или «html» .
const encodedData = windows1251.encode (текст, {
'mode': 'html'
});
windows1251.decode (ввод, опции)
Эта функция принимает байтовую строку (параметр input ) и декодирует ее в соответствии с windows-1251.
const text = windows1251.decode (encodedData);
Дополнительный объект options и его свойство mode можно использовать для установки режима ошибки. Для декодирования режим ошибки может быть «замена» (по умолчанию) или «фатальный» .
const text = windows1251.decode (encodedData, {
'mode': 'fatal'
});
Для декодирования буфера (например, из fs.readFile ) используйте буфер .toString ('binary') , чтобы получить байтовую строку, которую принимает decode .
Поддержка
windows-1251 предназначен для работы как минимум в Node.js v0.10.0, io.js v1.0.0, Narwhal 0.3.2, RingoJS 0.8-0.11, PhantomJS 1.9.0, Rhino 1.7RC4, а также в старых и современные версии Chrome, Firefox, Safari, Opera, Edge и Internet Explorer.
Банкноты
Доступны аналогичные модули для других однобайтовых устаревших кодировок.
Автор
Лицензия
windows-1251 доступен по лицензии MIT.
Установить набор символов по умолчанию для открытия существующих файлов
Привет, @ фримен-желтый,
У вас, наверное, стоит кодировка auto -detection . Я советую вам отключить эту функцию (Настройки > Настройки…> MISC> Автоматическое определение кодировки символов ). Итак, при открытии файла с кодировкой Cyrillic , N ++ должен использовать стандартную кодировку ANSI …
И, поскольку ваш набор символов по умолчанию , для файлов NON -Unicode, конечно же, Windows-1251 , вы должны немедленно увидеть правильные символы кириллицы , которые вы ожидаете :-))
Чтобы проверить, какая у вас конфигурация кодировки по умолчанию для не-Unicode файлов, просто откройте панель вставки ASCII ( Правка> Панель символов ).Для Windows-1251 , символы верхнего регистра кириллицы лежат между значениями кода 192 и 223 , а символы нижнего регистра кириллицы находятся между значениями кода 224 и 255 .
И если вы измените кодировку по умолчанию ANSI на кодировку Windows-1251 (Кодировка > Наборы символов> Кириллица> Windows-1251 ), список на панели вставки ASCII будет обновлен, но должен остаться без изменений !
Для быстрого перехода на кодировку Windows-1251 можно также использовать ярлык.Выберите пункт меню «Настройки »> «Сопоставитель ярлыков…»> «Главное меню»> «Windows-1251 » (строка 213 ). Я лично выбрал ярлык Crtl + Alt + E . К сожалению, есть небольшая ошибка , поскольку ярлык описание перезаписывает зону кодирования в правой части строки состояния ! Итак, новая текущая кодировка , как правило, невозможно отличить : - ((
С уважением,
парень 038
PS :
Кроме того, если вы используете параметр Настройки> Настройки> Резервное копирование> Запоминать текущий сеанс для следующего запуска , кодировка Windows-1251 ваших открытых файлов Cyillic должна быть сохранена , от одного сеанса до следующий , так как это явно , закодированный в сеансе .xml файл конфигурации ( encoding = «1251» ), если, конечно, вы сделали , а не , закрыли эти файлы, перед закрытием N ++
Странный выбор кодировки из некоторых писем при ответе windows-1251 vs. utf-8 (# 723) · Проблемы · GNOME / Geary · GitLab
Странный выбор кодировки из некоторых писем при ответе windows-1251 vs. utf-8
Сводка ошибки
Я пытаюсь ответить на письмо из списка рассылки Shotwell: https: //mail.gnome.org / archives / shotwell-list / 2020-февраль / msg00002.html
Ваша установка
Чтобы получить информацию об установке, скопируйте ее из Geary's Problem
Если отображается диалоговое окно отчета (или откройте Geary Inspector, набрав
Shift + Alt + I), выбрав Система и нажав Копировать
кнопку, затем вставьте сюда.
- Версия Geary: 3.34.2 / 3.35.90 / c205d491
- Метод установки: артефакт flathub / gnome-nightly / flatpak из конвейера, запущенного на этом хэше
- Окружение рабочего стола: GNOME
- Операционная система и версия: Ubuntu 18.04
- Провайдер электронной почты: собственный почтовый сервер
Шаги по воспроизведению
- Ответ для прессы
- Отправить на почту
- Проверить источник почты
Что случилось?
Исходное письмо состоит из нескольких частей, одна часть - Content-Type: text / plain; charset = "UTF-8", другой Ascii. Если я отвечу на него, полученное письмо будет иметь кодировку windows-1251.
Чего вы ожидали?
Используйте UTF-8
Соответствующие логи и / или скриншоты
Исходное письмо:
передач-сообщение-THL6G0.текст
Отвечать:
geary-message-ZGJ1G0.txt
Отредактировано: , Йенс Георг
.