Python 3 функции: Работаем с функциями в Python
Содержание
Работаем с функциями в Python
Функция – это структура, которую вы определяете. Вам нужно решить, будут ли в ней аргументы, или нет. Вы можете добавить как аргументы ключевых слов, так и готовые по умолчанию. Функция – это блок кода, который начинается с ключевого слова def, названия функции и двоеточия, пример:
def a_function():
print(«You just created a function!»)
def a_function(): print(«You just created a function!») |
Эта функция не делает ничего, кроме отображения текста. Чтобы вызвать функцию, вам нужно ввести название функции, за которой следует открывающаяся и закрывающаяся скобки:
a_function() # You just created a function!
a_function() # You just created a function! |
Просто, не так ли?
Пустая функция (stub)
Иногда, когда вы пишете какой-нибудь код, вам нужно просто ввести определения функции, которое не содержит в себе код. Я сделал небольшой набросок, который поможет вам увидеть, каким будет ваше приложение. Вот пример:
Я сделал небольшой набросок, который поможет вам увидеть, каким будет ваше приложение. Вот пример:
def empty_function():
pass
def empty_function(): pass |
А вот здесь кое-что новенькое: оператор pass. Это пустая операция, это означает, что когда оператор pass выполняется, не происходит ничего.
Передача аргументов функции
Теперь мы готовы узнать о том, как создать функцию, которая может получать доступ к аргументам, а также узнаем, как передать аргументы функции. Создадим простую функцию, которая может суммировать два числа:
def add(a, b):
return a + b
print( add(1, 2) ) # 3
def add(a, b): return a + b
print( add(1, 2) ) # 3 |
Каждая функция выдает определенный результат. Если вы не указываете на выдачу конкретного результата, она, тем не менее, выдаст результат None (ничего).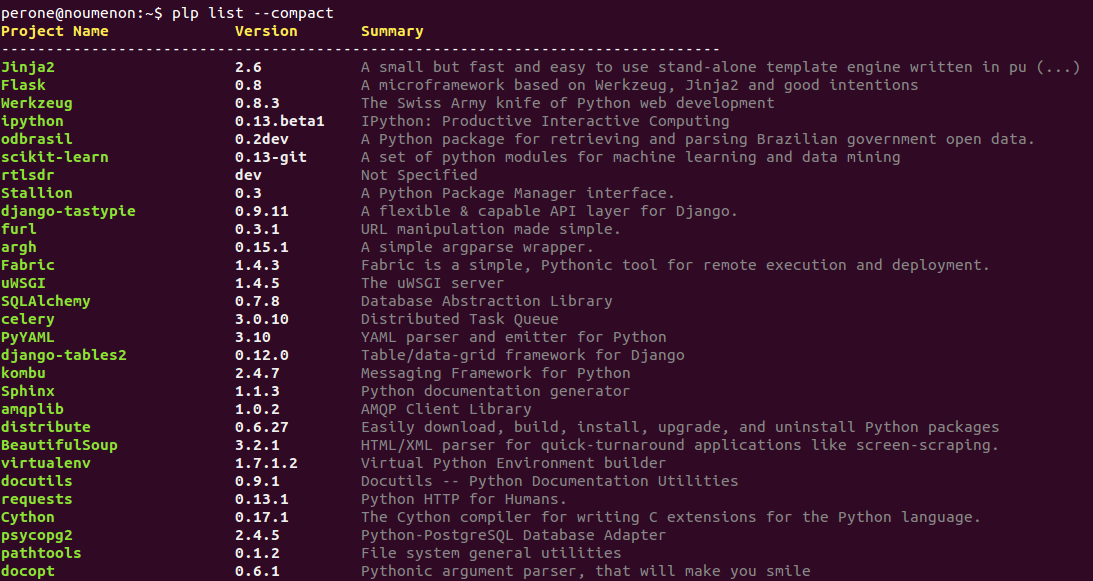 В нашем примере мы указали выдать результат a + b. Как вы видите, мы можем вызвать функцию путем передачи двух значений. Если вы передали недостаточно, или слишком много аргументов для данной функции, вы получите ошибку:
В нашем примере мы указали выдать результат a + b. Как вы видите, мы можем вызвать функцию путем передачи двух значений. Если вы передали недостаточно, или слишком много аргументов для данной функции, вы получите ошибку:
add(1)
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: add() takes exactly 2 arguments (1 given)
add(1)
Traceback (most recent call last): File «<string>», line 1, in <fragment> TypeError: add() takes exactly 2 arguments (1 given) |
Вы также можете вызвать функцию, указав наименование аргументов:
print( add(a = 2, b = 3) ) # 5
total = add(b = 4, a = 5)
print(total) # 9
print( add(a = 2, b = 3) ) # 5
total = add(b = 4, a = 5) print(total) # 9 |
Стоит отметить, что не важно, в каком порядке вы будете передавать аргументы функции до тех пор, как они называются корректно.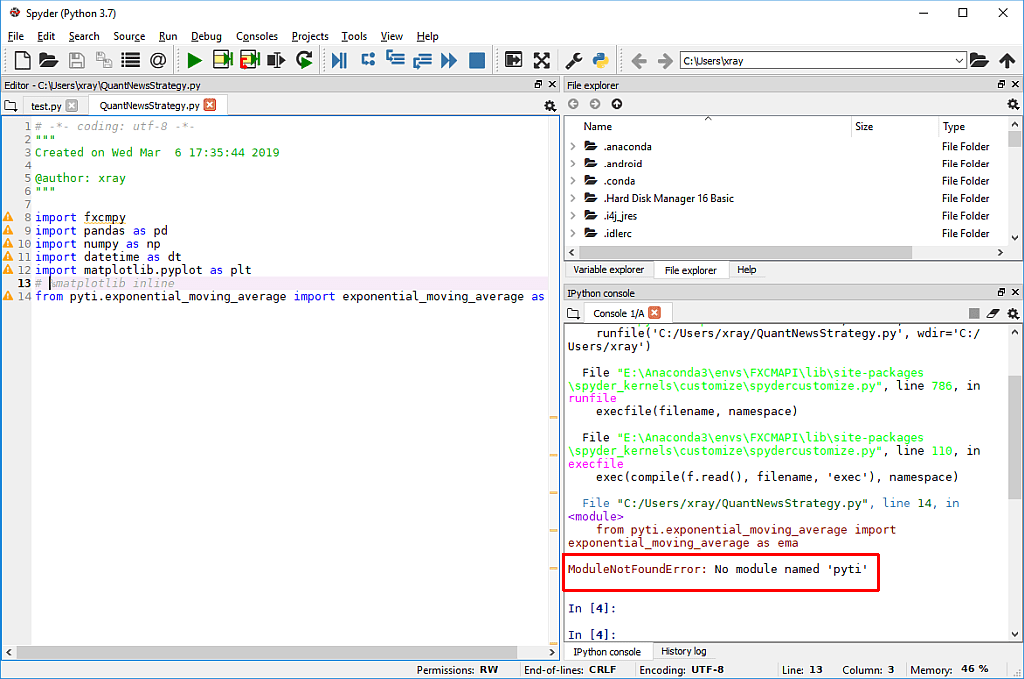 Во втором примере мы назначили результат функции переменной под названием total. Это стандартный путь вызова функции в случае, если вы хотите дальше использовать её результат.
Во втором примере мы назначили результат функции переменной под названием total. Это стандартный путь вызова функции в случае, если вы хотите дальше использовать её результат.
Вы, возможно, подумаете: «А что, собственно, произойдет, если мы укажем аргументы, но они названы неправильно? Это сработает?» Давайте попробуем на примере:
add(c=5, d=2)
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: add() got an unexpected keyword argument ‘c’
add(c=5, d=2)
Traceback (most recent call last): File «<string>», line 1, in <fragment> TypeError: add() got an unexpected keyword argument ‘c’ |
Ошибка. Кто бы мог подумать? Это значит, что мы указали ключевой аргумент, который функция не распознала. Кстати, ключевые аргументы описана ниже.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК.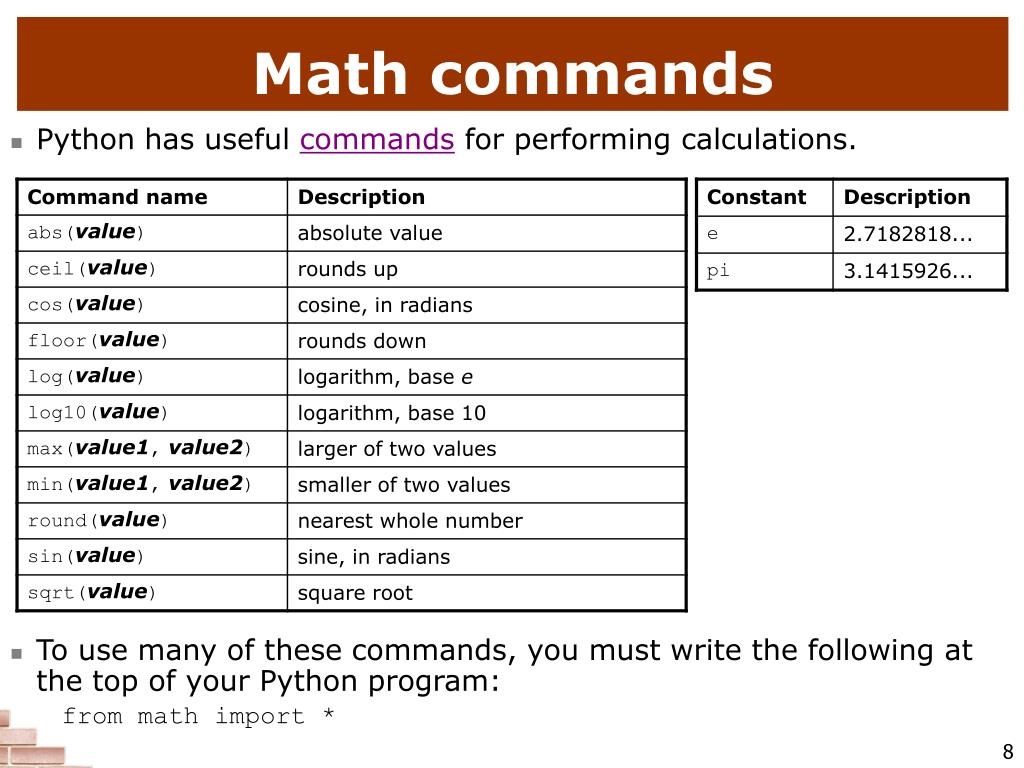 Видео уроки и книги для вас!
Видео уроки и книги для вас!
Ключевые аргументы
Функции также могут принимать ключевые аргументы. Более того, они могут принимать как регулярные, так и ключевые аргументы. Это значит, что вы можете указывать, какие ключевые слова будут ключевыми, и передать их функции. Это было в примере выше.
def keyword_function(a=1, b=2):
return a+b
print( keyword_function(b=4, a=5) ) # 9
def keyword_function(a=1, b=2): return a+b
print( keyword_function(b=4, a=5) ) # 9 |
Вы также можете вызвать данную функцию без спецификации ключевых слов. Эта функция также демонстрирует концепт аргументов, используемых по умолчанию. Каким образом? Попробуйте вызвать функцию без аргументов вообще!
Функция вернулась к нам с числом 3. Почему? Причина заключается в том, что а и b по умолчанию имеют значение 1 и 2 соответственно. Теперь попробуем создать функцию, которая имеет обычный аргумент, и несколько ключевых аргументов:
Теперь попробуем создать функцию, которая имеет обычный аргумент, и несколько ключевых аргументов:
def mixed_function(a, b=2, c=3):
return a+b+c
mixed_function(b=4, c=5)
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: mixed_function() takes at least 1 argument (2 given)
def mixed_function(a, b=2, c=3): return a+b+c
mixed_function(b=4, c=5)
Traceback (most recent call last): File «<string>», line 1, in <fragment> TypeError: mixed_function() takes at least 1 argument (2 given) |
print( mixed_function(1, b=4, c=5) ) # 10
print( mixed_function(1) ) # 6
print( mixed_function(1, b=4, c=5) ) # 10
print( mixed_function(1) ) # 6 |
Выше мы описали три возможных случая. Проанализируем каждый из них.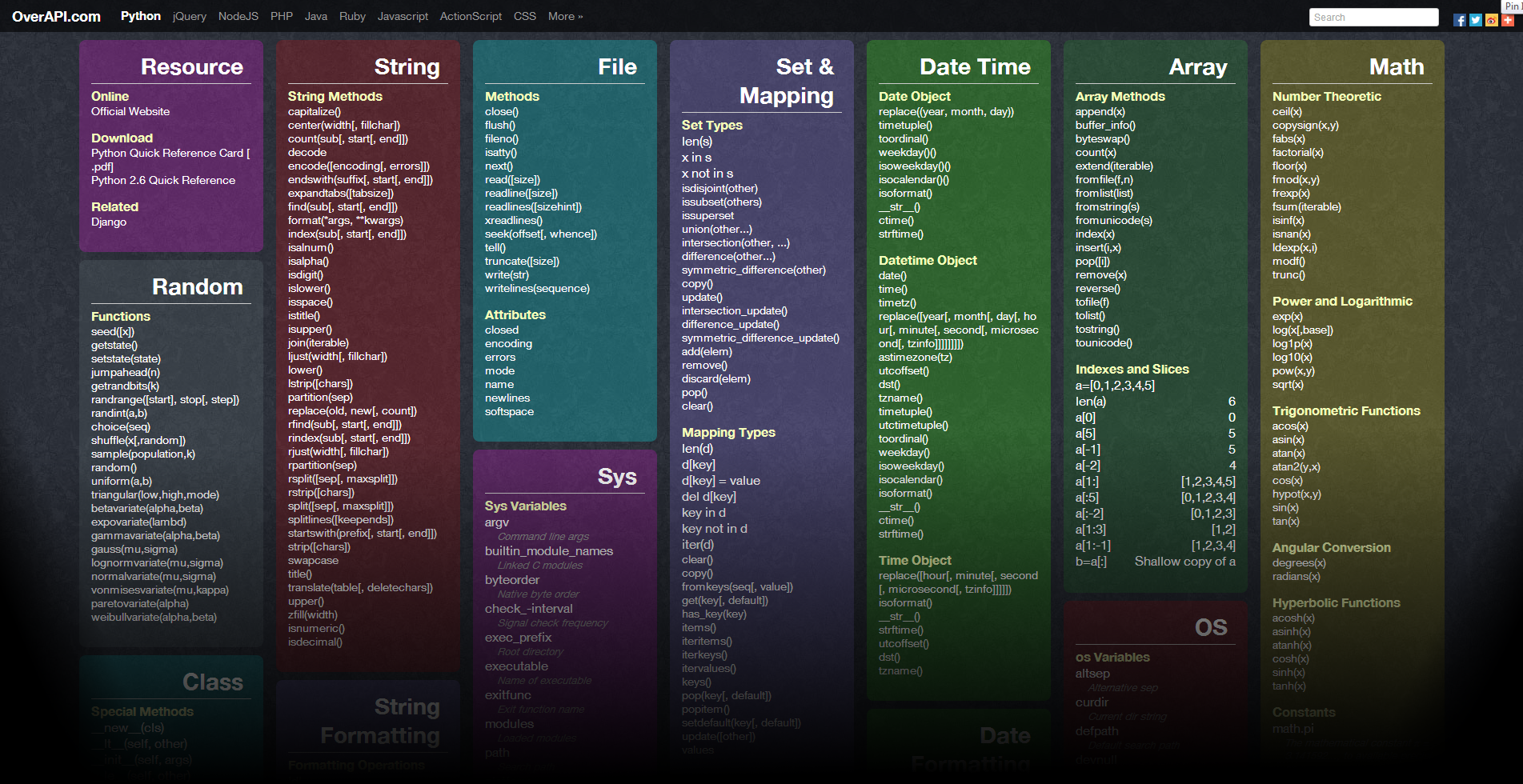 В первом примере мы попробовали вызвать функцию, используя только ключевые аргументы. Это дало нам только ошибку. Traceback указывает на то, что наша функция принимает, по крайней мере, один аргумент, но в примере было указано два аргумента. Что же произошло? Дело в том, что первый аргумент необходим, потому что он ни на что не указывает, так что, когда мы вызываем функцию только с ключевыми аргументами, это вызывает ошибку. Во втором примере мы вызвали смешанную функцию, с тремя значениями, два из которых имеют название. Это работает, и выдает нам ожидаемый результат: 1+4+5=10. Третий пример показывает, что происходит, если мы вызываем функцию, указывая только на одно значение, которое не рассматривается как значение по умолчанию. Это работает, если мы берем 1, и суммируем её к двум значениям по умолчанию: 2 и 3, чтобы получить результат 6! Удивительно, не так ли?
В первом примере мы попробовали вызвать функцию, используя только ключевые аргументы. Это дало нам только ошибку. Traceback указывает на то, что наша функция принимает, по крайней мере, один аргумент, но в примере было указано два аргумента. Что же произошло? Дело в том, что первый аргумент необходим, потому что он ни на что не указывает, так что, когда мы вызываем функцию только с ключевыми аргументами, это вызывает ошибку. Во втором примере мы вызвали смешанную функцию, с тремя значениями, два из которых имеют название. Это работает, и выдает нам ожидаемый результат: 1+4+5=10. Третий пример показывает, что происходит, если мы вызываем функцию, указывая только на одно значение, которое не рассматривается как значение по умолчанию. Это работает, если мы берем 1, и суммируем её к двум значениям по умолчанию: 2 и 3, чтобы получить результат 6! Удивительно, не так ли?
*args и **kwargs
Вы также можете настроить функцию на прием любого количества аргументов, или ключевых аргументов, при помощи особого синтаксиса. Чтобы получить бесконечное количество аргументов, мы используем *args, а чтобы получить бесконечное количество ключевых аргументов, мы используем *kwargs. Сами слова “args” и “kwargs” не так важны. Это просто сокращение. Вы можете назвать их *lol и *omg, и они будут работать таким же образом. Главное здесь – это количество звездочек. Обратите внимание: в дополнение к конвенциям *args и *kwargs, вы также, время от времени, будете видеть andkw. Давайте взглянем на следующий пример:
Чтобы получить бесконечное количество аргументов, мы используем *args, а чтобы получить бесконечное количество ключевых аргументов, мы используем *kwargs. Сами слова “args” и “kwargs” не так важны. Это просто сокращение. Вы можете назвать их *lol и *omg, и они будут работать таким же образом. Главное здесь – это количество звездочек. Обратите внимание: в дополнение к конвенциям *args и *kwargs, вы также, время от времени, будете видеть andkw. Давайте взглянем на следующий пример:
def many(*args, **kwargs):
print( args )
print( kwargs )
many(1, 2, 3, name=»Mike», job=»programmer»)
# Результат:
# (1, 2, 3)
# {‘job’: ‘programmer’, ‘name’: ‘Mike’}
def many(*args, **kwargs): print( args ) print( kwargs )
many(1, 2, 3, name=»Mike», job=»programmer»)
# Результат: # (1, 2, 3) # {‘job’: ‘programmer’, ‘name’: ‘Mike’} |
Сначала мы создали нашу функцию, при помощи нового синтаксиса, после чего мы вызвали его при помощи трех обычных аргументов, и двух ключевых аргументов. Функция показывает нам два типа аргументов. Как мы видим, параметр args превращается в кортеж, а kwargs – в словарь. Вы встретите такой тип кодинга, если взгляните на исходный код Пайтона, или в один из сторонних пакетов Пайтон.
Функция показывает нам два типа аргументов. Как мы видим, параметр args превращается в кортеж, а kwargs – в словарь. Вы встретите такой тип кодинга, если взгляните на исходный код Пайтона, или в один из сторонних пакетов Пайтон.
Область видимость и глобальные переменные
Концепт области (scope) в Пайтон такой же, как и в большей части языков программирования. Область видимости указывает нам, когда и где переменная может быть использована. Если мы определяем переменные внутри функции, эти переменные могут быть использованы только внутри это функции. Когда функция заканчиваются, их можно больше не использовать, так как они находятся вне области видимости. Давайте взглянем на пример:
def function_a():
a = 1
b = 2
return a+b
def function_b():
c = 3
return a+c
print( function_a() )
print( function_b() )
def function_a(): a = 1 b = 2 return a+b
def function_b(): c = 3 return a+c
print( function_a() ) print( function_b() ) |
Если вы запустите этот код, вы получите ошибку:
NameError: global name ‘a’ is not defined
NameError: global name ‘a’ is not defined |
Это вызвано тем, что переменная определенна только внутри первой функции, но не во второй. Вы можете обойти этот момент, указав в Пайтоне, что переменная а – глобальная (global). Давайте взглянем на то, как это работает:
Вы можете обойти этот момент, указав в Пайтоне, что переменная а – глобальная (global). Давайте взглянем на то, как это работает:
def function_a():
global a
a = 1
b = 2
return a+b
def function_b():
c = 3
return a+c
print( function_a() )
print( function_b() )
def function_a(): global a a = 1 b = 2 return a+b
def function_b(): c = 3 return a+c
print( function_a() ) print( function_b() ) |
Этот код работает, так как мы указали Пайтону сделать а – глобальной переменной, а это значит, что она работает где-либо в программе. Из этого вытекает, что это настолько же хорошая идея, насколько и плохая. Причина, по которой эта идея – плохая в том, что нам становится трудно сказать, когда и где переменная была определена. Другая проблема заключается в следующем: когда мы определяем «а» как глобальную в одном месте, мы можем случайно переопределить её значение в другом, что может вызвать логическую ошибку, которую не просто исправить.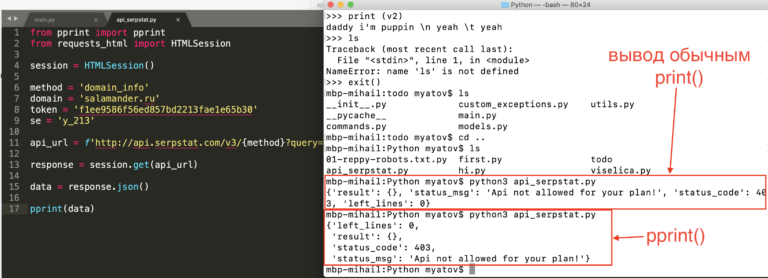
Советы в написании кода
Одна из самых больших проблем для молодых программистов – это усвоить правило «не повторяй сам себя». Суть в том, что вы не должны писать один и тот же код несколько раз. Когда вы это делаете, вы знаете, что кусок кода должен идти в функцию. Одна из основных причин для этого заключается в том, что вам, вероятно, придется снова изменить этот фрагмент кода в будущем, и если он будет находиться в нескольких местах, вам нужно будет помнить, где все эти местоположения И изменить их.
Сайт doctorsmm.com предлагает Вам персональные предложения по покупке лайков в ВК к постам и публикациям. Здесь Вы найдете дешевые цены на услуги, а также различные критерии, подходящие к любой ситуации. На сервисе также доступно приобретение репостов, голосов в голосования и опросы сети.
Копировать и вставлять один и тот же кусок кода – хороший пример спагетти-кода. Постарайтесь избегать этого так часто, как только получится. Вы будете сожалеть об этом в какой-то момент либо потому, что вам придется все это исправлять, либо потому, что вы столкнетесь с чужим кодом, с которым вам придется работать и исправлять вот это вот всё.
Вы будете сожалеть об этом в какой-то момент либо потому, что вам придется все это исправлять, либо потому, что вы столкнетесь с чужим кодом, с которым вам придется работать и исправлять вот это вот всё.
Подведем итоги
Теперь вы обладаете основательными знаниями, которые необходимы для эффективной работы с функциями. Попрактикуйтесь в создании простых функций, и попробуйте обращаться к ним различными способами.
Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: [email protected]
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
10 удивительно полезных базовых функций Python / Блог компании Skillbox / Хабр
Те, кто работает с Python, знают, что этот язык хорош благодаря своей обширной экосистеме. Можно даже сказать, что язык программирования не выделялся бы ничем особенным, если бы не его замечательные пакеты, которые добавляют новые функции к основным.
Можно даже сказать, что язык программирования не выделялся бы ничем особенным, если бы не его замечательные пакеты, которые добавляют новые функции к основным.
В качестве примера можно привести NumPy. Инструменты работы с матрицами хороши и в базовом Python, но использование NumPy улучшает все во много раз. Кроме того, у этого языка есть несколько крутых возможностей, которые делают его еще более функциональным. Используя эти возможности, вы можете уменьшить количество зависимостей, освободить время и упростить сам процесс разработки. Давайте посмотрим, что это за возможности.
Кстати, свои советы по некоторым функциям добавил Алексей Некрасов — лидер направления Python в МТС, программный директор направления Python в Skillbox. Чтобы было понятно, где перевод, а где — комментарии, последние мы выделим текстом.
№1 lambda
Я как-то написал целую статью о том, почему lambda делает Python оптимальным языком программирования для статистических вычислений. Благодаря этой функции математические операции можно применить практически к любому типу данных, используя не целые функции, а оценку выражений.
Благодаря этой функции математические операции можно применить практически к любому типу данных, используя не целые функции, а оценку выражений.
Она позволяет вводить определения в глобальном масштабе, а также использовать functional-like синтаксис и методологию, причем на языке, у которого все еще есть структура классов.
Все это позволяет сэкономить время в ходе написания программы, сохранить ресурсы и сделать код более лаконичным. Более того, lambda дает возможность использовать такие методы, как apply() для быстрого применения выражений ко всем подмножествам данных. Для дата-сайентиста, да и не только для представителей этой профессии, подобные возможности крайне полезны.
Синтаксис выглядит следующим образом. Начинаем со значения, равного возвращению lambda-выражения, затем следует переменная, которую мы хотели бы предоставить в качестве позиционного аргумента. После этого выполняем операцию, используя этот аргумент в качестве переменной:
mean = lambda x : sum(x) / len(x)Теперь мы можем осуществить вызов, как и в случае с любым другим методом в Python:
x = [5, 10, 15, 20]
print(mean(x))Комментарий Алексея:
Будьте аккуратнее с lambda, чтобы не ухудшить читаемость кода.
Вот пара советов:
Из PEP8. Всегда используйте оператор def вместо оператора присваивания, который связывает лямбда-выражение напрямую с идентификатором:Правильно:
def f (x): return 2 * xНеправильно:
f = lambda x: 2 * x
Если длина lambda выражения больше 40 символов, то скорее всего вы засунули в одну строчку кода слишком много логики и она стала нечитабельна. Так делать не стоит, лучше вынести в отдельную функцию.
 Вот пара советов:
Вот пара советов:№2: Shutil
Модуль Shutil — один из наиболее недооцененных инструментов в арсенале Python. Он включен в стандартную библиотеку, и может быть импортирован так же, как и любой другой модуль в языке:
import shutil Что же делает shutil? На самом деле, это интерфейс высокого уровня для языка программирования Python, в отношении файловой системы вашей ОС. Эти вызовы часто выполняются с использованием модуля os, об shutil не стоит забывать. Вероятно, вам приходилось перемещать файл из каталога в каталог при помощи скрипта, проделав для этого массу утомительной работы, верно?
Вероятно, вам приходилось перемещать файл из каталога в каталог при помощи скрипта, проделав для этого массу утомительной работы, верно?
Shutil решает эти классические проблемы с файлами и таблицами размещения (allocation tables) при помощи высокоуровневого решения. Это — ключ для экономии времени и ускорению операций с файлами. Вот несколько примеров высокоуровневых вызовов, которые предоставляет shutil.
import shutil
shutil.copyfile('mydatabase.db', 'archive.db')
shutil.move('/src/High.py', '/packages/High')№3: glob
Возможно, glob и не такой классный, как shutil, плюс он и рядом не стоял с lambda в плане полезности. Но он незаменим в некоторых случаях. Этот модуль используется для поиска директорий для wildcards. Это означает, что его можно использовать для агрегирования данных о файлах на вашем ПК и их расширениях. Импортируется модуль без проблем:
import glob Я не уверен, есть ли у этого модуля еще функции, но glob() — то, что нужно для выполнения поиска файлов. В ходе поиска используется синтаксис Unix, т.е. т.е. *, / и т. д.
В ходе поиска используется синтаксис Unix, т.е. т.е. *, / и т. д.
glob.glob('*.ipynb')Эта строка возвращает все имена файлов соответствующих указанному запросу. Использовать функцию можно как для агрегирования данных, так и просто для работы с файлами.
№4: argparse
Этот модуль предоставляет надежный и глубокий метод анализа аргументов командной строки. Многие инструменты разработки используют эту концепцию, работать со всем этим можно при помощи командной строки Unix. Отличный пример — Python Gunicorn, обрабатывающий переданные аргументы командной строки. Для начала работы с модулем его нужно импортировать.
import argparseЗатем, чтобы получить возможность работать с ним, строим новый тип, это будет парсер аргументов:
parser = argparse.ArgumentParser(prog = 'top',
description = 'Show top lines from the file')Ну а теперь мы добавляем новые аргументы в наш парсер. В этом случае создаем аргумент, который можно передать для определения количества строк, которые мы хотим вывести для каждого файла:
parser. add_argument('-l', '--lines', type=int, default=10) add_argument('-l', '--lines', type=int, default=10)
add_argument('-l', '--lines', type=int, default=10)Здесь добавлено несколько аргументов ключевого слова, один из которых предоставит тип данных, который передается для этого аргумента, а другой — значение по умолчанию, когда файл вызывается без этого аргумента. Теперь мы можем получить аргументы, вызвав функцию parse_args () для нашего нового типа парсера аргументов:
args = parser.parse_args()Теперь мы можем вызвать этот файл Python для компиляции, а также легко предоставить необходимые параметры из Bash.
python top.py --lines=5 examplefile.txtИзлишне говорить, что это определенно может пригодиться. Я часто использовал этот модуль при работе с Crontab. Он может запускать скрипты с определенными временными метками Unix. Кроме того, этот сценарий также можно использовать для супервизоров, которые запускают команды Bash без участия пользователя в качестве worker.
№5: import re
Еще один крайне недооцененный модуль. Модуль re используется для синтаксического анализа строк с помощью регулярных выражений и предоставляет больше возможностей для работы со строками в Python. Сколько раз вы сталкивались с принятием алгоритмических решений на основе функций, которые есть в строковом классе, например str.split ()? Но хватит это терпеть! Ведь регулярные выражения намного проще и их намного проще использовать!
Модуль re используется для синтаксического анализа строк с помощью регулярных выражений и предоставляет больше возможностей для работы со строками в Python. Сколько раз вы сталкивались с принятием алгоритмических решений на основе функций, которые есть в строковом классе, например str.split ()? Но хватит это терпеть! Ведь регулярные выражения намного проще и их намного проще использовать!
import reМодуль re, в отличие от некоторых других в этом списке, предоставляет не одну, а множество крайне полезных функций. Они особенно актуальны для работы с большими объемами данных, что важно для дата-саентистов. Вот два примера, с которых стоит начать, — это функции sub () и findall ().
import re
re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest')
['foot', 'fell', 'fastest']
re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat')
'cat in the hat'Комментарий Алексея:
При написании любых regex в коде придерживаться следующих правил:
- re.
M{0,3} # thousands — 0 to 3 Ms
(CM|CD|D?C{0,3}) # hundreds — 900 (CM), 400 (CD), 0-300 (0 to 3 Cs),
# or 500-800 (D, followed by 0 to 3 Cs)
(XC|XL|L?X{0,3}) # tens — 90 (XC), 40 (XL), 0-30 (0 to 3 Xs),
# or 50-80 (L, followed by 0 to 3 Xs)
(IX|IV|V?I{0,3}) # ones — 9 (IX), 4 (IV), 0-3 (0 to 3 Is),
# or 5-8 (V, followed by 0 to 3 Is)
$ # end of string
»’
re.search(pattern, ‘M’, re.VERBOSE)
- Использовать python raw string для записи regex.
- Named capture group для всех capture group, если их больше чем одна (?P…). (даже если одна capture, тоже лучше использовать)
regex101.com отличный сайт для дебага и проверки regex
 # beginning of string
# beginning of string№6: Math
Это не величайший модуль в истории, но часто он полезен. Математический модуль дает доступ ко всему, от sin и cos до логарифмов. Все это крайне важно при работе с алгоритмами.
Все это крайне важно при работе с алгоритмами.
import mathМодуль, безусловно, может сэкономить некоторое время, сделав математические операции доступными без зависимостей. В этом примере я продемонстрирую функцию log (), но если вы углубитесь в модуль, то вам откроется целый мир.
import math
math.log(1024, 2)№7: Statistics
Еще один модуль, который крайне полезен для статистических подсчетов. Он дает доступ к базовой статистике — не такой глубокой, как в случае SCiPy, но и ее может быть достаточно для анализа данных. Alias этого модуля — st, в некоторых случаях — stc или sts. Но, внимание — не scs, это уже alias для Scipy.stats.
import statistics as stЭтот модуль предоставляет множество полезных функций, на которые стоит обратить внимание! Самое замечательное в этом пакете то, здесь нет никаких зависимостей. Давайте оценим некоторые основные статистические операции общего назначения:
import statistics as st
st. mean(data)
st.median(data)
st.variance(data) mean(data)
st.median(data)
st.variance(data)
mean(data)
st.median(data)
st.variance(data)№8: urllib
Если многие другие модули из этого списка не очень известны, то urlib — исключение. Давайте импортируем его!
import urllibВместо него можно использовать Flask, поскольку он более функционален. Но для большинства базовых функций хватает и возможностей стандартной библиотеки, которая дает возможность не беспокоиться о зависимостях. Конечно, если нужны дополнительные возможности — то в этом случае стоит обратить внимание уже на что-то другое. Но если речь об HTTP-запросе, то urlib сделает то, что нужно.
from urllib.request import urlopen
data = null
with urlopen('http://example_url/') as response: data = responseМодуль urlib — то, что я крайне рекомендую изучить дополнительно.
№9: datetime
Еще один отличный пример инструмента, который довольно часто встречается в научных вычислениях, — это тип «дата и время». Очень часто у данных есть отметки времени.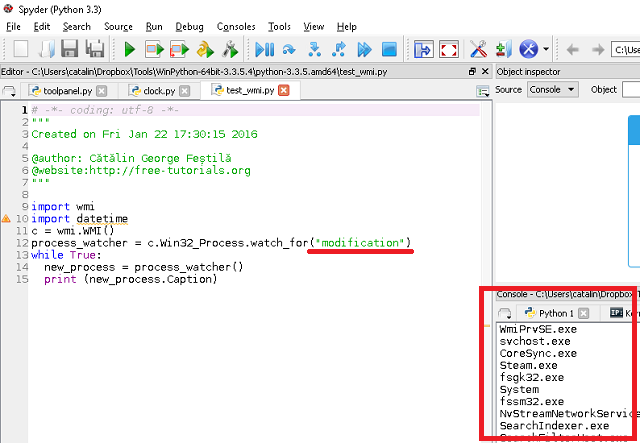 Иногда они даже являются прогностической функцией, используемой для обучения модели. Этот модуль часто используется с алиасом dt:
Иногда они даже являются прогностической функцией, используемой для обучения модели. Этот модуль часто используется с алиасом dt:
import datetime as dtТеперь мы можем создавать типы даты и времени и работать с типичным синтаксисом даты и времени со свойствами, включая год, месяц и день. Это невероятно полезно для переформатирования, анализа и работы с отдельными разделами дат в ваших данных. Давайте посмотрим на некоторые основные функции этого пакета:
import datetime as dt
now = dt.date.today()
print(now.year)
print(now.month)№10: zlib
Последний участник этого списка — модуль zlib. Это универсальное решение для сжатия данных с использованием языка программирования Python. Модуль крайне полезен при работе с пакетами.
import zlibНаиболее важные функции здесь — compress() and decompress().
h = " Hello, it is me, you're friend Emmett!"print(len(h))
t = zlib.compress(h)
print(len(t))
z = decompress(t)
print(len(z))В качестве вывода скажу, что программирование на Python иногда кажется сложным из-за большого количества зависимостей. И стандартная библиотека языка позволяет частично избавиться от этой проблемы. Кроме того, стандартные инструменты Python позволяют экономить время, уменьшить объем кода и сделать его более читаемым.
Мир Python: функционалим по-маленьку — Python для продвинутых
Введение
Существует несколько парадигм в программировании, например, ООП, функциональная, императивная, логическая, да много их. Мы будем говорить про функциональное программирование.
Предпосылками для полноценного функционального программирования в Python являются: функции высших порядков, развитые средства обработки списков, рекурсия, возможность организации ленивых вычислений.
Сегодня познакомимся с простыми элементами, а сложные конструкции будут в других уроках.
Теория в теории
Как и в разговоре об ООП, так и о функциональном программировании, мы стараемся избегать определений. Все-таки четкое определение дать тяжело, поэтому здесь четкого определения не будет. Однако! Хотелки для функционального языка выделим:
- Функции высшего порядка
- Чистые функции
- Неизменяемые данные
Это не полный список, но даже этого хватает чтобы сделать «красиво». Если читателю хочется больше, то вот расширенный список:
- Функции высшего порядка
- Чистые функции
- Неизменяемые данные
- Замыкания
- Ленивость
- Хвостовая рекурсия
- Алгебраические типы данных
- Pattern matching
Постепенно рассмотрим все эти моменты и как использовать в Python.
А сегодня кратко, что есть что в первом списке.
Чистые функции
Чистые функции не производят никаких наблюдаемых побочных эффектов, только возвращают результат. Не меняют глобальных переменных, ничего никуда не посылают и не печатают, не трогают объектов, и так далее. Принимают данные, что-то вычисляют, учитывая только аргументы, и возвращают новые данные.
Плюсы:
- Легче читать и понимать код
- Легче тестировать (не надо создавать «условий»)
- Надежнее, потому что не зависят от «погоды» и состояния окружения, только от аргументов
- Можно запускать параллельно, можно кешировать результат
Неизменяемые данные
Неизменяемые (иммутабельные) структуры данных — это коллекции, которые нельзя изменить. Примерно как числа. Число просто есть, его нельзя поменять. Также и неизменяемый массив — он такой, каким его создали, и всегда таким будет. Если нужно добавить элемент — придется создать новый массив.
Преимущества неизменяемых структур:
- Безопасно разделять ссылку между потоками
- Легко тестировать
- Легко отследить жизненный цикл (соответствует data flow)
theory-source
Функции высшего порядка
Функцию, принимающую другую функцию в качестве аргумента и/или возвращающую другую функцию, называют функцией высшего порядка:
def f(x):
return x + 3
def g(function, x):
return function(x) * function(x)
print(g(f, 7))
Рассмотрели теорию, начнем переходить к практике, от простого к сложному.
Списковые включения или генератор списка
Рассмотрим одну конструкцию языка, которая поможет сократить количество строк кода. Не редко уровень программиста на Python можно определить с помощью этой конструкции.
Пример кода:
for x in xrange(5, 10):
if x % 2 == 0:
x =* 2
else:
x += 1
Цикл с условием, подобные встречаются не редко. А теперь попробуем эти 5 строк превратить в одну:
>>> [x * 2 if x % 2 == 0 else x + 1 for x in xrange(5, 10)]
[6, 12, 8, 16, 10]
Недурно, 5 строк или 1. Причем выразительность повысилась и такой код проще понимать — один комментарий можно на всякий случай добавить.
В общем виде эта конструкция такова:
[stmt for var in iterable if predicate]
Стоит понимать, что если код совсем не читаем, то лучше отказаться от такой конструкции.
Анонимные функции или lambda
Продолжаем сокращать количества кода.
Функция:
def calc(x, y):
return x**2 + y**2
Функция короткая, а как минимум 2 строки потратили. Можно ли сократить такие маленькие функции? А может не оформлять в виде функций? Ведь, не всегда хочется плодить лишние функции в модуле. А если функция занимает одну строчку, то и подавно. Поэтому в языках программирования встречаются анонимные функции, которые не имеют названия.
Анонимные функции в Python реализуются с помощью лямбда-исчисления и выглядят как лямбда-выражения:
>>> lambda x, y: x**2 + y**2
<function <lambda> at 0x7fb6e34ce5f0>
Для программиста это такие же функции и с ними можно также работать.
Чтобы обращаться к анонимным функциям несколько раз, присваиваем переменной и пользуемся на здоровье.
Пример:
>>> (lambda x, y: x**2 + y**2)(1, 4)
17
>>>
>>> func = lambda x, y: x**2 + y**2
>>> func(1, 4)
17
Лямбда-функции могут выступать в качестве аргумента. Даже для других лямбд:
multiplier = lambda n: lambda k: n*k
Использование lambda
Функции без названия научились создавать, а где использовать сейчас узнаем. Стандартная библиотека предоставляет несколько функций, которые могут принимать в качестве аргумента функцию — map(), filter(), reduce(), apply().
map()
Функция map() обрабатывает одну или несколько последовательностей с помощью заданной функции.
>>> list1 = [7, 2, 3, 10, 12]
>>> list2 = [-1, 1, -5, 4, 6]
>>> list(map(lambda x, y: x*y, list1, list2))
[-7, 2, -15, 40, 72]
Мы уже познакомились с генератором списков, давайте им воспользуемся, если длина список одинаковая:
>>> [x*y for x, y in zip(list1, list2)]
[-7, 2, -15, 40, 72]
Итак, заметно, что использование списковых включений короче, но лямбды более гибкие. Пойдем дальше.
filter()
Функция filter() позволяет фильтровать значения последовательности. В результирующем списке только те значения, для которых значение функции для элемента истинно:
>>> numbers = [10, 4, 2, -1, 6]
>>> list(filter(lambda x: x < 5, numbers)) # В результат попадают только те элементы x, для которых x < 5 истинно
[4, 2, -1]
То же самое с помощью списковых выражений:
>>> numbers = [10, 4, 2, -1, 6]
>>> [x for x in numbers if x < 5]
[4, 2, -1]
reduce()
Для организации цепочечных вычислений в списке можно использовать функцию reduce(). Например, произведение элементов списка может быть вычислено так (Python 2):
>>> numbers = [2, 3, 4, 5, 6]
>>> reduce(lambda res, x: res*x, numbers, 1)
720
Вычисления происходят в следующем порядке:
((((1*2)*3)*4)*5)*6
Цепочка вызовов связывается с помощью промежуточного результата (res). Если список пустой, просто используется третий параметр (в случае произведения нуля множителей это 1):
>>> reduce(lambda res, x: res*x, [], 1)
1
Разумеется, промежуточный результат необязательно число. Это может быть любой другой тип данных, в том числе и список. Следующий пример показывает реверс списка:
>>> reduce(lambda res, x: [x]+res, [1, 2, 3, 4], [])
[4, 3, 2, 1]
Для наиболее распространенных операций в Python есть встроенные функции:
>>> numbers = [1, 2, 3, 4, 5]
>>> sum(numbers)
15
>>> list(reversed(numbers))
[5, 4, 3, 2, 1]
В Python 3 встроенной функции reduce() нет, но её можно найти в модуле functools.
apply()
Функция для применения другой функции к позиционным и именованным аргументам, заданным списком и словарем соответственно (Python 2):
>>> def f(x, y, z, a=None, b=None):
... print x, y, z, a, b
...
>>> apply(f, [1, 2, 3], {'a': 4, 'b': 5})
1 2 3 4 5
В Python 3 вместо функции apply() следует использовать специальный синтаксис:
>>> def f(x, y, z, a=None, b=None):
... print(x, y, z, a, b)
...
>>> f(*[1, 2, 3], **{'a': 4, 'b': 5})
1 2 3 4 5
На этой встроенной функции закончим обзор стандартной библиотеки и перейдем к последнему на сегодня функциональному подходу.
Замыкания
Функции, определяемые внутри других функций, представляют собой замыкания. Зачем это нужно? Рассмотрим пример, который объяснит:
Код (вымышленный):
def processing(element, type_filter, all_data_size):
filters = Filter(all_data_size, type_filter).get_all()
for filt in filters:
element = filt.filter(element)
def main():
data = DataStorage().get_all_data()
for x in data:
processing(x, 'all', len(data))
Что можно в коде заметить: в этом коде переменные, которые живут по сути постоянно (т.е. одинаковые), но при этом мы загружаем или инициализируем по несколько раз. В итоге приходит понимание, что инициализация переменной занимает львиную долю времени в этом процессе, бывает что даже загрузка переменных в scope уменьшает производительность. Чтобы уменьшить накладные расходы необходимо использовать замыкания.
В замыкании однажды инициализируются переменные, которые затем без накладных расходов можно использовать.
Научимся оформлять замыкания:
def multiplier(n):
"multiplier(n) возвращает функцию, умножающую на n"
def mul(k):
return n*k
return mul
# того же эффекта можно добиться выражением
# multiplier = lambda n: lambda k: n*k
mul2 = multiplier(2) # mul2 - функция, умножающая на 2, например,
mul2(5) == 10
Заключение
В уроке мы рассмотрели базовые понятия ФП, а также составили список механизмов, которые будут рассмотрены в следующих уроках. Поговорили о способах уменьшения количества кода, таких как cписковые включения (генератор списка), lamda функции и их использовании и на последок было несколько слов про замыкания и для чего они нужны.
Остались вопросы? Задайте их в разделе «Обсуждение»
Вам ответят команда поддержки Хекслета или другие студенты.
Ошибки, сложный материал, вопросы >
Нашли опечатку или неточность?
Выделите текст, нажмите
ctrl + enter
и отправьте его нам. В течение нескольких дней мы исправим ошибку или улучшим формулировку.
Что-то не получается или материал кажется сложным?
Загляните в раздел «Обсуждение»:
- задайте вопрос. Вы быстрее справитесь с трудностями и прокачаете навык постановки правильных вопросов, что пригодится и в учёбе, и в работе программистом;
- расскажите о своих впечатлениях. Если курс слишком сложный, подробный отзыв поможет нам сделать его лучше;
- изучите вопросы других учеников и ответы на них. Это база знаний, которой можно и нужно пользоваться.
Об обучении на Хекслете
Строки. Функции и методы строк — Документация Python Summary 1
# Литералы строк
S = 'str'; S = "str"; S = '''str'''; S = """str"""
# Экранированные последовательности
S = "s\np\ta\nbbb"
# Неформатированные строки (подавляют экранирование)
S = r"C:\temp\new"
# Строка байтов
S = b"byte"
# Конкатенация (сложение строк)
S1 + S2
# Повторение строки
S1 * 3
# Обращение по индексу
S[i]
# Извлечение среза
S[i:j:step]
# Длина строки
len(S)
# Поиск подстроки в строке. Возвращает номер первого вхождения или -1
S.find(str, [start],[end])
# Поиск подстроки в строке. Возвращает номер последнего вхождения или -1
S.rfind(str, [start],[end])
# Поиск подстроки в строке. Возвращает номер первого вхождения или вызывает ValueError
S.index(str, [start],[end])
# Поиск подстроки в строке. Возвращает номер последнего вхождения или вызывает ValueError
S.rindex(str, [start],[end])
# Замена шаблона
S.replace(шаблон, замена)
# Разбиение строки по разделителю
S.split(символ)
# Состоит ли строка из цифр
S.isdigit()
# Состоит ли строка из букв
S.isalpha()
# Состоит ли строка из цифр или букв
S.isalnum()
# Состоит ли строка из символов в нижнем регистре
S.islower()
# Состоит ли строка из символов в верхнем регистре
S.isupper()
# Состоит ли строка из неотображаемых символов (пробел, символ перевода страницы ('\f'), "новая строка" ('\n'), "перевод каретки" ('\r'), "горизонтальная табуляция" ('\t') и "вертикальная табуляция" ('\v'))
S.isspace()
# Начинаются ли слова в строке с заглавной буквы
S.istitle()
# Преобразование строки к верхнему регистру
S.upper()
# Преобразование строки к нижнему регистру
S.lower()
# Начинается ли строка S с шаблона str
S.startswith(str)
# Заканчивается ли строка S шаблоном str
S.endswith(str)
# Сборка строки из списка с разделителем S
S.join(список)
# Символ в его код ASCII
ord(символ)
# Код ASCII в символ
chr(число)
# Переводит первый символ строки в верхний регистр, а все остальные в нижний
S.capitalize()
# Возвращает отцентрованную строку, по краям которой стоит символ fill (пробел по умолчанию)
S.center(width, [fill])
# Возвращает количество непересекающихся вхождений подстроки в диапазоне [начало, конец] (0 и длина строки по умолчанию)
S.count(str, [start],[end])
# Возвращает копию строки, в которой все символы табуляции заменяются одним или несколькими пробелами, в зависимости от текущего столбца. Если TabSize не указан, размер табуляции полагается равным 8 пробелам
S.expandtabs([tabsize])
# Удаление пробельных символов в начале строки
S.lstrip([chars])
# Удаление пробельных символов в конце строки
S.rstrip([chars])
# Удаление пробельных символов в начале и в конце строки
S.strip([chars])
# Возвращает кортеж, содержащий часть перед первым шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий саму строку, а затем две пустых строки
S.partition(шаблон)
# Возвращает кортеж, содержащий часть перед последним шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий две пустых строки, а затем саму строку
S.rpartition(sep)
# Переводит символы нижнего регистра в верхний, а верхнего – в нижний
S.swapcase()
# Первую букву каждого слова переводит в верхний регистр, а все остальные в нижний
S.title()
# Делает длину строки не меньшей width, по необходимости заполняя первые символы нулями
S.zfill(width)
# Делает длину строки не меньшей width, по необходимости заполняя последние символы символом fillchar
S.ljust(width, fillchar=" ")
# Делает длину строки не меньшей width, по необходимости заполняя первые символы символом fillchar
S.rjust(width, fillchar=" ")
Создание (определение) функции — Python
Пора научиться создавать собственные функции! Код, в котором создаётся функция, называется определением функции.
Вот шаблон определения простой функции:
def имя_функции():
# тело функции, т.е. код
print("abc")
Определение собственных функций значительно упрощает написание и поддержку программ. Функции позволяют объединять сложные (составные) операции в одну. Например, отправка письма на сайте — это достаточно сложный процесс, включающий в себя взаимодействие с внешними системами (интернет). Благодаря возможности определять функции, вся сложность может быть скрыта за простой функцией:
from some-email-package import send
email = '[email protected]'
title = 'Помогите'
body = 'Я написал историю успеха, как я могу получить скидку?'
# Один маленький вызов — и много логики внутри
send(email, title, body)
Здесь мы в первый раз сталкиваемся с новым элементом синтаксиса — блоками инструкций. В Python несколько инструкций, объединённых по смыслу в некотоpyю группу — блок — записываются с отступом в четыре пробела. Блок всегда заканчивается перед первой строчкой, которая имеет отступ меньший, чем строчки блока. В примере выше тело функции — это блок.
Создадим нашу первую функцию. У неё будет одна задача: выводить на экран текст Today is: December 5.
Нужно назвать функцию так, чтобы из названия была понятна её задача. Давайте дадим ей имя show_date():
# Определение функции
# Определение не вызывает функцию
# Мы лишь говорим, что теперь такая функция существует
def show_date():
text = 'Today is: December 5'
print(text)
В нашей функции только две строчки кода, но их может быть сколько угодно. Функции можно считать программами внутри программ.
Чтобы на 100% понять происходящее, обязательно сделайте следующее:
- Зайдите на https://repl.it/languages/python3. Это онлайн-интерпретатор Python.
- В левой части введите код примера выше.
- Запустите программу нажатием на «RUN ▶».
- Программа выполнится, но на экран ничего не выведется, потому что в программе есть только определение функции, но не запуск.
- Чтобы запустить функцию, нужно вызвать её. Добавьте к программе вызов:
show_date() # => Today is: December 5
- Запустите программу снова и удостоверьтесь, что в правой части на экран вывелся текст.
Соберём всё вместе. Вот полная программа, с определением функции и вызовом:
def show_date():
text = 'Today is: December 5'
print(text)
show_date()
Today is: December 5
Понятие «создать функцию» имеет много синонимов: «реализовать», «определить» и даже «заимплементить» (от слова implement). Все они встречаются в повседневной практике на работе.
Задание
Реализуйте функцию print_motto(), которая печатает на экран фразу Winter is coming.
print_motto() # => Winter is coming
Важное замечание! В задачах, в которых нужно реализовать функцию, эту функцию вызывать не нужно. Вызывать функцию будут автоматизированные тесты, которые проверяют ее работоспособность. Пример с вызовом выше показан только для того, чтобы вы понимали, как ваша функция будет использоваться.
Советы
Нашли ошибку? Есть что добавить? Пулреквесты приветствуются https://github.com/hexlet-basics
Справочник разработчика Python. Функции Azure
-
- Чтение занимает 15 мин
В этой статье
В этой статье содержатся общие сведения о разработке Функций Azure с помощью Python. Предполагается, что вы уже прочли руководство для разработчиков Функций Azure.
Разработчик Python может также заинтересоваться одной из следующих статей:
Модель программирования
Функция Azure должна быть реализована как метод без отслеживания состояния в сценарии Python, который обрабатывает входные данные и создает выходные данные. По умолчанию среда выполнения ожидает, что метод реализован как глобальный метод с именем main() в файле __init__.py. Также можно указать альтернативную точку входа.
Данные из триггеров и привязок будут привязаны к функции через атрибуты метода с помощью свойства name, определяемого в файле function.json. Пример файла function.json ниже описывает простую функцию с именем req, которая активируется HTTP-запросом.
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
На основе этого определения файл __init__.py, содержащий код функции, может выглядеть, как в следующем примере:
def main(req):
user = req.params.get('user')
return f'Hello, {user}!'
Также можно явно объявить для функции типы атрибутов и тип возвращаемого значения с помощью аннотации типов Python. Это помогает использовать функции IntelliSense и автозаполнения, предоставляемые во многих редакторах кода Python.
import azure.functions
def main(req: azure.functions.HttpRequest) -> str:
user = req.params.get('user')
return f'Hello, {user}!'
Аннотации Python, включенные в пакет azure.functions.*, позволяют привязать входные и выходные данные к методам.
Альтернативная точка входа
Можно изменить поведение функции по умолчанию, при необходимости указав свойства scriptFile и entryPoint в файле function.json. Пример файла function.json ниже указывает, что среда выполнения должна использовать метод customentry() из файла main.py в качестве точки входа для Функции Azure.
{
"scriptFile": "main.py",
"entryPoint": "customentry",
"bindings": [
...
]
}
Структура папок
Рекомендуемая структура папок для проекта Функций на Python выглядит следующим образом:
<project_root>/
| - .venv/
| - .vscode/
| - my_first_function/
| | - __init__.py
| | - function.json
| | - example.py
| - my_second_function/
| | - __init__.py
| | - function.json
| - shared_code/
| | - __init__.py
| | - my_first_helper_function.py
| | - my_second_helper_function.py
| - tests/
| | - test_my_second_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
В главной папке проекта (<project_root>) могут содержаться следующие файлы:
- local.settings.json: используется для хранения параметров приложения и строк подключения при локальном выполнении. Этот файл не публикуется в Azure. Дополнительные сведения см. в разделе local.settings.file.
- requirements.txt: содержит список пакетов, которые должны быть установлены при публикации в Azure.
- host.json: содержит параметры глобальной конфигурации, влияющие на все функции в приложении-функции. Этот файл не публикуется в Azure. При локальном запуске поддерживаются не все параметры. Дополнительные сведения см. в разделе host.json.
- .vscode/ : (Дополнительно) Содержит конфигурацию хранилища VSCode. Дополнительные сведения см. в разделе параметр VSCode.
- .venv/ : (необязательно) Содержит виртуальную среду Python, используемую локальной разработкой.
- Dockerfile: (необязательно) используется при публикации проекта в настраиваемом контейнере.
- tests/ : (необязательно) Содержит тест-кейсы для вашего приложения-функции.
- .funcignore: (необязательно) объявляет файлы, которые не должны публиковаться в Azure. Как правило, этот файл содержит,
.vscode/чтобы игнорировать параметр редактора, игнорировать.venv/локальные виртуальные среды Python,tests/игнорировать тестовые случаи иlocal.settings.jsonпредотвратить публикацию параметров локального приложения.
У каждой функции есть собственный файл кода и файл конфигурации привязки.
При развертывании проекта в приложении-функции Azure следует включить в пакет все содержимое главной папки ( <project_root> ), но не саму эту папку. Это означает, что в корне пакета должен быть host.json. Тесты рекомендуется хранить в папке вместе с другими функциями (в этом примере — tests/). Дополнительные сведения см. в разделе Модульное тестирование.
Поведение при импорте
Вы можете импортировать модули в код функции, используя явные относительные и абсолютные ссылки. В соответствии со структурой папок, показанной выше, следующие операции импорта работают в файле функции <project_root>\my_first_function\__init__.py:
from shared_code import my_first_helper_function #(absolute)
import shared_code.my_second_helper_function #(absolute)
from . import example #(relative)
Примечание
Папка shared_code/ должна содержать файл __init__.py, чтобы пометить его как пакет Python при использовании абсолютного синтаксиса импорта.
Следующий импорт _ _приложения _ _ и относительный импорт верхнего уровня являются устаревшими, так как он не поддерживается средством проверки статических типов и не поддерживается платформами тестирования Python.
from __app__.shared_code import my_first_helper_function #(deprecated __app__ import)
from ..shared_code import my_first_helper_function #(deprecated beyond top-level relative import)
Триггеры и входные данные
Входные данные в Функциях Azure делятся на две категории: входные данные триггеров и дополнительные входные данные. Они по-разному представлены в файле function.json, но использование в коде Python полностью идентично. Строки подключения или секреты для триггеров и источников входных данных сопоставляются со значениями в файле local.settings.json при выполнении в локальной среде и с параметрами приложения при выполнении в Azure.
В следующем примере кода показано различие:
// function.json
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous",
"route": "items/{id}"
},
{
"name": "obj",
"direction": "in",
"type": "blob",
"path": "samples/{id}",
"connection": "AzureWebJobsStorage"
}
]
}
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# __init__.py
import azure.functions as func
import logging
def main(req: func.HttpRequest,
obj: func.InputStream):
logging.info(f'Python HTTP triggered function processed: {obj.read()}')
При активации этой функции HTTP-запрос передается в функцию с помощью req. Запись извлекается из хранилища BLOB-объектов Azure по значению ID, включенному в URL-адрес маршрута, и становится доступной в виде obj в тексте функции. Здесь указанная учетная запись хранения является строкой подключения в параметре приложения AzureWebJobsStorage, которая является той же учетной записью хранения, используемой приложением-функцией.
Выходные данные
Выходные данные можно выразить как возвращаемое значение или параметры вывода. Если используется только один вывод, мы рекомендуем использовать возвращаемое значение. Для нескольких выводов нужно использовать параметры вывода.
Чтобы использовать возвращаемое значение функции в качестве значения выходной привязки, присвойте свойству name значение $return в function.json.
Чтобы создать несколько выходных значений, используйте метод set() из интерфейса azure.functions.Out, чтобы присвоить значение привязке. Например, следующая функция может направлять сообщение в очередь и возвращает ответ HTTP.
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous"
},
{
"name": "msg",
"direction": "out",
"type": "queue",
"queueName": "outqueue",
"connection": "AzureWebJobsStorage"
},
{
"name": "$return",
"direction": "out",
"type": "http"
}
]
}
import azure.functions as func
def main(req: func.HttpRequest,
msg: func.Out[func.QueueMessage]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Logging
Доступ к средству ведения журнала среды выполнения Функций Azure предоставляется через корневой обработчик logging в приложении-функции. Это средство ведения журнала привязано к Application Insights и позволяет отмечать предупреждения и ошибки, возникшие во время выполнения функции.
Следующий пример сохраняет в журнал информационное сообщение, когда функция вызывается с помощью триггера HTTP.
import logging
def main(req):
logging.info('Python HTTP trigger function processed a request.')
Доступны и другие методы ведения журнала, которые позволяют выводить сообщения в консоль на разных уровнях трассировки.
| Метод | Описание |
|---|---|
critical(_message_) | Записывает сообщение с уровнем CRITICAL в корневое средство ведения журнала. |
error(_message_) | Записывает сообщение с уровнем ERROR в корневое средство ведения журнала. |
warning(_message_) | Записывает сообщение с уровнем WARNING в корневое средство ведения журнала. |
info(_message_) | Записывает сообщение с уровнем INFO в корневое средство ведения журнала. |
debug(_message_) | Записывает сообщение с уровнем DEBUG в корневое средство ведения журнала. |
Дополнительные сведения о ведении журналов см. в статье Мониторинг Функций Azure.
Триггеры и привязки HTTP
Триггер HTTP определяется в файле function.json. name привязки должен соответствовать именованному параметру в функции.
В предыдущих примерах используется имя привязки req. Этот параметр является объектом HttpRequest, и возвращается объект HttpResponse.
Из объекта HttpRequest можно получить заголовки запроса, параметры запроса, параметры маршрута и текст сообщения.
Следующий пример относится к шаблону триггера HTTP для Python.
def main(req: func.HttpRequest) -> func.HttpResponse:
headers = {"my-http-header": "some-value"}
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello {name}!", headers=headers)
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
headers=headers, status_code=400
)
В этой функции значение параметра запроса name получено из параметра params объекта HttpRequest. Текст сообщения в кодировке JSON считывается с помощью метода get_json.
Аналогичным образом можно задать status_code и headers для ответного сообщения в возвращенном объекте HttpResponse.
Масштабирование и производительность
Рекомендации по масштабированию и повышению производительности для приложений функций Python см. в статье масштабирование и производительность Python.
Контекст
Чтобы получить контекст вызова функции во время выполнения, включите в его подпись аргумент context.
Пример:
import azure.functions
def main(req: azure.functions.HttpRequest,
context: azure.functions.Context) -> str:
return f'{context.invocation_id}'
Класс Context имеет следующие строковые атрибуты:
function_directory Каталог, в котором выполняется функция.
function_name Имя функции.
invocation_id Идентификатор текущего вызова функции.
Глобальные переменные
Не гарантируется, что состояние приложения будет сохранено для будущих выполнений. Однако среда выполнения Функций Azure часто использует один и тот же процесс для нескольких выполнений одного и того же приложения. Чтобы кэшировать результаты ресурсоемких вычислений, объявите ее как глобальную переменную.
CACHED_DATA = None
def main(req):
global CACHED_DATA
if CACHED_DATA is None:
CACHED_DATA = load_json()
# ... use CACHED_DATA in code
Переменные среды
В Функциях параметры приложения, такие как строки подключения службы, доступны в виде переменных среды во время выполнения. Доступ к этим параметрам можно получить, объявив import os, а затем воспользовавшись setting = os.environ["setting-name"].
В следующем примере показано получение параметра приложения с ключом с именем myAppSetting:
import logging
import os
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
Для локальной разработки параметры приложения хранятся в файле local.settings.json.
Версия Python
Функции Azure поддерживают следующие версии Python:
| Версия службы «Функции» | Версии* Python |
|---|---|
| 3.x | 3.9 (предварительный просмотр) 3.8 3,7 3.6 |
| 2.x | 3,7 3.6 |
*Официальные дистрибутивы CPython
Чтобы запросить конкретную версию Python при создании приложения-функции в Azure, используйте параметр --runtime-version команды az functionapp create. Версия среды выполнения функций задается параметром --functions-version. Версия Python задается при создании приложения-функции и изменить ее невозможно.
При локальном запуске среда выполнения использует доступную версию Python.
Управление пакетами
При локальной разработке с помощью Azure Functions Core Tools или Visual Studio Code добавьте имена и версии требуемых пакетов в файл requirements.txt и установите их с помощью pip.
Например, представленные ниже файл требований и команда pip позволяют установить пакет requests из PyPI.
requests==2.19.1
pip install -r requirements.txt
Публикация в Azure
Когда все будет готово к публикации, убедитесь, что все общедоступные зависимости перечислены в файле требований requirements.txt, который находится в корне каталога проекта.
Файлы и папки проекта, исключаемые из публикации, включая папку виртуальной среды, перечислены в файле .funcignore.
Для публикации проекта Python в Azure поддерживаются три действия сборки: удаленная сборка, локальная сборка и сборки с использованием пользовательских зависимостей.
Вы также можете использовать Azure Pipelines для создания зависимостей и публикации с помощью непрерывной поставки (CD). Дополнительные сведения см. в статье непрерывная поставка с помощью Azure DevOps.
Удаленная сборка
При использовании удаленной сборки зависимости, восстановленные на сервере и в машинных зависимостях, соответствуют рабочей среде. Это приводит к уменьшению размера пакета развертывания. Используйте удаленную сборку при разработке приложений Python в Windows. Если в проекте есть пользовательские зависимости, можно использовать удаленную сборку с дополнительным URL-адресом индекса.
Зависимости получаются удаленно на основе содержимого файла requirements.txt. В качестве рекомендуемого метода сборки рекомендуется использовать удаленную сборку. По умолчанию Azure Functions Core Tools запрашивает удаленную сборку при использовании следующей команды func azure functionapp publish для публикации проекта Python в Azure.
func azure functionapp publish <APP_NAME>
Не забудьте заменить <APP_NAME> именем приложения-функции, размещенного в Azure.
Расширение Функций Azure для Visual Studio Code также запрашивает удаленную сборку по умолчанию.
Локальная сборка
Зависимости получаются локально на основе содержимого файла requirements.txt. Вы можете запретить удаленную сборку, используя следующую команду func azure functionapp publish для публикации с локальной сборкой.
func azure functionapp publish <APP_NAME> --build local
Не забудьте заменить <APP_NAME> именем приложения-функции, размещенного в Azure.
С помощью параметра --build local зависимости проекта считываются из файла требований requirements.txt, и эти зависимые пакеты загружаются и устанавливаются локально. Файлы проекта и зависимости развертываются с локального компьютера в Azure. Это приводит к увеличению пакета развертывания, отправляемого в Azure. Если по какой-то причине зависимости в файле requirements.txt не удается получить с помощью основных инструментов, для публикации необходимо использовать настраиваемые зависимости.
При локальной разработке в Windows не рекомендуется использовать локальные сборки.
Настраиваемые зависимости.
Если проект содержит зависимости, не найденные в индексе пакета Python, существуют два способа построения проекта. Метод сборки зависит от способа сборки проекта.
Удаленная сборка с дополнительным URL-адресом индекса
Если пакеты доступны из доступного индекса настраиваемого пакета, используйте удаленную сборку. Перед публикацией обязательно Создайте параметр приложения с именем PIP_EXTRA_INDEX_URL. Значение этого параметра — это URL-адрес пользовательского индекса пакета. Использование этого параметра указывает, что удаленная сборка будет выполняться pip install с --extra-index-url параметром. Дополнительные сведения см. в документации по установке для Python PIP.
Вы также можете использовать учетные данные обычной проверки подлинности с дополнительными URL-адресами индексов пакетов. Дополнительные сведения см. в разделе основные учетные данные проверки подлинности в документации по Python.
Установка локальных пакетов
Если в проекте используются пакеты, которые не являются общедоступными для наших инструментов, их можно сделать доступными для приложения, поместив их в каталог __app__/.python_packages. Перед публикацией выполните следующую команду, чтобы установить зависимости локально:
pip install --target="<PROJECT_DIR>/.python_packages/lib/site-packages" -r requirements.txt
При использовании пользовательских зависимостей следует использовать параметр публикации --no-build, поскольку вы уже установили зависимости.
func azure functionapp publish <APP_NAME> --no-build
Не забудьте заменить <APP_NAME> именем приложения-функции, размещенного в Azure.
Модульное тестирование
Функции, написанные на языке Python, можно тестировать так же, как и другой код Python, используя стандартные платформы тестирования. Для большинства привязок можно создать макет объекта ввода, создав экземпляр соответствующего класса из пакета azure.functions. Поскольку пакет azure.functions может быть недоступен, обязательно установите его с помощью файла requirements.txt, как описано в разделе Управление пакетами выше.
Например, my_second_function как пример имитации тестирования функции для триггеров HTTP:
Сначала необходимо создать <project_root>/my_second_function/function.jsв файле и определить эту функцию как триггер HTTP.
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Теперь мы можем реализовать my_second_function и shared_code.my_second_helper_function.
# <project_root>/my_second_function/__init__.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
# Define an http trigger which accepts ?value=<int> query parameter
# Double the value and return the result in HttpResponse
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Мы можем приступить к написанию тестовых случаев для триггера HTTP.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from my_second_function import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(
method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
resp = main(req)
# Check the output.
self.assertEqual(
resp.get_body(),
b'21 * 2 = 42',
)
В .venv виртуальной среде Python установите любимую платформу тестирования Python (например, pip install pytest). Просто выполните команду pytest tests, чтобы проверить результат теста.
Временные файлы
Метод tempfile.gettempdir() возвращает временную папку, которая в Linux — /tmp. Приложение может использовать этот каталог для хранения временных файлов, создаваемых и используемых вашими функциями во время выполнения.
Важно!
Файлы, записанные во временный каталог, не всегда сохраняются между вызовами. Во время масштабирования временные файлы не используются совместно экземплярами.
Следующий пример создает именованный временный файл во временном каталоге (/tmp):
import logging
import azure.functions as func
import tempfile
from os import listdir
#---
tempFilePath = tempfile.gettempdir()
fp = tempfile.NamedTemporaryFile()
fp.write(b'Hello world!')
filesDirListInTemp = listdir(tempFilePath)
Тесты рекомендуется хранить в папке, отдельной от папки проекта. Это позволяет не развертывать тестовый код в приложении.
Предустановленные библиотеки
Существует несколько библиотек со средой выполнения функций Python.
Стандартная библиотека Python
Стандартная библиотека Python содержит список встроенных модулей Python, поставляемых вместе с каждым дистрибутивом Python. Большинство этих библиотек помогают получить доступ к функциональным возможностям системы, таким как файловый ввод-вывод. В системах Windows эти библиотеки устанавливаются с Python. В системах на базе UNIX они предоставляются коллекциями пакетов.
Чтобы просмотреть полные сведения о списке этих библиотек, перейдите по ссылкам ниже:
Зависимости рабочих ролей Python в функциях Azure
Работнику функций Python требуется конкретный набор библиотек. Эти библиотеки также можно использовать в функциях, но они не являются частью стандарта Python. Если функции зависят от этих библиотек, они могут быть недоступны коду при выполнении вне функций Azure. Подробный список зависимостей можно найти в разделе Установка _ требуется в файле Setup.py.
Примечание
Если requirements.txt приложения функции содержит azure-functions-worker запись, удалите ее. Работник функций автоматически управляется платформой функций Azure и регулярно обновляется новыми функциями и исправлениями ошибок. Ручная установка старой версии рабочей роли в requirements.txt может привести к непредвиденным проблемам.
Библиотека Python для функций Azure
Каждое обновление рабочей роли Python включает новую версию библиотеки Python для функций Azure (azure.functions). Такой подход упрощает непрерывное обновление приложений-функций Python, так как каждое обновление имеет обратную совместимость. Список выпусков этой библиотеки можно найти в Azure-функциях PyPi.
Версия библиотеки среды выполнения исправлена в Azure и не может быть переопределена requirements.txt. azure-functionsЗапись в requirements.txt относится только к linting и осведомленности клиентов.
Используйте следующий код для отслеживания фактической версии библиотеки функций Python в среде выполнения:
getattr(azure.functions, '__version__', '< 1.2.1')
Системные библиотеки среды выполнения
Список предустановленных системных библиотек в образах DOCKER Worker в Python см. по следующим ссылкам:
Предоставление общего доступа к ресурсам независимо от источника
Функции Azure поддерживают общий доступ к ресурсам независимо от источника (CORS). CORS настраивается на портале и через Azure CLI. Список разрешенных источников CORS применяется на уровне приложения-функции. При включении CORS ответы включают заголовок Access-Control-Allow-Origin. Дополнительные сведения см. в статье об общем доступе к ресурсам независимо от источника.
CORS полностью поддерживается для приложений-функций Python.
Известные проблемы и часто задаваемые вопросы
Ниже приведен список руководств по устранению распространенных проблем.
Все известные проблемы и запросы возможностей отслеживаются в списке проблем на GitHub. Если вы столкнулись с проблемой и не можете найти ее решение на GitHub, откройте новую проблему и укажите ее подробное описание.
Дальнейшие действия
Для получения дополнительных сведений см. следующие ресурсы:
Возникли проблемы? Сообщите нам!
Functions and recursion — Learn Python 3
Напомним, что в математике факториал числа n определяется как n! = 1 ⋅ 2 ⋅ … ⋅ n (как произведение всех целых чисел от 1 до n). Например, 5! = 1 ⋅ 2 ⋅ 3 ⋅ 4 ⋅ 5 = 120. Ясно, что факториал легко вычислить, используя цикл for. Представьте, что нам нужно в нашей программе несколько раз вычислить факториал разных чисел (или в разных местах кода). Конечно, вы можете написать вычисление факториала один раз, а затем с помощью Copy-Paste вставить его туда, где вам это нужно:
None
# вычислить 3!
res = 1
for i in range(1, 4):
res *= i
print(res)
# вычислить 5!
res = 1
for i in range(1, 6):
res *= i
print(res)
Однако, если мы допустим ошибку в исходном коде, этот ошибочный код появится во всех местах, где мы скопировали вычисление факториала. Более того, код длиннее, чем может быть. Чтобы избежать повторной записи той же логики в языках программирования, существуют функции.
Функции — это секции кода, которые изолированы от остальной части программы и выполняются только при вызове. Вы уже встретили функции sqrt() , len() и print() . Все они имеют что-то общее: они могут принимать параметры (ноль, один или несколько из них), и они могут возвращать значение (хотя они могут и не возвращаться). Например, функция sqrt() принимает один параметр и возвращает значение (квадратный корень из заданного числа). Функция print() может принимать различное количество аргументов и ничего не возвращает.
Теперь мы хотим показать вам, как написать функцию factorial() которая принимает один параметр — число и возвращает значение — факториал этого числа.
None
def factorial(n):
res = 1
for i in range(1, n + 1):
res *= i
return res
print(factorial(3))
print(factorial(5))
Мы хотим дать несколько объяснений. Во-первых, код функции должен быть помещен в начало программы (до места, где мы хотим использовать функцию factorial() , если быть точным). Первая строка def factorial(n): из этого примера является описанием нашей функции; слово factorial является идентификатором (имя нашей функции). Сразу после идентификатора появляется список параметров, которые получает наша функция (в скобках). Список состоит из разделенных запятыми идентификаторов параметров; в нашем случае список состоит из одного параметра n . В конце строки поместите двоеточие.
Затем идет тело функции. В Python тело должно быть отступом (по Tab или четыре пробела, как всегда). Эта функция вычисляет значение n! и сохраняет его в переменной res . Последней строкой функции является return res , которая выходит из функции и возвращает значение переменной res .
Оператор return может отображаться в любом месте функции. Его выполнение завершает функцию и возвращает указанное значение в место, где была вызвана функция. Если функция не возвращает значение, оператор return фактически не возвращает какое-либо значение (хотя оно все еще может быть использовано). Некоторым функциям не нужно возвращать значения, и оператор return может быть опущен для них.
Мы хотели бы привести еще один пример. Вот функция max() которая принимает два числа и возвращает максимум из них (на самом деле эта функция уже стала частью синтаксиса Python).
10 20
def max(a, b):
if a > b:
return a
else:
return b
print(max(3, 5))
print(max(5, 3))
print(max(int(input()), int(input())))
Теперь вы можете написать функцию max3() которая принимает три числа и возвращает максимум из них.
None
def max(a, b):
if a > b:
return a
else:
return b
def max3(a, b, c):
return max(max(a, b), c)
print(max3(3, 5, 4))
Встроенная функция max() в Python может принимать различное количество аргументов и возвращать максимум из них. Вот пример того, как можно написать такую функцию.
None
def max(*a):
res = a[0]
for val in a[1:]:
if val > res:
res = val
return res
print(max(3, 5, 4))
Все, переданное этой функции, соберет параметры в один кортеж, называемый a , который обозначен звездочкой.
Внутри функции вы можете использовать переменные, объявленные где-то вне нее:
None
def f():
print(a)
a = 1
f()
Здесь переменная a установлена в 1, а функция f() печатает это значение, несмотря на то, что когда мы объявляем функцию f эта переменная не инициализируется. Причина в том, что во время вызова функции f() (последняя строка) переменная a уже имеет значение. Вот почему функция f() может отображать ее.
Такие переменные (объявленные вне функции, но доступные внутри функции) называются глобальными .
Но если вы инициализируете некоторую переменную внутри функции, вы не сможете использовать эту переменную за ее пределами. Например:
None
def f():
a = 1
f()
print(a)
Мы получаем ошибку NameError: name 'a' is not defined . Такие переменные, объявленные внутри функции, называются локальными . После выхода из функции они становятся недоступными.
Что действительно очаровательно здесь, что произойдет, если вы измените значение глобальной переменной внутри функции:
None
def f():
a = 1
print(a)
a = 0
f()
print(a)
Эта программа напечатает вам числа 1 и 0. Несмотря на то, что значение переменной a измененное внутри функции, вне функции остается неизменным! Это делается для того, чтобы «защитить» глобальные переменные от непреднамеренных изменений функции. Итак, если какая-либо переменная изменяется внутри функции, переменная становится локальной переменной, и ее модификация не изменит глобальную переменную с тем же именем.
Более формально: интерпретатор Python рассматривает переменную локальную для функции, если в коде этой функции есть хотя бы одна команда, которая изменяет значение переменной. Тогда эта переменная также не может быть использована до инициализации. Инструкции, которые изменяют значение переменной — operator = , += и использование переменной в качестве цикла for параметра. Однако, даже если оператор change-variable никогда не выполняется, интерпретатор не может его проверить, и переменная остается локальной. Пример:
None
def f():
print(a)
if False:
a = 0
a = 1
f()
Произошла ошибка: UnboundLocalError: local variable 'a' referenced before assignment . А именно, в функции f() идентификатор a становится локальной переменной, так как функция содержит команду, которая модифицирует переменную a . Инструкция по модификации никогда не будет выполнена, но интерпретатор не проверяет ее. Поэтому, когда вы пытаетесь распечатать переменную a , вы обращаетесь к неинициализированной локальной переменной.
Если вы хотите, чтобы функция могла изменять какую-либо переменную, вы должны объявить эту переменную внутри функции, используя ключевое слово global :
None
def f():
global a
a = 1
print(a)
a = 0
f()
print(a)
В этом примере будет напечатан вывод 1 1, потому что переменная a объявлена глобальной, а ее изменение внутри функции вызывает ее изменение в глобальном масштабе.
Однако лучше не изменять значения глобальных переменных внутри функции. Если ваша функция должна изменить некоторую переменную, пусть она вернет это значение, и вы выберете при вызове функции явно назначить переменную этому значению. Если вы следуете этим правилам, логика функций работает независимо от логики кода, и поэтому такие функции могут быть легко скопированы из одной программы в другую, экономя ваше время.
Например, предположим, что ваша программа должна вычислить факториал данного номера, который вы хотите сохранить в переменной f. Вот как вы не должны этого делать:
5
def factorial(n):
global f
res = 1
for i in range(2, n + 1):
res *= i
f = res
n = int(input())
factorial(n)
print(f)
# делать другие вещи с переменной f
Это пример плохого кода, потому что трудно использовать другое время. Если завтра вам понадобится другая программа для использования функции «factorial», вы не сможете просто скопировать эту функцию и вставить новую программу. Вам нужно будет убедиться, что эта программа не содержит переменную f .
Гораздо лучше переписать этот пример следующим образом:
5
# начало фрагмента кода, который можно скопировать из программы в программу
def factorial(n):
res = 1
for i in range(2, n + 1):
res *= i
return res
# конец фрагмента кода
n = int(input())
f = factorial(n)
print(f)
# делать другие вещи с переменной f
Полезно сказать, что функции могут возвращать более одного значения. Вот пример возврата списка из двух или более значений:
return [a, b]
Вы можете вызвать функцию такого списка и использовать его в нескольких назначениях:
n, m = f(a, b)
Как мы видели выше, функция может вызвать другую функцию. Но функции могут также называть себя! Чтобы проиллюстрировать это, рассмотрим пример факторно-вычислительной функции. Хорошо известно, что 0! = 1, 1! = 1. Как рассчитать значение n! для больших n? Если бы нам удалось вычислить значение (n-1) !, то мы легко вычислим n !, так как n! = N⋅ (n-1) !. Но как вычислить (n-1) !? Если мы вычислили (n-2) !, тогда (n-1)! = (N-1) ⋅ (n-2) !. Как рассчитать (n-2) !? Если … В итоге мы получаем 0 !, что равно 1. Таким образом, для вычисления факториала мы можем использовать значение факториала для меньшего целого числа. Этот расчет можно сделать с помощью Python:
None
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
print(factorial(5))
Ситуация, когда функция вызывает себя, называется рекурсией , и такая функция называется рекурсивной.
Рекурсивные функции — мощный механизм программирования. К сожалению, они не всегда эффективны и часто приводят к ошибкам. Наиболее распространенной ошибкой является бесконечная рекурсия , когда цепочка вызовов функций никогда не заканчивается (ну, на самом деле, она заканчивается, когда у вас заканчивается свободная память на вашем компьютере). Пример бесконечной рекурсии:
def f():
return f()
Две наиболее распространенные причины, вызывающие бесконечную рекурсию:
- Неправильное условие остановки. Например, если в факториал-калькуляционной программе мы забываем поставить проверку,
if n == 0, тоfactorial(0)вызоветfactorial(-1), который вызоветfactorial(-2)и т. Д. - Рекурсивный вызов с неправильными параметрами. Например, если функция
factorial(n)вызывает функциюfactorial(n), мы также получим бесконечную цепочку вызовов.
Поэтому при кодировании рекурсивной функции сначала необходимо убедиться, что она достигнет своих условий остановки — подумать, почему ваша рекурсия когда-либо закончится.
Встроенные функции
— документация Python 3.9.6
Откройте файл и верните соответствующий файловый объект. Если файл
не может быть открыт, возникает OSError . Видеть
Чтение и запись файлов для получения дополнительных примеров использования этой функции.
файл — это объект, похожий на путь, дающий имя пути (абсолютное или
относительно текущего рабочего каталога) открываемого файла или
целочисленный файловый дескриптор файла, который нужно обернуть. (Если дескриптор файла
задано, он закрывается, когда возвращаемый объект ввода-вывода закрывается, если closefd
установлено значение Ложь .)
режим — это дополнительная строка, указывающая режим, в котором файл
открыт. По умолчанию это 'r' , что означает открытие для чтения в текстовом режиме.
Другие общие значения: 'w' для записи (усечение файла, если он
уже существует), 'x' для эксклюзивного создания и 'a' для добавления
(что на некоторых системах Unix означает, что все записи добавляются в конец
файл независимо от текущей позиции поиска).В текстовом режиме, если
кодировка не указана, используемая кодировка зависит от платформы:
locale.getpreferredencoding (False) вызывается для получения текущей локали
кодирование. (Для чтения и записи сырых байтов используйте двоичный режим и оставьте
кодировка не указана.) Доступные режимы:
Знак | Значение |
|---|---|
| открыт для чтения (по умолчанию) |
| открыт для записи, сначала обрезка файла |
| открыто для монопольного создания, ошибка, если файл уже существует |
| открыто для записи, добавляется в конец файла, если он существует |
| двоичный режим |
| текстовый режим (по умолчанию) |
| открыт для обновления (чтение и запись) |
Режим по умолчанию — 'r' (открыт для чтения текста, синоним 'rt' ).Режимы 'w +' и 'w + b' открывают и обрезают файл. Режимы 'r +'
и 'r + b' открывают файл без усечения.
Как упоминалось в обзоре, Python различает двоичные
и текстовый ввод / вывод. Файлы, открытые в двоичном режиме (включая 'b' в режиме
аргумент) возвращает содержимое в виде байтов объектов без какого-либо декодирования. В
текстовый режим (по умолчанию или когда 't' включено в аргумент mode ),
содержимое файла возвращается как str , байты были
сначала декодируется с использованием платформенно-зависимого кодирования или с использованием указанного
кодировка , если задано.
Разрешен дополнительный символ режима, 'U' , который больше не
имеет какой-либо эффект и считается устаревшим. Ранее он был включен
универсальные символы новой строки в текстовом режиме, которые стали поведением по умолчанию
в Python 3.0. См. Документацию к
параметр новой строки для получения дополнительных сведений.
Примечание
Python не зависит от представления текста операционной системой.
файлы; вся обработка выполняется самим Python и, следовательно,
независимая платформа.
буферизация — это необязательное целое число, используемое для установки политики буферизации. Пройдено 0
для выключения буферизации (разрешено только в двоичном режиме), 1 для выбора строки
буферизация (может использоваться только в текстовом режиме) и целое число> 1, чтобы указать размер
в байтах буфера фрагментов фиксированного размера. Если нет аргумента буферизации
Учитывая, что политика буферизации по умолчанию работает следующим образом:
Двоичные файлы буферизуются фрагментами фиксированного размера; размер буфера
выбирается с помощью эвристики, пытающейся определить «блокировку» основного устройства
размер »и возвращается кio.DEFAULT_BUFFER_SIZE. Во многих системах
размер буфера обычно составляет 4096 или 8192 байта.«Интерактивные» текстовые файлы (файлы, для которых
isatty ()
возвращаетTrue) использовать буферизацию строки. Другие текстовые файлы используют политику
описано выше для двоичных файлов.
кодировка — это имя кодировки, используемой для декодирования или кодирования файла.
Это следует использовать только в текстовом режиме. Кодировка по умолчанию — платформа.
зависимый (независимо от локали .getpreferredencoding () возвращает), но любой
кодировка текста, поддерживаемая Python
может быть использован. См. Модуль кодеков .
список поддерживаемых кодировок.
ошибок — необязательная строка, определяющая способ кодирования и декодирования.
ошибки должны обрабатываться — это не может использоваться в двоичном режиме.
Доступны различные стандартные обработчики ошибок.
(перечислены в разделе «Обработчики ошибок»), хотя любые
имя обработки ошибок, которое было зарегистрировано с
codecs.register_error () также допустим.Стандартные имена
включают:
'strict', чтобы вызвать исключениеValueError, если есть
ошибка кодировки. Значение по умолчаниюНетимеет то же самое
эффект.'ignore'игнорирует ошибки. Обратите внимание, что игнорирование ошибок кодирования
может привести к потере данных.'replace'вызывает вставку маркера замены (например,'?')
где есть искаженные данные.'surrogateescape'будет представлять любые неправильные байты как код
точек в области частного использования Unicode в диапазоне от U + DC80 до
U + DCFF.Эти частные кодовые точки будут затем снова превращены в
те же байты при использовании обработчика ошибокsurrogateescape
при записи данных. Это полезно для обработки файлов в
неизвестная кодировка.'xmlcharrefreplace'поддерживается только при записи в файл.
Символы, не поддерживаемые кодировкой, заменяются символами
ссылка на соответствующий символ XML& # nnn;.'backslashreplace'заменяет искаженные данные на обратную косую черту Python
escape-последовательности.'namereplace'(также поддерживается только при записи)
заменяет неподдерживаемые символы управляющими последовательностями\ N {...}.
newline управляет тем, как работает универсальный режим новой строки (это только
относится к текстовому режиму). Это может быть None , '' , '\ n' , '\ r' и
'\ r \ n' . Он работает следующим образом:
При чтении ввода из потока, если перевод строки равен
Нет, универсальный
Режим новой строки включен.Строки на входе могут заканчиваться на'\ n',
'\ r'или'\ r \ n', и они переводятся в'\ n'перед
возвращаются вызывающему абоненту. Если это'', универсальный режим новой строки
включен, но окончания строк возвращаются вызывающему абоненту без перевода. Если это
имеет любое из других допустимых значений, строки ввода заканчиваются только
заданная строка, и конец строки возвращается вызывающему абоненту без перевода.При записи вывода в поток, если новая строка равна
Нет, любое'\ n'
написанные символы переводятся в системный разделитель строк по умолчанию,
ос.linesep. Если новая строка — это''или'\ n', перевода нет
происходит. Если новая строка — любое другое допустимое значение, любое'\ n'
написанные символы переводятся в заданную строку.
Если closefd равно Ложь и был указан дескриптор файла, а не имя файла.
задано, базовый дескриптор файла будет оставаться открытым, когда файл
закрыто. Если указано имя файла closefd должно быть True (по умолчанию)
в противном случае возникнет ошибка.
Можно использовать настраиваемый открыватель, передав вызываемый объект как opener . Лежащий в основе
файловый дескриптор для файлового объекта затем получается путем вызова opener с
( файл , флаги ). opener должен возвращать дескриптор открытого файла (передавая
os.open as opener дает функциональность, аналогичную прохождению
Нет ).
Новый созданный файл не наследуется.
В следующем примере используется параметр dir_fd
ос.open () , чтобы открыть файл, относящийся к заданному каталогу:
>>> импорт ос
>>> dir_fd = os.open ('somedir', os.O_RDONLY)
>>> def opener (путь, флаги):
... вернуть os.open (путь, флаги, dir_fd = dir_fd)
...
>>> с open ('spamspam.txt', 'w', opener = opener) как f:
... print ('Это будет записано в somedir / spamspam.txt', file = f)
...
>>> os.close (dir_fd) # не допускать утечки файлового дескриптора
Тип файлового объекта, возвращаемого функцией open () .
зависит от режима.Когда open () используется для открытия файла в тексте
mode ( 'w' , 'r' , 'wt' , 'rt' и т. д.), он возвращает подкласс
io.TextIOBase (а именно io.TextIOWrapper ). При использовании
чтобы открыть файл в двоичном режиме с буферизацией, возвращаемый класс —
подкласс io.BufferedIOBase . Точный класс варьируется: в прочтении
в двоичном режиме возвращается io.BufferedReader ; в записи двоичного кода и
добавить двоичные режимы, он возвращает io.BufferedWriter , а в
режим чтения / записи, он возвращает io.BufferedRandom . Когда буферизация
отключен, необработанный поток, подкласс io.RawIOBase ,
io.FileIO , возвращается.
См. Также модули обработки файлов, например, fileinput , io
(где объявлено open () ), os , os.path , tempfile ,
и шутиль .
Вызывает событие аудита открыть с аргументами файл , режим , флаги .
Режим Флаги и аргументов могли быть изменены или выведены из
исходный звонок.
Изменено в версии 3.3:
Добавлен параметр opener .
Добавлен режим
'x'.
IOErrorраньше вызывался, теперь это псевдонимOSError.
FileExistsErrorтеперь возникает, если файл открывается в монопольном режиме.
режим создания ('x') уже существует.
Устарело с версии 3.4, будет удалено в версии 3.10: Режим 'U' .
Изменено в версии 3.5:
Если системный вызов прерывается и обработчик сигнала не вызывает
исключение, функция теперь повторяет системный вызов вместо того, чтобы вызывать
InterruptedErrorисключение (объяснение см. В PEP 475 ).Добавлен обработчик ошибок
namereplace.
На этой странице: def, return, docstrings, help (), функции возврата значения и void Функции: основыДавайте откажемся от старой алгебры. Вы выучили «функции» примерно так:
Попробуем другую функцию. Ниже приведена функция, которая принимает глагол (надеюсь) и возвращает герундийную форму:
Несколько параметров, строка документацииНиже представлена чуть более сложная функция.Он принимает два аргумента, имеет условное выражение в теле функции и начинается со строки:
«» «Проверяет, если… Строка «» «называется» docstring «. Размещенная в самом верху тела функции, она действует как документация для функции. Эта строка распечатывается, когда вы вызываете help () для функции:
Вот еще один пример.Эта функция возвращает список символов, общих для двух строк. (Было бы лучше, если бы не было дубликатов. Можно улучшить?)
Функции: Возвращение vs.ПустотаВы можете подумать: «Погодите минутку, я не видел никакого оператора возврата в учебнике по определению функций». Вы правы — определенная Эд функция get_legal () не включала никакого оператора возврата, а только набор функций печати.
Хорошо, тогда чем отличаются функции void и функции типа «return»? Хороший вопрос. Позвольте мне проиллюстрировать это на примерах. Вот функция get_ing (), определенная выше, и ее недействительный аналог print_ing ():
Вызывая две функции, вы сначала замечаете небольшую разницу в выводе.Возвращающая функция дает вам строку (примечание »), а функция печати показывает напечатанный вывод строки — обратите внимание на отсутствие кавычек. Обратите внимание, что возвращаемое значение отображается только в интерактивной среде оболочки; в сценарии только команды печати приводят к отображению вывода.
Теперь, поскольку get_ing () возвращает значение, его можно скопировать в переменную с помощью оператора присваивания.Попробуйте сделать то же самое с print_ing (), и вы столкнетесь с непредвиденными последствиями: печать происходит после оператора присваивания, и вы не получаете ничего в качестве значения переменной, потому что эта функция, будучи недействительной, ничего не возвращает.
Кроме того, функцию, возвращающую значение, можно подключить прямо к другой функции.Опять же, поскольку функции void ничего не возвращают, они не могут. Ниже get_ing (‘eat’) передается в функцию len () для успешного результата. С помощью len (print_ing (‘eat’)) печать происходит независимо, а затем возникает ошибка типа:
Наконец, если вам нужна печать, ее также можно выполнить с помощью функции, возвращающей значение: просто используйте с ней оператор печати.
Это заняло некоторое время, но я надеюсь, что теперь вы ясно видите фундаментальные различия между двумя типами функций. По правде говоря, функции возвращаемого типа гораздо более функциональны и полезны. В других языках функции типа void даже не называются функциями — вместо этого они называются процедурами. |
Определение вашей собственной функции Python — Настоящий Python
Смотреть сейчас В этом руководстве есть связанный видеокурс, созданный командой Real Python. Просмотрите его вместе с письменным руководством, чтобы углубить свое понимание: Определение и вызов функций Python
На протяжении предыдущих руководств этой серии вы видели множество примеров, демонстрирующих использование встроенных функций Python. В этом руководстве вы узнаете, как определить вашу собственную функцию Python .Вы узнаете, когда разделить вашу программу на отдельные пользовательские функции и какие инструменты вам понадобятся для этого.
Из этого руководства вы узнаете:
- Как функции работают в Python и почему они полезны
- Как определить и вызвать вашу собственную функцию Python
- Механизмы передачи аргументов вашей функции
- Как вернуть данные из вашей функции обратно в вызывающую среду
Функции в Python
Возможно, вы знакомы с математической концепцией функции .Функция — это связь или отображение между одним или несколькими входами и набором выходов. В математике функция обычно представлена так:
Здесь f — это функция, которая работает на входах x и y . Выход функции: z . Однако функции программирования гораздо более обобщены и универсальны, чем это математическое определение. Фактически, правильное определение и использование функций настолько критично для правильной разработки программного обеспечения, что практически все современные языки программирования поддерживают как встроенные, так и определяемые пользователем функции.
В программировании функция — это автономный блок кода, который инкапсулирует конкретную задачу или связанную группу задач. В предыдущих руководствах этой серии вы познакомились с некоторыми встроенными функциями, предоставляемыми Python. id () , например, принимает один аргумент и возвращает уникальный целочисленный идентификатор этого объекта:
>>>
>>> s = 'foobar'
>>> id (s)
56313440
len () возвращает длину переданного ему аргумента:
>>>
>>> a = ['foo', 'bar', 'baz', 'qux']
>>> len (а)
4
any () принимает в качестве аргумента итерацию и возвращает Истина , если какой-либо из элементов в итерации является истинным, и Ложь в противном случае:
>>>
>>> любое ([Ложь, Ложь, Ложь])
Ложь
>>> любой ([Ложь, Истина, Ложь])
Правда
>>> any (['bar' == 'baz', len ('foo') == 4, 'qux' в {'foo', 'bar', 'baz'}])
Ложь
>>> any (['bar' == 'baz', len ('foo') == 3, 'qux' в {'foo', 'bar', 'baz'}])
Правда
Каждая из этих встроенных функций выполняет определенную задачу.Код, выполняющий задачу, где-то определен, но вам не нужно знать, где и даже как он работает. Все, что вам нужно знать, это интерфейс функции:
- Какие аргументов (если есть) нужно
- Какие значения (если есть), он возвращает
Затем вы вызываете функцию и передаете ей соответствующие аргументы. Выполнение программы переходит к обозначенному фрагменту кода и делает свое полезное дело. Когда функция завершена, выполнение возвращается к вашему коду с того места, где оно было остановлено.Функция может возвращать или не возвращать данные для использования вашим кодом, как в приведенных выше примерах.
Когда вы определяете свою собственную функцию Python, она работает точно так же. Где-то в коде вы вызываете функцию Python, и выполнение программы передается в тело кода, составляющего функцию.
Примечание: В этом случае вы будете знать, где находится код и как именно он работает, потому что вы его написали!
Когда функция завершена, выполнение возвращается в то место, где функция была вызвана.В зависимости от того, как вы разработали интерфейс функции, данные могут передаваться при вызове функции, а возвращаемые значения могут передаваться обратно после ее завершения.
Важность функций Python
Практически все языки программирования, используемые сегодня, поддерживают определенные пользователем функции, хотя их не всегда называют функциями. На других языках вы можете встретить их как одно из следующих:
- Подпрограммы
- Процедуры
- Методы
- Подпрограммы
Итак, зачем вообще определять функции? Есть несколько очень веских причин.Давайте пройдемся по нескольким.
Абстракция и возможность повторного использования
Предположим, вы пишете код, который делает что-то полезное. По мере продолжения разработки вы обнаружите, что задача, выполняемая этим кодом, вам часто требуется во многих различных местах вашего приложения. Что вы должны сделать? Что ж, вы можете просто копировать код снова и снова, используя возможность копирования и вставки вашего редактора.
Позже вы, вероятно, решите, что рассматриваемый код нужно изменить.Вы либо обнаружите, что в нем что-то не так, что нужно исправить, либо захотите как-то улучшить его. Если копии кода разбросаны по всему приложению, вам нужно будет внести необходимые изменения в каждом месте.
Примечание: На первый взгляд это может показаться разумным решением, но в долгосрочной перспективе это может стать кошмаром для обслуживания! Хотя ваш редактор кода может помочь, предоставляя функцию поиска и замены, этот метод подвержен ошибкам, и вы можете легко внести в свой код ошибки, которые будет трудно найти.
Лучшее решение — определить функцию Python, которая выполняет задачу . В любом месте вашего приложения, где вам нужно выполнить задачу, вы просто вызываете функцию. В дальнейшем, если вы решите изменить способ работы, вам нужно будет изменить код только в одном месте, то есть в том месте, где определена функция. Изменения будут автоматически приняты везде, где вызывается функция.
Абстракция функциональности в определение функции является примером принципа «не повторяйся» (DRY) при разработке программного обеспечения.Это, пожалуй, самая сильная мотивация для использования функций.
Модульность
Функции
позволяют разбить сложных процессов на более мелкие шаги. Представьте, например, что у вас есть программа, которая читает файл, обрабатывает его содержимое, а затем записывает выходной файл. Ваш код может выглядеть так:
# Основная программа
# Код для чтения файла в
<заявление>
<заявление>
<заявление>
<заявление>
# Код для обработки файла
<заявление>
<заявление>
<заявление>
<заявление>
# Код для записи файла
<заявление>
<заявление>
<заявление>
<заявление>
В этом примере основная программа — это связка кода, связанного в длинную последовательность, с пробелами и комментариями, которые помогают упорядочить ее.Однако, если бы код стал намного длиннее и сложнее, вам было бы все труднее осмыслить его.
В качестве альтернативы вы можете структурировать код примерно так:
def read_file ():
# Код для чтения файла в
<заявление>
<заявление>
<заявление>
<заявление>
def process_file ():
# Код для обработки файла
<заявление>
<заявление>
<заявление>
<заявление>
def write_file ():
# Код для записи файла
<заявление>
<заявление>
<заявление>
<заявление>
# Основная программа
read_file ()
process_file ()
write_file ()
Этот пример — модульный .Вместо того, чтобы связывать весь код вместе, он разбит на отдельные функции, каждая из которых ориентирована на конкретную задачу. Эти задачи: чтение , процесс и запись . Теперь основной программе просто нужно вызвать каждый из них по очереди.
Примечание: Ключевое слово def вводит новое определение функции Python. Вы все об этом узнаете очень скоро.
В жизни вы делаете такие вещи все время, даже если не думаете об этом явно.Если бы вы захотели переместить несколько полок, заполненных вещами, из одной стороны гаража в другую, то, надеюсь, вы не станете просто стоять и бесцельно думать: «Ой, блин. Мне нужно перевезти все это туда! Как я это сделал???» Вы бы разделили задание на управляемые шаги:
- Уберите вещей с полок.
- Разобрать полок.
- Перенесите частей полки через гараж на новое место.
- Снова соберите полок.
- Отнесите вещей через гараж.
- Положите вещей обратно на полки.
Разделение большой задачи на более мелкие и небольшие подзадачи помогает упростить рассмотрение большой задачи и управление ею. По мере того, как программы становятся более сложными, становится все более выгодным модулировать их таким образом.
Разделение пространства имен
Пространство имен — это область программы, в которой идентификаторов имеют значение.Как вы увидите ниже, когда вызывается функция Python, для этой функции создается новое пространство имен, которое отличается от всех других пространств имен, которые уже существуют.
Практический результат этого состоит в том, что переменные можно определять и использовать в функции Python, даже если они имеют то же имя, что и переменные, определенные в других функциях или в основной программе. В этих случаях не будет путаницы или вмешательства, потому что они хранятся в отдельных пространствах имен.
Это означает, что, когда вы пишете код внутри функции, вы можете использовать имена и идентификаторы переменных, не беспокоясь о том, использовались ли они где-то еще вне функции.Это помогает значительно минимизировать ошибки в коде.
Надеюсь, вы достаточно убедились в достоинствах функций и хотите их создать! Посмотрим как.
Вызовы функций и определение
Обычный синтаксис определения функции Python следующий:
def <имя_функции> ([<параметры>]):
<заявление (я)>
Компоненты определения поясняются в таблице ниже:
| Компонент | Значение |
|---|---|
по умолчанию | Ключевое слово, информирующее Python о том, что функция определяется |
<имя_функции> | Действительный идентификатор Python, который называет функцию |
<параметры> | Необязательный список параметров, разделенных запятыми, которые могут быть переданы функции |
: | Знаки пунктуации, обозначающие конец заголовка функции Python (имя и список параметров) |
<выписки> | Блок действительных операторов Python |
Последний элемент, , называется телом функции.Тело — это блок операторов, который будет выполняться при вызове функции. Тело функции Python определяется отступом в соответствии с правилом off-side. Это то же самое, что и блоки кода, связанные со структурой управления, например, , если , или , а .
Синтаксис для вызова функции Python следующий:
<имя_функции> ([<аргументы>])
<аргументы> — это значения, переданные в функцию.Они соответствуют <параметры> в определении функции Python. Вы можете определить функцию, которая не принимает никаких аргументов, но круглые скобки по-прежнему необходимы. И определение функции, и вызов функции всегда должны включать круглые скобки, даже если они пусты.
Как обычно, вы начнете с небольшого примера, а затем добавите сложности. Помня об освященной веками математической традиции, вы вызовете свою первую функцию Python f () . Вот файл сценария foo.py , который определяет и вызывает f () :
1def f ():
2 s = '- Внутри f ()'
3 отпечатка (ов)
4
5print ('Перед вызовом f ()')
6f ()
7print ('После вызова f ()')
Вот как работает этот код:
Строка 1 использует ключевое слово
def, чтобы указать, что функция определяется. Выполнение оператораdefпросто создает определениеf (). Все следующие строки с отступом (строки 2–3) становятся частью телаf ()и сохраняются как его определение, но еще не выполняются.Строка 4 — это небольшой пробел между определением функции и первой строкой основной программы. Хотя это и не является синтаксически необходимым, но иметь. Чтобы узнать больше о пробелах вокруг определений функций Python верхнего уровня, прочтите статью Написание красивого кода Python с помощью PEP 8.
Строка 5 — это первый оператор без отступа, поскольку он не является частью определения
f (). Это начало основной программы.Когда выполняется основная программа, этот оператор выполняется первым.Линия 6 — это звонок по номеру
f (). Обратите внимание, что пустые круглые скобки всегда требуются как в определении функции, так и при ее вызове, даже если нет параметров или аргументов. Выполнение переходит кf (), и выполняются операторы в телеf ().Строка 7 — это следующая строка, выполняемая после завершения тела
f ().Выполнение возвращается к этому операторуprint ().
Последовательность выполнения (или потока управления ) для foo.py показана на следующей диаграмме:
Когда foo.py запускается из командной строки Windows, результат будет следующим:
C: \ Users \ john \ Documents \ Python \ doc> python foo.py
Перед вызовом f ()
- Внутри f ()
После вызова f ()
Иногда вам может понадобиться определить пустую функцию, которая ничего не делает.Это называется заглушкой , которая обычно является временным заполнителем для функции Python, которая будет полностью реализована позже. Как блок в управляющей структуре не может быть пустым, так и тело функции не может быть пустым. Чтобы определить функцию-заглушку, используйте оператор pass :
>>>
>>> def f ():
... проходить
...
>>> f ()
Как видно выше, вызов функции-заглушки синтаксически допустим, но ничего не делает.
Передача аргумента
До сих пор в этом руководстве функции, которые вы определили, не принимали никаких аргументов. Иногда это может быть полезно, и иногда вы будете писать такие функции. Однако чаще вы хотите передать данные функции , чтобы ее поведение могло меняться от одного вызова к другому. Посмотрим, как это сделать.
Позиционные аргументы
Самый простой способ передать аргументы функции Python — использовать позиционных аргументов (также называемых обязательных аргументов ).В определении функции вы указываете в скобках список параметров, разделенных запятыми:
>>>
>>> def f (кол-во, шт., Цена):
... print (f '{qty} {item} cost $ {price: .2f}')
...
При вызове функции указывается соответствующий список аргументов:
>>>
>>> f (6, 'бананы', 1.74)
6 бананов стоят 1,74 доллара
Параметры ( количество , элемент и цена ) ведут себя как переменных , которые определены локально для функции.Когда функция вызывается, переданные аргументы ( 6 , 'бананов' и 1,74 ) привязывают к параметрам по порядку, как если бы путем присвоения переменной:
| Параметр | Аргумент | |
|---|---|---|
шт. | ← | 6 |
товар | ← | бананы |
цена | ← | 1.74 |
В некоторых текстах по программированию параметры, указанные в определении функции, упоминаются как формальных параметров , а аргументы в вызове функции упоминаются как фактических параметров:
Хотя позиционные аргументы являются наиболее простым способом передачи данных в функцию, они также обеспечивают наименьшую гибкость. Во-первых, порядок аргументов в вызове должен соответствовать порядку параметров в определении.Конечно, ничто не мешает вам указывать позиционные аргументы не по порядку:
>>>
>>> f ('бананы', 1.74, 6)
бананы 1.74 стоят $ 6.00
Функция может даже работать, как в приведенном выше примере, но маловероятно, что она даст правильные результаты. Это ответственность программиста, который определяет функцию, чтобы задокументировать, какими должны быть соответствующие аргументы , и ответственность пользователя функции — знать эту информацию и соблюдать ее.
С позиционными аргументами аргументы в вызове и параметры в определении должны согласовываться не только по порядку, но и по номеру . По этой причине позиционные аргументы также называются обязательными аргументами. Вы не можете ничего пропустить при вызове функции:
>>>
>>> # Слишком мало аргументов
>>> f (6, 'бананы')
Отслеживание (последний вызов последний):
Файл "", строка 1, в
f (6, 'бананы')
TypeError: f () отсутствует 1 обязательный позиционный аргумент: 'цена'
Вы также не можете указать лишние:
>>>
>>> # Слишком много аргументов
>>> f (6, 'бананы', 1.74, кумкваты)
Отслеживание (последний вызов последний):
Файл "", строка 1, в
f (6, «бананы», 1,74, «кумкват»)
TypeError: f () принимает 3 позиционных аргумента, но было дано 4
Позиционные аргументы концептуально просты в использовании, но они не очень снисходительны. Вы должны указать такое же количество аргументов в вызове функции, как и параметры в определении, и в точно таком же порядке. В следующих разделах вы увидите некоторые приемы передачи аргументов, которые снимают эти ограничения.
Аргументы ключевого слова
При вызове функции можно указать аргументы в форме <ключевое слово> = <значение> . В этом случае каждое <ключевое слово> должно соответствовать параметру в определении функции Python. Например, ранее определенная функция f () может быть вызвана с аргументами ключевого слова следующим образом:
>>>
>>> f (qty = 6, item = 'bananas', price = 1,74)
6 бананов стоят 1,74 доллара
Ссылка на ключевое слово, не соответствующее ни одному из заявленных параметров, генерирует исключение:
>>>
>>> f (qty = 6, item = 'bananas', cost = 1.74)
Отслеживание (последний вызов последний):
Файл "", строка 1, в
TypeError: f () получил неожиданный аргумент ключевого слова 'стоимость'
Использование аргументов ключевого слова снимает ограничение на порядок аргументов. Каждый аргумент ключевого слова явно обозначает конкретный параметр по имени, поэтому вы можете указать их в любом порядке, и Python все равно будет знать, какой аргумент соответствует какому параметру:
>>>
>>> f (item = 'bananas', price = 1.74, qty = 6)
6 бананов стоят 1 доллар.74
Однако, как и в случае с позиционными аргументами, количество аргументов и параметров должно совпадать:
>>>
>>> # Еще слишком мало аргументов
>>> f (кол-во = 6, элемент = 'бананы')
Отслеживание (последний вызов последний):
Файл "", строка 1, в
f (кол-во = 6, элемент = 'бананы')
TypeError: f () отсутствует 1 обязательный позиционный аргумент: 'цена'
Таким образом, аргументы ключевого слова допускают гибкость в порядке указания аргументов функции, но количество аргументов остается жестким.
Вы можете вызвать функцию, используя как позиционные, так и ключевые аргументы:
>>>
>>> f (6, price = 1.74, item = 'bananas')
6 бананов стоят 1,74 доллара
>>> f (6, 'бананы', цена = 1,74)
6 бананов стоят 1,74 доллара
Когда присутствуют как позиционные аргументы, так и аргументы ключевого слова, все позиционные аргументы должны идти первыми:
>>>
>>> f (6, item = 'bananas', 1.74)
SyntaxError: позиционный аргумент следует за аргументом ключевого слова
После того, как вы указали аргумент ключевого слова, справа от него не может быть никаких позиционных аргументов.
Параметры по умолчанию
Если параметр, указанный в определении функции Python, имеет форму <имя> = <значение> , тогда <значение> становится значением по умолчанию для этого параметра. Параметры, определенные таким образом, называются параметрами по умолчанию или дополнительными параметрами . Пример определения функции с параметрами по умолчанию показан ниже:
>>>
>>> def f (qty = 6, item = 'bananas', price = 1.74):
... print (f '{qty} {item} cost $ {price :.2f} ')
...
Когда вызывается эта версия f () , любой аргумент, который не указан, принимает значение по умолчанию:
>>>
>>> f (4, 'яблоки', 2.24)
4 яблока стоят 2,24 доллара.
>>> f (4, 'яблоки')
4 яблока стоят 1,74 доллара
>>> f (4)
4 банана стоят 1,74 доллара
>>> f ()
6 бананов стоят 1,74 доллара
>>> f (item = 'кумкват', кол-во = 9)
9 кумкватов стоят 1,74 доллара
>>> f (цена = 2,29)
6 бананов стоят 2,29 доллара
Итого:
- Позиционные аргументы должны соответствовать по порядку и номеру параметрам, объявленным в определении функции.
- Аргументы ключевого слова должны совпадать с объявленными параметрами по количеству, но они могут быть указаны в произвольном порядке.
- Параметры по умолчанию позволяют опускать некоторые аргументы при вызове функции.
Изменяемые значения параметров по умолчанию
Все может стать странным, если вы укажете значение параметра по умолчанию, которое является изменяемым объектом . Рассмотрим это определение функции Python:
>>>
>>> def f (my_list = []):
... my_list.append ('###')
... вернуть my_list
...
f () принимает единственный параметр списка, добавляет строку '###' в конец списка и возвращает результат:
>>>
>>> f (['foo', 'bar', 'baz'])
['foo', 'bar', 'baz', '###']
>>> f ([1, 2, 3, 4, 5])
[1, 2, 3, 4, 5, '###']
Значение по умолчанию для параметра my_list — пустой список, поэтому, если f () вызывается без каких-либо аргументов, возвращаемое значение — это список с одним элементом '###' :
Пока все имеет смысл.Итак, что вы ожидаете, если f () будет вызван без каких-либо параметров второй и третий раз? Посмотрим:
>>>
>>> f ()
['###', '###']
>>> f ()
['###', '###', '###']
Ой! Вы могли ожидать, что каждый последующий вызов также будет возвращать одноэлементный список ['###'] , как и первый. Вместо этого возвращаемое значение продолжает расти. Что случилось?
В Python значения параметров по умолчанию — , определенные только один раз , когда функция определена (то есть, когда выполняется инструкция def ).Значение по умолчанию не переопределяется каждый раз при вызове функции. Таким образом, каждый раз, когда вы вызываете f () без параметра, вы выполняете .append () в том же списке.
Вы можете продемонстрировать это с помощью id () :
>>>
>>> def f (my_list = []):
... печать (id (my_list))
... my_list.append ('###')
... вернуть my_list
...
>>> f ()
140095566958408
['###']
>>> f ()
140095566958408
['###', '###']
>>> f ()
140095566958408
['###', '###', '###']
Отображаемый идентификатор объекта подтверждает, что, когда my_list разрешено использовать по умолчанию, значение будет одним и тем же объектом при каждом вызове.Поскольку списки изменяемы, каждый последующий вызов .append () приводит к тому, что список становится длиннее. Это распространенная и довольно хорошо задокументированная ошибка, когда вы используете изменяемый объект в качестве значения параметра по умолчанию. Это потенциально приводит к путанице в поведении кода, и, вероятно, лучше этого избегать.
В качестве обходного пути рассмотрите возможность использования значения аргумента по умолчанию, которое сигнализирует , что аргумент не указан . Практически любое значение будет работать, но Нет. — это обычный выбор. Когда значение дозорного показывает, что аргумент не задан, создайте новый пустой список внутри функции:
>>>
>>> def f (my_list = None):
... если my_list - None:
... my_list = []
... my_list.append ('###')
... вернуть my_list
...
>>> f ()
['###']
>>> f ()
['###']
>>> f ()
['###']
>>> f (['фу', 'бар', 'баз'])
['foo', 'bar', 'baz', '###']
>>> f ([1, 2, 3, 4, 5])
[1, 2, 3, 4, 5, '###']
Обратите внимание, как это гарантирует, что my_list теперь действительно по умолчанию использует пустой список всякий раз, когда f () вызывается без аргументов.
Передача по значению и передача по ссылке в Pascal
В разработке языков программирования есть две общие парадигмы для передачи аргумента функции:
- Передаваемое значение: Копия аргумента передается функции.
- Передача по ссылке: Ссылка на аргумент передается функции.
Существуют и другие механизмы, но они по сути являются вариациями этих двух. В этом разделе вы сделаете небольшой отход от Python и вкратце рассмотрите Pascal, язык программирования, который проводит особенно четкое различие между этими двумя.
Примечание: Не волнуйтесь, если вы не знакомы с Паскалем! Концепции аналогичны концепциям Python, а показанные примеры сопровождаются достаточно подробным объяснением, чтобы вы могли составить общее представление.Как только вы увидели, как передача аргументов работает в Паскале, мы вернемся к Python, и вы увидите, как он сравнивается.
Вот что вам нужно знать о синтаксисе Паскаля:
- Процедуры: Процедура в Паскале похожа на функцию Python.
- Двоеточие равно: Этот оператор (
: =) используется для присваивания в Паскале. Это аналог знака равенства (=) в Python. -
Writeln (): Эта функция отображает данные на консоли, аналогично функции print () в Python.
Имея такую основу, вот первый пример Pascal:
1 // Пример Pascal # 1
2
3процедура f (fx: целое число);
4начать
5 Writeln ('Начать f (): fx =', fx);
6 FX: = 10;
7 Writeln ('Конец f (): fx =', fx);
8end;
9
10 // Основная программа
11вар
12 x: целое число;
13
14начало
15 х: = 5;
16 Writeln ('Перед f (): x =', x);
17 f (x);
18 Writeln ('После f (): x =', x);
19 конец.
Вот что происходит:
- Строка 12: Основная программа определяет целочисленную переменную
x. - Строка 15: Первоначально
xприсваивается значение5. - Строка 17: Затем он вызывает процедуру
f (), передаваяxв качестве аргумента. - Строка 5: Внутри
f ()инструкцияwriteln ()показывает, что соответствующий параметрfxизначально равен5, переданному значению. - Строке 6:
fxзатем присваивается значение10. - Строка 7: Это значение проверяется этим оператором
writeln (), выполняемым непосредственно перед выходомf (). - Строка 18: Вернувшись в вызывающую среду основной программы, этот оператор
Writeln ()показывает, что после возвратаf ()xвсе еще равно5, как это было до вызова процедуры. .
При выполнении этого кода генерируется следующий вывод:
Перед f (): x = 5
Начать f (): fx = 5
Конец f (): fx = 10
После f (): x = 5
В этом примере x — это , переданное по значению , поэтому f () получает только копию.Когда соответствующий параметр fx изменяется, x не изменяется.
Примечание: Если вы хотите увидеть это в действии, вы можете запустить код самостоятельно, используя онлайн-компилятор Pascal.
Просто выполните следующие действия:
- Скопируйте код из поля кода выше.
- Посетите онлайн-компилятор Паскаля.
- В поле кода слева замените любое существующее содержимое кодом, который вы скопировали на шаге 1.
- Щелкните Выполнить .
Вы должны увидеть тот же результат, что и выше.
Теперь сравните это со следующим примером:
1 // Пример # 2 для Паскаля
2
3процедура f (var fx: integer);
4начать
5 Writeln ('Начать f (): fx =', fx);
6 FX: = 10;
7 Writeln ('Конец f (): fx =', fx);
8end;
9
10 // Основная программа
11вар
12 x: целое число;
13
14начало
15 х: = 5;
16 Writeln ('Перед f (): x =', x);
17 f (x);
18 Writeln ('После f (): x =', x);
19 конец.
Этот код идентичен первому примеру с одним изменением.Это наличие слова var перед fx в определении процедуры f () в строке 3. Это означает, что аргумент f () — это , переданное по ссылке . Изменения, внесенные в соответствующий параметр fx , также изменят аргумент в вызывающей среде.
Вывод этого кода такой же, как и раньше, за исключением последней строки:
Перед f (): x = 5
Начать f (): fx = 5
Конец f (): fx = 10
После f (): x = 10
Опять же, fx присваивается значение 10 внутри f () , как и раньше.Но на этот раз, когда возвращается f () , x в основной программе также было изменено.
Во многих языках программирования это, по сути, различие между передачей по значению и передачей по ссылке:
- Если переменная передается по значению, , тогда у функции есть копия для работы, но она не может изменить исходное значение в вызывающей среде.
- Если переменная передается по ссылке, , то любые изменения, которые функция вносит в соответствующий параметр, повлияют на значение в вызывающей среде.
Причина почему происходит от того, что означает ссылка на этих языках. Значения переменных хранятся в памяти. В Паскале и подобных языках ссылка — это, по сути, адрес этой ячейки памяти, как показано ниже:
На диаграмме слева x — это память, выделенная в пространстве имен основной программы. Когда вызывается f () , x — это , переданное значением , поэтому память для соответствующего параметра fx выделяется в пространстве имен f () , и туда копируется значение x . .Когда f () изменяет fx , изменяется именно эта локальная копия. Значение x в вызывающей среде остается неизменным.
На диаграмме справа x — это , переданное по ссылке . Соответствующий параметр fx указывает на фактический адрес в пространстве имен основной программы, где хранится значение x . Когда f () изменяет fx , он изменяет значение в этом месте точно так же, как если бы основная программа сама изменяла x .
Передача по значению и передача по ссылке в Python
Параметры в Python передаются по значению или по ссылке? Ответ таков: ни то, ни другое. Это потому, что ссылка в Python означает не совсем то же самое, что в Паскале.
Напомним, что в Python каждая часть данных представляет собой объект . Ссылка указывает на объект, а не на конкретную ячейку памяти. Это означает, что присваивание не интерпретируется в Python так же, как в Паскале. Рассмотрим следующую пару операторов на Паскале:
Они интерпретируются следующим образом:
- Переменная
xссылается на конкретную ячейку памяти. - Первый оператор помещает в это место значение
5. - Следующий оператор перезаписывает
5и помещает вместо него10.
Напротив, в Python аналогичные операторы присваивания выглядят следующим образом:
Эти операторы присваивания имеют следующее значение:
- Первый оператор заставляет
xуказывать на объект, значение которого равно5. - Следующий оператор переназначает
xкак новую ссылку на другой объект, значение которого равно10. Другими словами, второе присвоение повторно привязываетxк другому объекту со значением10.
В Python, когда вы передаете аргумент функции, происходит аналогичное повторное связывание . Рассмотрим этот пример:
>>>
1 >>> def f (fx):
2 ... fx = 10
3 ...
4 >>> х = 5
5 >>> f (x)
6 >>> х
75
В основной программе оператор x = 5 в строке 5 создает ссылку с именем x , привязанную к объекту, значение которого равно 5 . f () затем вызывается в строке 7 с x в качестве аргумента. При первом запуске f () создается новая ссылка с именем fx , которая изначально указывает на тот же объект 5 , что и x :
Однако, когда выполняется инструкция fx = 10 в строке 2, f () выполняет повторную привязку fx к новому объекту, значение которого равно 10 . Две ссылки, x и fx , на не связаны друг с другом на .Ничто другое из того, что делает f () , не повлияет на x , и когда f () завершится, x по-прежнему будет указывать на объект 5 , как это было до вызова функции:
Подтвердить все это можно с помощью id () . Вот слегка расширенная версия приведенного выше примера, которая отображает числовые идентификаторы задействованных объектов:
>>>
1 >>> def f (fx):
2 ... печать ('fx =', fx, '/ id (fx) =', id (fx))
3... fx = 10
4 ... печать ('fx =', fx, '/ id (fx) =', id (fx))
5 ...
6
7 >>> х = 5
8 >>> print ('x =', x, '/ id (x) =', id (x))
9x = 5 / id (x) = 13578
10
11 >>> f (x)
12fx = 5 / id (FX) = 13578
13fx = 10 / id (fx) = 13578
14
15 >>> печать ('x =', x, '/ id (x) =', id (x))
16x = 5 / id (x) = 13578
При первом запуске f () , fx и x указывают на один и тот же объект, чей id () равен 13578 .После того, как f () выполнит оператор fx = 10 в строке 3, fx указывает на другой объект, чей id () равен 13578 . Связь с исходным объектом в вызывающей среде теряется.
Передача аргументов в Python - это своего рода гибрид между передачей по значению и передачей по ссылке. В функцию передается ссылка на объект, но ссылка передается по значению.
Примечание. Механизм передачи аргументов Python был назван передачей по назначению .Это связано с тем, что имена параметров привязаны к объектам при вводе функции в Python, а присвоение также является процессом привязки имени к объекту. Вы также можете увидеть термины «передача по объекту», «передача по ссылке на объект» или «передача по совместному использованию».
Ключевой вывод здесь заключается в том, что функция Python не может изменить значение аргумента, переназначив соответствующий параметр чему-то другому. Следующий пример демонстрирует это:
>>>
>>> def f (x):
... x = 'foo'
...
>>> для i в (
... 40,
... dict (foo = 1, bar = 2),
... {1, 2, 3},
... 'бар',
... ['foo', 'bar', 'baz']):
... f (i)
... печать (я)
...
40
{'foo': 1, 'bar': 2}
{1, 2, 3}
бар
['фу', 'бар', 'баз']
Здесь объекты типа int , dict , set , str и list передаются в f () в качестве аргументов. f () пытается назначить каждый объект строковому 'foo' , но, как вы можете видеть, вернувшись в вызывающую среду, все они не изменились.Как только f () выполнит присвоение x = 'foo' , ссылка будет , отскок , и связь с исходным объектом будет потеряна.
Означает ли это, что функция Python вообще никогда не может изменять свои аргументы? На самом деле нет, это не так! Посмотрите, что здесь происходит:
>>>
>>> def f (x):
... x [0] = '---'
...
>>> my_list = ['foo', 'bar', 'baz', 'qux']
>>> f (мой_лист)
>>> мой_лист
['---', 'bar', 'baz', 'qux']
В этом случае аргумент f () - это список.Когда вызывается f () , передается ссылка на my_list . Вы уже видели, что f () не может переназначить my_list оптом. Если бы x было назначено чему-то другому, то оно было бы привязано к другому объекту, и соединение с my_list было бы потеряно.
Однако f () может использовать ссылку для внесения изменений в my_list . Здесь f () модифицировал первый элемент.Вы можете видеть, что после возврата из функции my_list фактически был изменен в вызывающей среде. То же самое относится и к словарю:
>>>
>>> def f (x):
... x ['bar'] = 22
...
>>> my_dict = {'foo': 1, 'bar': 2, 'baz': 3}
>>> f (my_dict)
>>> my_dict
{'foo': 1, 'bar': 22, 'baz': 3}
Здесь f () использует x в качестве ссылки для внесения изменений в my_dict .Это изменение отражается в вызывающей среде после возврата f () .
Сводка по передаче аргументов
Передачу аргумента в Python можно резюмировать следующим образом. Передача неизменяемого объекта , например int , str , tuple или frozenset , в функцию Python действует как передача по значению. Функция не может изменять объект в вызывающей среде.
Передача изменяемого объекта , такого как список , dict или set , действует в некоторой степени - но не в точности - как передача по ссылке.Функция не может переназначить объект оптом, но она может изменять элементы на месте внутри объекта, и эти изменения будут отражены в вызывающей среде.
Побочные эффекты
Итак, в Python вы можете изменить аргумент из функции, чтобы изменение отражалось в вызывающей среде. Но стоит ли вам это делать? Это пример того, что на жаргоне программирования называется побочным эффектом .
В более общем смысле говорят, что функция Python вызывает побочный эффект, если она каким-либо образом изменяет среду своего вызова.Изменение значения аргумента функции - лишь одна из возможностей.
Примечание: Вы, вероятно, знакомы с побочными эффектами из области здоровья человека, где этот термин обычно относится к непредвиденным последствиям лекарств. Часто последствия нежелательны, например, рвота или седативный эффект. С другой стороны, побочные эффекты можно использовать намеренно. Например, некоторые лекарства вызывают стимуляцию аппетита, что может быть полезно, даже если это не является основным назначением лекарства.
Концепция аналогична в программировании. Если побочный эффект является хорошо задокументированной частью спецификации функции, и пользователь функции четко знает, когда и как вызывающая среда может быть изменена, тогда все в порядке. Но программист не всегда может должным образом документировать побочные эффекты или даже не подозревать о возникновении побочных эффектов.
Когда они скрыты или неожиданны, побочные эффекты могут привести к программным ошибкам, которые очень трудно отследить.Как правило, их лучше избегать.
Возврат
Заявление
Что тогда делать функции Python? В конце концов, во многих случаях, если функция не вызывает каких-либо изменений в вызывающей среде, тогда нет никакого смысла в ее вызове. Как функция должна влиять на вызывающего?
Ну, одна из возможностей - использовать возвращаемых значений функции . Оператор return в функции Python служит двум целям:
- Он немедленно завершает функцию и передает управление выполнением обратно вызывающей стороне.
- Он предоставляет механизм, с помощью которого функция может передавать данные обратно вызывающей стороне.
Выход из функции
Внутри функции оператор return вызывает немедленный выход из функции Python и передачу выполнения обратно вызывающей стороне:
>>>
>>> def f ():
... печать ('фу')
... печать ('полоса')
... возвращаться
...
>>> f ()
фу
бар
В этом примере оператор return фактически лишний.Функция вернется к вызывающей стороне, когда упадет с конца , то есть после выполнения последнего оператора тела функции. Таким образом, эта функция будет вести себя идентично без оператора return .
Однако return операторов не обязательно должны быть в конце функции. Они могут появляться в любом месте тела функции и даже несколько раз. Рассмотрим этот пример:
>>>
1 >>> def f (x):
2 ... если x <0:
3... возвращаться
4 ... если x> 100:
5 ... вернуться
6 ... печать (x)
7 ...
8
9 >>> f (-3)
10 >>> f (105)
11 >>> f (64)
1264
Первые два вызова f () не вызывают никакого вывода, потому что выполняется оператор return и функция завершается преждевременно, прежде чем будет достигнут оператор print () в строке 6.
Такая парадигма может быть полезна для проверки ошибок в функции. Вы можете проверить несколько условий ошибки в начале функции, с возвратом операторов, которые выручают, если есть проблема:
def f ():
если error_cond1:
возвращаться
если error_cond2:
возвращаться
если error_cond3:
возвращаться
<нормальная обработка>
Если ни одно из условий ошибки не обнаружено, функция может продолжить свою обычную обработку.
Возврат данных вызывающему абоненту
Помимо выхода из функции, оператор return также используется для передачи данных обратно вызывающей стороне . Если за оператором return внутри функции Python следует выражение, то в вызывающей среде вызов функции оценивается как значение этого выражения:
>>>
1 >>> def f ():
2 ... вернуть 'foo'
3 ...
4
5 >>> s = f ()
6 >>> с
7'фу '
Здесь значение выражения f () в строке 5 равно 'foo' , которое впоследствии присваивается переменной s .
Функция может возвращать любой тип объекта . В Python это означает что угодно. В вызывающей среде вызов функции может использоваться синтаксически любым способом, который имеет смысл для типа объекта, который возвращает функция.
Например, в этом коде f () возвращает словарь. Тогда в вызывающей среде выражение f () представляет словарь, а f () ['baz'] является действительной ключевой ссылкой в этот словарь:
>>>
>>> def f ():
... return dict (foo = 1, bar = 2, baz = 3)
...
>>> f ()
{'foo': 1, 'bar': 2, 'baz': 3}
>>> f () ['баз']
3
В следующем примере f () возвращает строку, которую можно разрезать, как любую другую строку:
>>>
>>> def f ():
... вернуть 'foobar'
...
>>> f () [2: 4]
'ob'
Здесь f () возвращает список, который можно проиндексировать или разрезать:
>>>
>>> def f ():
... return ['foo', 'bar', 'baz', 'qux']
...
>>> f ()
['foo', 'bar', 'baz', 'qux']
>>> f () [2]
'баз'
>>> f () [:: - 1]
['qux', 'baz', 'bar', 'foo']
Если в операторе return указано несколько выражений, разделенных запятыми, они упаковываются и возвращаются как кортеж:
>>>
>>> def f ():
... вернуть 'foo', 'bar', 'baz', 'qux'
...
>>> тип (f ())
<класс 'кортеж'>
>>> t = f ()
>>> т
('foo', 'bar', 'baz', 'qux')
>>> a, b, c, d = f ()
>>> print (f'a = {a}, b = {b}, c = {c}, d = {d} ')
a = foo, b = bar, c = baz, d = qux
Если возвращаемое значение не указано, функция Python возвращает специальное значение Python Нет :
>>>
>>> def f ():
... возвращаться
...
>>> print (f ())
Никто
То же самое происходит, если тело функции вообще не содержит оператора return и функция падает с конца:
>>>
>>> def g ():
... проходить
...
>>> print (g ())
Никто
Напомним, что Нет является ложным при оценке в логическом контексте.
Поскольку функции, которые выходят через пустой , возвращают оператор или выпадают из конца, возвращают Нет , вызов такой функции может использоваться в логическом контексте:
>>>
>>> def f ():
... возвращаться
...
>>> def g ():
... проходить
...
>>> если f () или g ():
... печать ('да')
... еще:
... печать ('нет')
...
нет
Здесь вызовы как f () , так и g () являются ложными, поэтому f () или g () также являются, и выполняется условие else .
Возвращаясь к побочным эффектам
Предположим, вы хотите написать функцию, которая принимает целочисленный аргумент и удваивает его. То есть вы хотите передать в функцию целочисленную переменную, и когда функция вернется, значение переменной в вызывающей среде должно быть вдвое больше, чем было.В Паскале это можно сделать с помощью передачи по ссылке:
1процедура double (var x: integer);
2начало
3 х: = х * 2;
4end;
5
6вар
7 x: целое число;
8
9начало
10 х: = 5;
11 Writeln ('Перед вызовом процедуры:', x);
12 двойных (х);
13 Writeln ('После вызова процедуры:', x);
14 конец.
Выполнение этого кода дает следующий результат, который подтверждает, что double () действительно изменяет x в вызывающей среде:
Перед процедурой позвонить: 5
После вызова процедуры: 10
В Python это не сработает.Как вы теперь знаете, целые числа Python неизменяемы, поэтому функция Python не может изменить целочисленный аргумент с помощью побочного эффекта:
>>>
>>> def double (x):
... х * = 2
...
>>> х = 5
>>> двойной (х)
>>> х
5
Однако вы можете использовать возвращаемое значение для получения аналогичного эффекта. Просто напишите double () , чтобы он принимал целочисленный аргумент, удваивал его и возвращал удвоенное значение. Затем вызывающий абонент отвечает за присвоение, изменяющее исходное значение:
>>>
>>> def double (x):
... вернуть x * 2
...
>>> х = 5
>>> х = двойной (х)
>>> х
10
Возможно, это предпочтительнее модификации по побочным эффектам. Совершенно очевидно, что x изменяется в вызывающей среде, потому что вызывающий делает это сам. В любом случае, это единственный вариант, потому что модификация с помощью побочного эффекта в этом случае не работает.
Тем не менее, даже в тех случаях, когда можно изменить аргумент с помощью побочного эффекта, использование возвращаемого значения может быть более ясным.Предположим, вы хотите удвоить каждый элемент в списке. Поскольку списки изменяемы, вы можете определить функцию Python, которая изменяет список на месте:
>>>
>>> def double_list (x):
... я = 0
... пока я >> a = [1, 2, 3, 4, 5]
>>> double_list (а)
>>> а
[2, 4, 6, 8, 10]
В отличие от double () в предыдущем примере, double_list () фактически работает так, как задумано.Если в документации для функции четко указано, что содержимое аргумента списка изменено, это может быть разумной реализацией.
Однако вы также можете написать double_list () , чтобы передать желаемый список обратно по возвращаемому значению и позволить вызывающей стороне выполнить назначение, аналогично тому, как double () было переписано в предыдущем примере:
>>>
>>> def double_list (x):
... r = []
... для i в x:
... р.добавить (я * 2)
... вернуть г
...
>>> a = [1, 2, 3, 4, 5]
>>> а = двойной_лист (а)
>>> а
[2, 4, 6, 8, 10]
Оба подхода работают одинаково хорошо. Как это часто бывает, это вопрос стиля и личных предпочтений. Побочные эффекты не обязательно являются абсолютным злом, и они имеют свое место, но поскольку практически все может быть возвращено из функции, то же самое обычно можно достичь и с помощью возвращаемых значений.
Списки аргументов переменной длины
В некоторых случаях, когда вы определяете функцию, вы можете не знать заранее, сколько аргументов вы хотите, чтобы она принимала.Предположим, например, что вы хотите написать функцию Python, которая вычисляет среднее нескольких значений. Начать можно примерно так:
>>>
>>> def avg (a, b, c):
... return (a + b + c) / 3
...
Все хорошо, если вы хотите усреднить три значения:
Однако, как вы уже видели, когда используются позиционные аргументы, количество переданных аргументов должно соответствовать количеству объявленных параметров. Тогда ясно, что с этой реализацией avg () для любого количества значений, кроме трех, не все в порядке:
>>>
>>> ср (1, 2, 3, 4)
Отслеживание (последний вызов последний):
Файл "", строка 1, в
средн. (1, 2, 3, 4)
TypeError: avg () принимает 3 позиционных аргумента, но было дано 4
Вы можете попробовать определить avg () с дополнительными параметрами:
>>>
>>> def avg (a, b = 0, c = 0, d = 0, e = 0):
....
....
....
...
Это позволяет указывать переменное количество аргументов. Следующие вызовы, по крайней мере, синтаксически верны:
в среднем (1)
ср (1, 2)
средн. (1, 2, 3)
средн. (1, 2, 3, 4)
средн. (1, 2, 3, 4, 5)
Но при таком подходе все еще есть несколько проблем. Во-первых, он по-прежнему позволяет использовать до пяти аргументов, а не произвольное число. Что еще хуже, нет способа отличить указанные аргументы от аргументов, которым разрешено использовать по умолчанию.У функции нет способа узнать, сколько аргументов было передано на самом деле, поэтому она не знает, на что делить:
>>>
>>> def avg (a, b = 0, c = 0, d = 0, e = 0):
... return (a + b + c + d + e) / # На что делить ???
...
Очевидно, и этого не пойдет.
Вы можете написать avg () , чтобы получить единственный аргумент списка:
>>>
>>> def avg (a):
... всего = 0
... для v в:
... всего + = v
... return total / len (a)
...
>>> avg ([1, 2, 3])
2.0
>>> avg ([1, 2, 3, 4, 5])
3.0
По крайней мере, это работает. Он допускает произвольное количество значений и дает правильный результат. В качестве дополнительного бонуса это работает, когда аргумент также является кортежем:
>>>
>>> t = (1, 2, 3, 4, 5)
>>> avg (t)
3.0
Недостатком является то, что дополнительный этап группировки значений в список или кортеж, вероятно, не является тем, чего ожидает пользователь функции, и это не очень элегантно.Каждый раз, когда вы находите код Python, который выглядит неэлегантно, вероятно, есть лучший вариант.
В данном случае действительно есть! Python предоставляет способ передать функции переменное количество аргументов с упаковкой и распаковкой кортежа аргументов с помощью оператора звездочки ( * ).
Упаковка кортежей аргументов
Когда имени параметра в определении функции Python предшествует звездочка ( * ), это указывает на упаковки кортежа аргументов . Все соответствующие аргументы в вызове функции упаковываются в кортеж, на который функция может ссылаться по заданному имени параметра.Вот пример:
>>>
>>> def f (* args):
... печать (аргументы)
... print (тип (аргументы), len (аргументы))
... для x в аргументах:
... печать (x)
...
>>> f (1, 2, 3)
(1, 2, 3)
<класс 'кортеж'> 3
1
2
3
>>> f ('foo', 'bar', 'baz', 'qux', 'quux')
('foo', 'bar', 'baz', 'qux', 'quux')
<класс 'кортеж'> 5
фу
бар
баз
qux
quux
В определении f () спецификация параметра * args указывает на упаковку кортежа.При каждом вызове f () аргументы упаковываются в кортеж, на который функция может ссылаться по имени args . Можно использовать любое имя, но аргументов выбирают настолько часто, что это практически стандарт.
Используя упаковку кортежей, вы можете очистить avg () следующим образом:
>>>
>>> def avg (* args):
... всего = 0
... для i в аргументах:
... всего + = я
... вернуть total / len (args)
...
>>> avg (1, 2, 3)
2.0
>>> avg (1, 2, 3, 4, 5)
3.0
Более того, вы можете привести его в порядок, заменив цикл на встроенной функцией Python sum () , которая суммирует числовые значения в любой итерации:
>>>
>>> def avg (* args):
... вернуть сумму (аргументы) / len (аргументы)
...
>>> avg (1, 2, 3)
2.0
>>> avg (1, 2, 3, 4, 5)
3.0
Теперь avg () написан лаконично и работает так, как задумано.
Тем не менее, в зависимости от того, как этот код будет использоваться, может быть, еще есть над чем поработать. Как написано, avg () вызовет исключение TypeError , если какие-либо аргументы не являются числовыми:
>>>
>>> avg (1, 'foo', 3)
Отслеживание (последний вызов последний):
Файл "", строка 1, в
Файл "", строка 2, в среднем
TypeError: неподдерживаемые типы операндов для +: 'int' и 'str'
Для максимальной надежности следует добавить код, проверяющий, что аргументы имеют правильный тип.Позже в этой серии руководств вы узнаете, как перехватывать исключения, такие как TypeError , и обрабатывать их соответствующим образом. Вы также можете проверить исключения Python: Введение.
Распаковка кортежа аргументов
Аналогичная операция доступна на другой стороне уравнения в вызове функции Python. Когда аргументу в вызове функции предшествует звездочка ( * ), это указывает на то, что аргумент представляет собой кортеж, который должен быть распакованным и переданным в функцию как отдельные значения:
>>>
>>> def f (x, y, z):
... print (f'x = {x} ')
... print (f'y = {y} ')
... печать (f'z = {z} ')
...
>>> f (1, 2, 3)
х = 1
у = 2
г = 3
>>> t = ('фу', 'бар', 'баз')
>>> f (* t)
x = foo
y = бар
z = baz
В этом примере * t в вызове функции указывает, что t - это кортеж, который следует распаковать. Распакованные значения 'foo' , 'bar' и 'baz' назначаются параметрам x , y и z соответственно.
Хотя этот тип распаковки называется распаковкой кортежей , он работает не только с кортежами. Оператор звездочка ( * ) может применяться к любой итерации в вызове функции Python. Например, список или набор тоже можно распаковать:
>>>
>>> a = ['foo', 'bar', 'baz']
>>> тип (а)
<список классов>
>>> f (* а)
x = foo
y = бар
z = baz
>>> s = {1, 2, 3}
>>> тип (ы)
<класс 'набор'>
>>> f (* s)
х = 1
у = 2
г = 3
Вы даже можете использовать упаковку и распаковку кортежей одновременно:
>>>
>>> def f (* args):
... print (тип (аргументы), аргументы)
...
>>> a = ['foo', 'bar', 'baz', 'qux']
>>> f (* а)
<класс 'кортеж'> ('foo', 'bar', 'baz', 'qux')
Здесь f (* a) указывает, что список a должен быть распакован, а элементы переданы в f () как отдельные значения. Спецификация параметра * args заставляет значения упаковываться обратно в кортеж args .
Упаковка словаря аргументов
Python имеет аналогичный оператор, двойную звездочку ( ** ), который можно использовать с параметрами и аргументами функции Python для указания упаковки словаря и распаковки .Двойная звездочка ( ** ) перед параметром в определении функции Python указывает, что соответствующие аргументы, которые, как ожидается, будут парами ключ = значение , должны быть упакованы в словарь:
>>>
>>> def f (** kwargs):
... печать (kwargs)
... print (введите (kwargs))
... для ключа val в kwargs.items ():
... print (ключ, '->', val)
...
>>> f (foo = 1, bar = 2, baz = 3)
{'foo': 1, 'bar': 2, 'baz': 3}
<класс 'dict'>
foo -> 1
бар -> 2
баз -> 3
В этом случае аргументы foo = 1 , bar = 2 и baz = 3 упаковываются в словарь, на который функция может ссылаться по имени kwargs .Опять же, можно использовать любое имя, но своеобразное kwargs (которое является сокращением от ключевого слова args ) почти стандартно. Вам не обязательно его придерживаться, но если вы это сделаете, то любой, кто знаком с соглашениями о кодировании Python, сразу поймет, что вы имеете в виду.
Распаковка словаря аргументов
Распаковка словаря аргументов аналогична распаковке кортежа аргументов. Когда двойная звездочка ( ** ) предшествует аргументу в вызове функции Python, она указывает, что аргумент является словарем, который должен быть распакован, с полученными элементами, переданными в функцию как аргументы ключевого слова:
>>>
>>> def f (a, b, c):
... print (F'a = {a} ')
... печать (F'b = {b} ')
... печать (F'c = {c} ')
...
>>> d = {'a': 'foo', 'b': 25, 'c': 'qux'}
>>> е (** д)
a = foo
б = 25
c = qux
Элементы в словаре d распаковываются и передаются в f () как аргументы ключевого слова. Итак, f (** d) эквивалентно f (a = 'foo', b = 25, c = 'qux') :
>>>
>>> f (a = 'foo', b = 25, c = 'qux')
a = foo
б = 25
c = qux
На самом деле, проверьте это:
>>>
>>> f (** dict (a = 'foo', b = 25, c = 'qux'))
a = foo
б = 25
c = qux
Здесь dict (a = 'foo', b = 25, c = 'qux') создает словарь из указанных пар ключ / значение.Затем оператор двойной звездочки ( ** ) распаковывает его и передает ключевые слова в f () .
Собираем все вместе
Думайте о * args как о позиционном списке аргументов переменной длины, а ** kwargs как о списке аргументов ключевого слова переменной длины.
Все три - стандартные позиционные параметры, * args и ** kwargs - могут использоваться в одном определении функции Python. Если да, то их следует указывать в таком порядке:
>>>
>>> def f (a, b, * args, ** kwargs):
... print (F'a = {a} ')
... печать (F'b = {b} ')
... print (F'args = {args} ')
... печать (F'kwargs = {kwargs} ')
...
>>> f (1, 2, 'foo', 'bar', 'baz', 'qux', x = 100, y = 200, z = 300)
а = 1
b = 2
args = ('foo', 'bar', 'baz', 'qux')
kwargs = {'x': 100, 'y': 200, 'z': 300}
Это обеспечивает столько гибкости, сколько вам может понадобиться в функциональном интерфейсе!
Множественные распаковки в вызове функции Python
Python версии 3.5 представил поддержку дополнительных обобщений распаковки, как указано в PEP 448.Одна вещь, которую позволяют эти улучшения, - это нескольких распаковок за один вызов функции Python:
>>>
>>> def f (* args):
... для i в аргументах:
... печать (я)
...
>>> a = [1, 2, 3]
>>> t = (4, 5, 6)
>>> s = {7, 8, 9}
>>> f (* a, * t, * s)
1
2
3
4
5
6
8
9
7
Вы также можете указать несколько распаковок словарей в вызове функции Python:
>>>
>>> def f (** kwargs):
... для k, v в kwargs.items ():
... print (k, '->', v)
...
>>> d1 = {'a': 1, 'b': 2}
>>> d2 = {'x': 3, 'y': 4}
>>> f (** d1, ** d2)
а -> 1
б -> 2
х -> 3
у -> 4
Примечание: Это расширение доступно только в Python версии 3.5 или новее. Если вы попробуете это в более ранней версии, то получите исключение SyntaxError .
Кстати, операторы распаковки * и ** применяются не только к переменным, как в примерах выше.Вы также можете использовать их с литералами, которые повторяются:
>>>
>>> def f (* args):
... для i в аргументах:
... печать (я)
...
>>> f (* [1, 2, 3], * [4, 5, 6])
1
2
3
4
5
6
>>> def f (** kwargs):
... для k, v в kwargs.items ():
... print (k, '->', v)
...
>>> f (** {'a': 1, 'b': 2}, ** {'x': 3, 'y': 4})
а -> 1
б -> 2
х -> 3
у -> 4
Здесь литеральные списки [1, 2, 3] и [4, 5, 6] указаны для распаковки кортежей, а буквальные словари {'a': 1, 'b': 2} и {'x': 3, 'y': 4} указаны для распаковки словаря.
Аргументы только для ключевых слов
Функцию Python в версии 3.x можно определить так, чтобы она принимала аргументов только для ключевых слов . Это аргументы функции, которые должны быть указаны с помощью ключевого слова. Давайте рассмотрим ситуацию, в которой это может быть полезно.
Предположим, вы хотите написать функцию Python, которая принимает переменное количество строковых аргументов, объединяет их вместе, разделенные точкой ( "." ), и выводит их на консоль. Для начала подойдет что-то вроде этого:
>>>
>>> def concat (* args):
... print (f '-> {".". join (args)}')
...
>>> concat ('a', 'b', 'c')
-> a.b.c
>>> concat ('foo', 'bar', 'baz', 'qux').
-> foo.bar.baz.qux
В существующем виде выходной префикс жестко запрограммирован на строку '->' . Что, если вы хотите изменить функцию, чтобы она также принимала это как аргумент, чтобы пользователь мог указать что-то еще? Это одна возможность:
>>>
>>> def concat (префикс, * args):
... print (f '{prefix} {".".join (аргументы)} ')
...
>>> concat ('//', 'a', 'b', 'c')
//a.b.c
>>> concat ('...', 'foo', 'bar', 'baz', 'qux')
... foo.bar.baz.qux
Работает так, как рекламируется, но в этом решении есть несколько нежелательных моментов:
Префикс
Строкаобъединяется вместе со строками, которые необходимо объединить. Просто взглянув на вызов функции, неясно, обрабатывается ли первый аргумент иначе, чем остальные. Чтобы узнать это, вам нужно вернуться назад и посмотреть на определение функции.Префикс
Вы могли подумать, что можете решить вторую проблему, указав параметр со значением по умолчанию, например, например:
>>>
>>> def concat (prefix = '->', * args):
... print (f '{префикс} {".". join (args)}')
...
К сожалению, это работает не совсем правильно. Префикс - это позиционный параметр , поэтому интерпретатор предполагает, что первый аргумент, указанный в вызове функции, является предполагаемым выходным префиксом.Это означает, что его нельзя пропустить и получить значение по умолчанию:
.
>>>
>>> concat ('a', 'b', 'c')
ab.c
Что если вы попытаетесь указать префикс в качестве аргумента ключевого слова? Ну, сначала не указывайте:
>>>
>>> concat (prefix = '//', 'a', 'b', 'c')
Файл "", строка 1
SyntaxError: позиционный аргумент следует за аргументом ключевого слова
Как вы видели ранее, когда даны оба типа аргументов, все позиционные аргументы должны предшествовать любым аргументам ключевого слова.
Однако вы также не можете указать его последним:
>>>
>>> concat ('a', 'b', 'c', prefix = '...')
Отслеживание (последний вызов последний):
Файл "", строка 1, в
TypeError: concat () получил несколько значений для аргумента prefix
Опять же, префикс является позиционным параметром, поэтому ему назначается первый аргумент, указанный в вызове (в данном случае это 'a' ). Затем, когда он снова указывается в качестве аргумента ключевого слова в конце, Python думает, что он был назначен дважды.
Параметры только для ключевых слов помогают решить эту дилемму. В определении функции укажите * args , чтобы указать переменное количество позиционных аргументов, а затем укажите префикс , после которого :
>>>
>>> def concat (* args, prefix = '->'):
... print (f '{префикс} {".". join (args)}')
...
В этом случае префикс становится параметром, содержащим только ключевое слово. Его значение никогда не будет заполнено позиционным аргументом.Его можно указать только с помощью именованного аргумента ключевого слова:
>>>
>>> concat ('a', 'b', 'c', prefix = '...')
... a.b.c
Обратите внимание, что это возможно только в Python 3. В версиях Python 2.x указание дополнительных параметров после параметра * args переменных аргументов вызывает ошибку.
Аргументы, содержащие только ключевое слово, позволяют функции Python принимать переменное количество аргументов, за которыми следует одна или несколько дополнительных опций в качестве аргументов ключевого слова.Если вы хотите изменить concat () , чтобы можно было указать и символ-разделитель, вы можете добавить дополнительный аргумент, состоящий только из ключевых слов:
>>>
>>> def concat (* args, prefix = '->', sep = '.'):
... print (f '{префикс} {sep.join (args)}')
...
>>> concat ('a', 'b', 'c')
-> a.b.c
>>> concat ('a', 'b', 'c', prefix = '//')
//a.b.c
>>> concat ('a', 'b', 'c', prefix = '//', sep = '-')
// а-б-в
Если параметру, содержащему только ключевое слово, присвоено значение по умолчанию в определении функции (как в приведенном выше примере), а ключевое слово опущено при вызове функции, то предоставляется значение по умолчанию:
>>>
>>> concat ('a', 'b', 'c')
-> а.до н.э
Если, с другой стороны, параметру не присвоено значение по умолчанию, то он становится обязательным, и если его не указать, возникает ошибка:
>>>
>>> def concat (* args, префикс):
... print (f '{префикс} {".". join (args)}')
...
>>> concat ('a', 'b', 'c', prefix = '...')
... a.b.c
>>> concat ('a', 'b', 'c')
Отслеживание (последний вызов последний):
Файл "", строка 1, в
TypeError: в concat () отсутствует 1 обязательный аргумент, содержащий только ключевое слово: 'prefix'
Что делать, если вы хотите определить функцию Python, которая принимает аргумент, состоящий только из ключевых слов, но не принимает переменное количество позиционных аргументов? Например, следующая функция выполняет указанную операцию с двумя числовыми аргументами:
>>>
>>> def oper (x, y, op = '+'):
... если op == '+':
... вернуть x + y
... elif op == '-':
... вернуть x - y
... elif op == '/':
... вернуть x / y
... еще:
... return None
...
>>> опер (3, 4)
7
>>> опер (3, 4, '+')
7
>>> опер (3, 4, '/')
0,75
Если вы хотите сделать op параметром, содержащим только ключевое слово, вы можете добавить посторонний параметр аргумента фиктивной переменной и просто игнорировать его:
>>>
>>> def oper (x, y, * ignore, op = '+'):
... если op == '+':
... вернуть x + y
... elif op == '-':
... вернуть x - y
... elif op == '/':
... вернуть x / y
... еще:
... return None
...
>>> oper (3, 4, op = '+')
7
>>> oper (3, 4, op = '/')
0,75
Проблема с этим решением состоит в том, что * ignore поглощает любые посторонние позиционные аргументы, которые могут быть включены:
>>>
>>> oper (3, 4, «Мне здесь не место»)
7
>>> oper (3, 4, «Мне здесь не место», op = '/')
0.75
В этом примере не должно быть дополнительного аргумента (как объявляет сам аргумент). Вместо того, чтобы тихо добиться успеха, это действительно должно привести к ошибке. То, что это не так, в лучшем случае неопрятно. В худшем случае это может привести к вводящему в заблуждение результату:
Чтобы исправить это, версия 3 позволяет параметру аргумента переменной в определении функции Python быть просто звездочкой ( * ) с опущенным именем:
>>>
>>> def oper (x, y, *, op = '+'):
... если op == '+':
... вернуть x + y
... elif op == '-':
... вернуть x - y
... elif op == '/':
... вернуть x / y
... еще:
... return None
...
>>> oper (3, 4, op = '+')
7
>>> oper (3, 4, op = '/')
0,75
>>> oper (3, 4, «Мне здесь не место»)
Отслеживание (последний вызов последний):
Файл "", строка 1, в
TypeError: oper () принимает 2 позиционных аргумента, но было дано 3
>>> опер (3, 4, '+')
Отслеживание (последний вызов последний):
Файл "", строка 1, в
TypeError: oper () принимает 2 позиционных аргумента, но было дано 3
Параметр простого переменного аргумента * указывает, что позиционных параметров больше нет.Это поведение генерирует соответствующие сообщения об ошибках, если указаны дополнительные. Он позволяет следовать параметрам, содержащим только ключевые слова.
Только позиционные аргументы
Начиная с Python 3.8, параметры функции также могут быть объявлены только позиционно , что означает, что соответствующие аргументы должны быть предоставлены позиционно и не могут быть указаны с помощью ключевого слова.
Чтобы обозначить некоторые параметры как позиционные, вы указываете косую черту (/) в списке параметров определения функции.Любые параметры слева от косой черты (/) должны быть указаны позиционно. Например, в следующем определении функции x и y являются позиционными параметрами, но z может быть задано ключевым словом:
>>>
>>> # Это Python 3.8
>>> def f (x, y, /, z):
... print (f'x: {x} ')
... print (f'y: {y} ')
... print (f'z: {z} ')
...
Это означает, что действительны следующие вызовы:
>>>
>>> f (1, 2, 3)
х: 1
г: 2
z: 3
>>> f (1, 2, z = 3)
х: 1
г: 2
z: 3
Однако следующий звонок на номер f () недействителен:
>>>
>>> f (x = 1, y = 2, z = 3)
Отслеживание (последний вызов последний):
Файл "", строка 1, в
TypeError: f () получила некоторые позиционные аргументы, переданные как аргументы ключевого слова:
'х, у'
Позиционные указатели и указатели только с ключевыми словами могут использоваться в одном и том же определении функции:
>>>
>>> # Это Python 3.8
>>> def f (x, y, /, z, w, *, a, b):
... print (x, y, z, w, a, b)
...
>>> f (1, 2, z = 3, w = 4, a = 5, b = 6)
1 2 3 4 5 6
>>> f (1, 2, 3, w = 4, a = 5, b = 6)
1 2 3 4 5 6
В этом примере:
-
xиyявляются только позиционными. -
aиb- только ключевые слова. -
zиwможно указать позиционно или по ключевому слову.
Для получения дополнительной информации о позиционных параметрах см. Основные моменты выпуска Python 3.8.
Строки документации
Когда первая инструкция в теле функции Python является строковым литералом, она называется строкой документации функции . Строка документации используется для предоставления документации для функции. Он может содержать назначение функции, аргументы, которые она принимает, информацию о возвращаемых значениях или любую другую информацию, которая, по вашему мнению, будет полезной.
Ниже приведен пример определения функции со строкой документации:
>>>
>>> def avg (* args):
... "" "Возвращает среднее значение списка числовых значений." ""
... вернуть сумму (аргументы) / len (аргументы)
...
Технически, строки документации могут использовать любой из механизмов цитирования Python, но рекомендуется использовать тройные кавычки с использованием символов двойных кавычек ( "" "), как показано выше. Если строка документации умещается в одной строке, то котировки закрытия должны находиться на той же строке, что и котировки открытия.
Многострочные строки документации используются для более объемной документации.Многострочная строка документации должна состоять из итоговой строки, за которой следует пустая строка, за которой следует более подробное описание. Котировки закрытия должны быть на отдельной строке:
>>>
>>> def foo (bar = 0, baz = 1):
... "" "Выполните преобразование foo.
...
... Аргументы ключевого слова:
... bar - величина по оси бара (по умолчанию = 0)
... baz - величина по оси baz (по умолчанию = 1)
... "" "
...
...
Форматирование строки документации и семантические соглашения подробно описаны в PEP 257.
Когда определена строка документации, интерпретатор Python назначает ее специальному атрибуту функции с именем __doc__ . Этот атрибут является одним из набора специализированных идентификаторов в Python, которые иногда называют магическими атрибутами или магическими методами , поскольку они предоставляют специальные языковые функции.
Примечание: Эти атрибуты также упоминаются с помощью атрибутов dunder красочных псевдонимов и методов dunder. Слово dunder объединяет d из double и под из символа подчеркивания ( _ ).В будущих уроках этой серии вы встретите еще много неприятных атрибутов и методов.
Вы можете получить доступ к строке документации функции с помощью выражения . Строки документации для приведенных выше примеров могут отображаться следующим образом:
>>>
>>> print (ср .__ doc__)
Возвращает среднее значение списка числовых значений.
>>> печать (foo .__ doc__)
Выполните преобразование foo.
Аргументы ключевого слова:
bar - величина по оси бара (по умолчанию = 0)
baz - величина по оси baz (по умолчанию = 1)
В интерактивном интерпретаторе Python вы можете ввести help (, чтобы отобразить строку документации для :
>>>
>>> справка (в среднем)
Справка по функции avg в модуле __main__:
avg (* аргументы)
Возвращает среднее значение списка числовых значений.>>> help (foo)
Справка по функции foo в модуле __main__:
foo (bar = 0, baz = 1)
Выполните преобразование foo.
Аргументы ключевого слова:
bar - величина по оси бара (по умолчанию = 0)
baz - величина по оси baz (по умолчанию = 1)
Считается хорошей практикой кодирования указывать строку документации для каждой определяемой вами функции Python. Дополнительные сведения о строках документации см. В документе «Документирование кода Python: полное руководство».
Аннотации функций Python
Начиная с версии 3.0, Python предоставляет дополнительную возможность для документирования функции, которая называется аннотацией функции . Аннотации позволяют прикреплять метаданные к параметрам функции и возвращаемому значению.
Чтобы добавить аннотацию к параметру функции Python, вставьте двоеточие (: ), за которым следует любое выражение после имени параметра в определении функции. Чтобы добавить аннотацию к возвращаемому значению, добавьте символы -> и любое выражение между закрывающей скобкой списка параметров и двоеточием, завершающим заголовок функции.Вот пример:
>>>
>>> def f (a: '', b: '') -> '':
... проходить
...
Аннотация для параметра a - это строка '' , для b строка '' , а для значения, возвращаемого функцией, строка '.
Интерпретатор Python создает словарь из аннотаций и назначает их другому специальному атрибуту dunder функции с именем __annotations__ .Аннотации для функции Python f () , показанные выше, могут отображаться следующим образом:
>>>
>>> f .__ annotations__
{'a': '', 'b': '', 'return': ''}
Ключи для параметров - это имена параметров. Ключом для возвращаемого значения является строка 'return' :
>>>
>>> f .__ annotations __ ['a']
""
>>> f .__ аннотации __ ['b']
''
>>> е.__annotations __ ['return']
''
Обратите внимание, что аннотации не ограничиваются строковыми значениями. Это может быть любое выражение или объект. Например, вы можете комментировать объекты типа:
>>>
>>> def f (a: int, b: str) -> float:
... print (a, b)
... вернуть (3.5)
...
>>> f (1, 'фу')
1 фу
3.5
>>> f .__ annotations__
{'a': , 'b': , 'return': }
Аннотация может быть даже составным объектом, например списком или словарем, поэтому к параметрам и возвращаемому значению можно прикрепить несколько элементов метаданных:
>>>
>>> def area (
... р: {
... 'desc': 'радиус круга',
... 'тип': поплавок
...}) -> \
... {
... 'desc': 'площадь круга',
... 'тип': поплавок
...}:
... return 3.14159 * (r ** 2)
...
>>> площадь (2.5)
19,6349375
>>> area .__ annotations__
{'r': {'desc': 'радиус круга', 'type': },
'return': {'desc': 'область круга', 'type': }}
>>> area .__ annotations __ ['r'] ['desc']
'радиус круга'
>>> площадь.__annotations __ ['return'] ['type']
<класс 'float'>
В приведенном выше примере аннотация прикреплена к параметру r и возвращаемому значению. Каждая аннотация представляет собой словарь, содержащий описание строки и объект типа.
Если вы хотите присвоить значение по умолчанию параметру, имеющему аннотацию, то значение по умолчанию идет после аннотации:
>>>
>>> def f (a: int = 12, b: str = 'baz') -> float:
... print (a, b)
... вернуть (3.5)
...
>>> f .__ annotations__
{'a': , 'b': , 'return': }
>>> f ()
12 баз
3.5
Что делают аннотации? Откровенно говоря, они почти ничего не делают. Они просто вроде как там. Давайте снова посмотрим на один из примеров сверху, но с небольшими изменениями:
>>>
>>> def f (a: int, b: str) -> float:
... print (a, b)
... вернуть 1, 2, 3
...
>>> f ('фу', 2.5)
foo 2.5
(1, 2, 3)
Что здесь происходит? Аннотации для f () указывают, что первый аргумент - int , второй аргумент - str , а возвращаемое значение - float . Но последующий звонок на f () нарушает все правила! Аргументы: str и float соответственно, а возвращаемое значение - кортеж. И все же переводчик позволяет всему этому скользить без всяких нареканий.
Аннотации не накладывают семантических ограничений на код вообще. Это просто биты метаданных, прикрепленные к параметрам функции Python и возвращаемому значению. Python послушно прячет их в словаре, присваивает словарю атрибут dunder функции __annotations__ , и все. Аннотации являются необязательными и вообще не влияют на выполнение функций Python.
Процитирую Амала в Амаль и ночные посетители : «Какая тогда польза от этого?»
Для начала, аннотации - это хорошая документация .Вы, конечно, можете указать ту же информацию в строке документации, но размещение ее непосредственно в определении функции добавляет ясности. Типы аргументов и возвращаемое значение очевидны с первого взгляда для такого заголовка функции:
def f (a: int, b: str) -> float:
Конечно, интерпретатор не требует соблюдения указанных типов, но, по крайней мере, они понятны для тех, кто читает определение функции.
Deep Dive: принудительная проверка типов
Если бы вы были склонны, вы могли бы добавить код для принудительного применения типов, указанных в аннотациях к функциям.Вот функция, которая проверяет фактический тип каждого аргумента на соответствие тому, что указано в аннотации для соответствующего параметра. Он отображает
Истинно, если они соответствуют, иЛожь, если они не соответствуют:>>>
>>> def f (a: int, b: str, c: float): ... импорт осмотреть ... args = inspect.getfullargspec (f) .args ... аннотации = inspect.getfullargspec (f) .annotations ... для x в аргументах: ... print (x, '->', ... 'arg is', type (locals () [x]), ',', ... 'annotation is', annotations [x], ... '/', (type (locals () [x])) is annotations [x]) ... >>> f (1, 'foo', 3.3) a -> arg - это, аннотация - это / True b -> arg - , аннотация - / True c -> arg - , аннотация - / True >>> f ('фу', 4.3, 9) a -> arg - , аннотация - / False b -> arg - , аннотация - / False c -> arg - , аннотация - / False >>> f (1, 'фу', 'бар') a -> arg - это , аннотация - это / True b -> arg - , аннотация - / True c -> arg - , аннотация - / False (Модуль
inspectсодержит функции, которые получают полезную информацию о живых объектах - в данном случае функцияf ().)Функция, определенная как указанная выше, при желании может предпринять какие-то корректирующие действия, когда обнаружит, что переданные аргументы не соответствуют типам, указанным в аннотациях.
Фактически, схема использования аннотаций для выполнения проверки статического типа в Python описана в PEP 484. Доступна бесплатная программа проверки статического типа для Python под названием mypy, основанная на спецификации PEP 484.
Есть еще одно преимущество использования аннотаций.Стандартизованный формат, в котором аннотационная информация хранится в атрибуте __annotations__ , позволяет анализировать сигнатуры функций автоматическими инструментами.
В аннотациях нет ничего особенного. Вы даже можете определить свой собственный без специального синтаксиса, предоставляемого Python. Вот определение функции Python с аннотациями объекта типа, прикрепленными к параметрам и возвращаемому значению:
>>>
>>> def f (a: int, b: str) -> float:
... возвращаться
...
>>> f .__ annotations__
{'a': , 'b': , 'return': }
По сути, это та же функция со словарем __annotations__ , созданным вручную:
>>>
>>> def f (a, b):
... возвращаться
...
>>> f .__ annotations__ = {'a': int, 'b': str, 'return': float}
>>> f .__ annotations__
{'a': , 'b': , 'return': }
Эффект идентичен в обоих случаях, но первый на первый взгляд визуально более привлекателен и удобочитаем.
Фактически, атрибут __annotations__ не сильно отличается от большинства других атрибутов функции. Например, его можно динамически изменять. Вы можете использовать атрибут возвращаемого значения, чтобы подсчитать, сколько раз функция выполняется:
>>>
>>> def f () -> 0:
... f .__ аннотации __ ['return'] + = 1
... print (f "f () был выполнен {f .__ annotations __ ['return']} время (с)")
...
>>> f ()
f () выполнено 1 раз (а)
>>> f ()
f () было выполнено 2 раза (а)
>>> f ()
f () было выполнено 3 раза (а)
Аннотации функций Python - это не что иное, как словари метаданных.Просто так получилось, что вы можете создать их с помощью удобного синтаксиса, поддерживаемого интерпретатором. Это все, что вы хотите из них сделать.
Заключение
По мере роста приложений становится все более важным модулировать код, разбивая его на более мелкие функции управляемого размера. Надеюсь, теперь у вас есть все необходимые инструменты для этого.
Вы узнали:
- Как создать определяемую пользователем функцию в Python
- Несколько разных способов передать аргументов функции
- Как можно, , вернуть данных из функции ее вызывающей стороне
- Как добавить документацию к функциям с строками документации и аннотациями
Следующими в этой серии являются два руководства, которые охватывают поиск и сопоставление с образцом .Вы получите подробный обзор модуля Python под названием re , который содержит функции для поиска и сопоставления с использованием универсального синтаксиса шаблонов, называемого регулярным выражением .
Смотреть сейчас В этом руководстве есть связанный видеокурс, созданный командой Real Python. Просмотрите его вместе с письменным руководством, чтобы углубить свое понимание: Определение и вызов функций Python
Функции Python - GeeksforGeeks
Функция в Python - это совокупность связанных операторов, предназначенных для выполнения вычислительной, логической или оценочной задачи.Идея состоит в том, чтобы объединить некоторые часто или многократно выполняемые задачи и создать функцию, чтобы вместо того, чтобы писать один и тот же код снова и снова для разных входов, мы могли вызывать функцию, чтобы повторно использовать код, содержащийся в ней, снова и снова.
Функции могут быть как встроенными, так и определяемыми пользователем. Это помогает программе быть краткой, неповторяющейся и организованной.
Синтаксис:
def имя_функции (параметры):
"" "строка документации" ""
оператор (ы) Пример:
Python
47 |
|
Вывод:
Здравствуйте! выродки!
Оператор return
Оператор return используется для выхода из функции и возврата к вызывающей функции и возврата указанного значения или элемента данных вызывающей стороне.
Синтаксис: return [список_выражений]
Оператор return может состоять из переменной, выражения или константы, которая возвращается в конце выполнения функции.Если ничего из вышеперечисленного не присутствует с оператором return, возвращается объект None.
Пример:
Python3
|
Выход:
4 16
Передавать по ссылке или передавать по значению?
Важно отметить, что в Python каждое имя переменной является ссылкой.Когда мы передаем переменную функции, создается новая ссылка на объект. Передача параметров в Python аналогична передаче ссылок в Java.
Пример:
Python
0005 |
Вывод
[20, 11, 12, 13, 14, 15]
Когда мы передаем ссылку и меняем полученная ссылка на что-то еще, связь между переданным и полученным параметром разорвана.Например, рассмотрим приведенную ниже программу.
Python
Другой пример, демонстрирующий, что ссылочная ссылка не работает, если мы назначаем новый va lue (внутри функции). Python
Аргументы по умолчанию: Аргумент по умолчанию — это параметр, который принимает значение по умолчанию, если значение не указано в вызове функции для этого аргумента.В следующем примере показаны аргументы по умолчанию. Python
Выход ('x:', 10)
('y:', 50) Как и аргументы C ++ по умолчанию, любое количество аргументов в функции может иметь значение по умолчанию.Но если у нас есть аргумент по умолчанию, все аргументы справа также должны иметь значения по умолчанию. Аргументы ключевого слова: Идея состоит в том, чтобы позволить вызывающей стороне указывать имя аргумента со значениями, чтобы вызывающей стороне не нужно было запоминать порядок параметров. Python
Выход («Компьютерщики», «Практика») («Гики», «Практика») Аргументы переменной длины:У нас может быть как обычное, так и ключевое слово, переменное количество аргументов.Пожалуйста, смотрите это для деталей. Пример 1: Python
Вывод Здравствуйте Добро пожаловать к GeeksforGeeks Пример 2: Python3
2 первый = mid == для last == Компьютерщики В Python анонимная функция означает, что функция не имеет имени.Как мы уже знаем, ключевое слово def используется для определения обычных функций, а ключевое слово lambda используется для создания анонимных функций. Пожалуйста, смотрите это для деталей. Python3
Быстрые ссылки: Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы. Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS . И чтобы начать свое путешествие по машинному обучению, присоединяйтесь к Машинное обучение - базовый курс Функции Python - упражнения, практика, решение
Функции Python [21 упражнение с решением][ Внизу страницы доступен редактор для написания и выполнения сценариев.] 1. Напишите функцию Python, чтобы найти максимальное из трех чисел. Перейдите в редактор 2. Напишите функцию Python для суммирования всех чисел в списке. Перейдите в редактор 3. Напишите функцию Python для умножения всех чисел в списке. Перейдите в редактор 4. Напишите программу Python для переворота строки. Перейдите в редактор 5. Напишите функцию Python для вычисления факториала числа (неотрицательное целое число). Функция принимает число в качестве аргумента. Перейдите в редактор 6. Напишите функцию Python, чтобы проверить, попадает ли число в заданный диапазон.Перейдите в редактор 7. Напишите функцию Python, которая принимает строку и вычисляет количество букв верхнего и нижнего регистра. Перейдите в редактор 8. Напишите функцию Python, которая принимает список и возвращает новый список с уникальными элементами первого списка.Перейдите в редактор 9. Напишите функцию Python, которая принимает число в качестве параметра и проверяет, является ли число простым или нет. Перейти к редактору 10. Напишите программу Python для печати четных чисел из заданного списка. Перейдите в редактор 11. Напишите функцию Python, чтобы проверить, является ли число идеальным или нет. Перейти к редактору 12. Напишите функцию Python, которая проверяет, является ли переданная строка палиндромом. 13. Напишите функцию Python, которая выводит первые n строк треугольника Паскаля. Перейти к редактору Пример треугольника Паскаля: Каждое число - это два числа над ним, сложенные вместе Перейти в редактор 14. Напишите функцию Python, чтобы проверить, является ли строка панграммой или нет. Перейти к редактору 15. Напишите программу Python, которая принимает в качестве входных данных последовательность слов, разделенных дефисом, и печатает слова в последовательности, разделенной дефисом, после сортировки по алфавиту. Перейдите в редактор 16. Напишите функцию Python для создания и печати списка, в котором значения представляют собой квадрат чисел от 1 до 30 (оба включены).Перейдите в редактор 17. Напишите программу Python для создания цепочки декораторов функций (полужирный, курсив, подчеркивание и т. Д.) На Python. Перейдите в редактор 18. Напишите программу Python для выполнения строки, содержащей код Python. Перейдите в редактор 19. Напишите программу Python для доступа к функции внутри функции.Перейдите в редактор 20. Напишите программу Python для определения количества локальных переменных, объявленных в функции. Перейдите в редактор 21. Напишите программу Python, которая вызывает заданную функцию через определенные миллисекунды. Перейдите в редактор Редактор кода Python:Еще больше впереди! Не отправляйте здесь какие-либо решения вышеуказанных упражнений, если вы хотите внести свой вклад, перейдите на соответствующую страницу упражнений. Python: советы дняКак разбить список на части одинакового размера? Вот генератор, который выдает нужные вам фрагменты: def chunks (lst, n):
"" "Получение последовательных фрагментов размером n из lst." ""
для i в диапазоне (0, len (lst), n):
yield lst [i: i + n]
импортных отпечатков pprint.pprint (список (чанки (диапазон (10, 75), 10))) [[10, 11, 12, 13, 14, 15, 16, 17, 18, 19], [20, 21, 22, 23, 24, 25, 26, 27, 28, 29], [30, 31, 32, 33, 34, 35, 36, 37, 38, 39], [40, 41, 42, 43, 44, 45, 46, 47, 48, 49], [50, 51, 52, 53, 54, 55, 56, 57, 58, 59], [60, 61, 62, 63, 64, 65, 66, 67, 68, 69], [70, 71, 72, 73, 74]] Если вы используете Python 2, вы должны использовать xrange () вместо range (): def chunks (lst, n):
"" "Получите последовательные порции размером n из lst."" "
для i в xrange (0, len (lst), n):
yield lst [i: i + n]
Также вы можете просто использовать понимание списка вместо написания функции, хотя рекомендуется инкапсулировать подобные операции в именованные функции, чтобы ваш код было легче понять. Python 3: [lst [i: i + n] для i в диапазоне (0, len (lst), n)] Python 2 версия: [lst [i: i + n] для i в xrange (0, len (lst), n)] Ссылка: https://bit.ly/3hvec19 Python-функций - AskPython
Как определить функцию в Python?Мы можем определить функцию в Python, используя ключевое слово def . Давайте посмотрим на пару примеров функции в Python.
def привет ():
print ('Привет, мир')
def add (x, y):
print (аргументы f: {x} и {y} ')
вернуть x + y
На основе приведенных выше примеров мы можем определить структуру функции как это.
def имя_функции (аргументы):
# операторов кода
Функции Python Как вызвать функцию в Python?Мы можем вызывать функцию по ее имени. Если функция принимает параметры, мы должны передать их при вызове функции.
Привет()
сумма = добавить (10, 5)
print (f'sum равно {sum} ')
Мы вызываем определенные нами функции hello () и add (). Мы также вызываем функцию print (), которая является одной из встроенных функций в Python. Типы функций PythonВ Python есть два типа функций.
Может ли функция иметь значение параметра по умолчанию?Python допускает значения по умолчанию для параметров функции. Если вызывающий абонент не передает параметр, используется значение по умолчанию.
def привет (год = 2019):
print (f'Hello World {год} ')
hello (2020) # параметр функции передан
hello () # параметр функции не передан, поэтому будет использоваться значение по умолчанию
Выход: Привет, мир 2020 Привет, мир 2019 Можно ли иметь несколько операторов возврата внутри функции?Да, функция может иметь несколько операторов возврата.Однако при достижении одного из операторов return выполнение функции прекращается, и значение возвращается вызывающей стороне.
def odd_even_checker (я):
если я% 2 == 0:
вернуть 'даже'
еще:
вернуть "нечетное"
печать (odd_even_checker (20))
печать (odd_even_checker (15))
Может ли функция Python возвращать несколько значений одно за другим?Функция Python может возвращать несколько значений одно за другим. Он реализован с использованием ключевого слова yield. Это полезно, когда вы хотите, чтобы функция возвращала большое количество значений и обрабатывала их.Мы можем разделить возвращаемые значения на несколько частей, используя оператор yield. Этот тип функции также называется функцией генератора.
def return_odd_ints (i):
х = 1
в то время как x <= i:
доход x
х + = 2
output = return_odd_ints (10)
для вывода на выходе:
распечатать)
Вывод: Аргументы переменных функций PythonPython допускает три типа параметров в определении функции.
Некоторые важные моменты относительно переменных аргументов в Python:
Вот простой пример использования переменных аргументов в функции.
def add (x, y, * args, ** kwargs):
сумма = х + у
для аргументов:
сумма + = а
для k, v в kwargs.items ():
сумма + = v
сумма возврата
total = add (1, 2, * (3, 4), ** {"k1": 5, "k2": 6})
печать (всего) # 21
Рекурсивная функция PythonКогда функция вызывает сама себя, она называется рекурсивной функцией.В программировании этот сценарий называется рекурсией. Вы должны быть очень осторожны при использовании рекурсии, потому что есть вероятность, что функция никогда не завершится и перейдет в бесконечный цикл. Вот простой пример печати ряда Фибоначчи с использованием рекурсии.
def fibonacci_numbers_at_index (количество):
если count <= 1:
счетчик возврата
еще:
вернуть fibonacci_numbers_at_index (count - 1) + fibonacci_numbers_at_index (count - 2)
count = 5
я = 1
в то время как я <= count:
печать (fibonacci_numbers_at_index (i))
я + = 1
Хорошо знать о рекурсии, но в большинстве случаев при программировании это не нужно.Вы можете сделать то же самое, используя цикл for или while. Тип данных функции PythonФункции Python являются экземплярами класса «функция». Мы можем проверить это с помощью функции type ().
def foo ():
проходить
печать (тип (foo))
Вывод : Функция Python против метода
Давайте посмотрим на простой пример функций и методов в Python.
Данные класса:
def foo (сам):
print ('метод foo')
def foo ():
print ('функция foo')
# вызов функции
foo ()
# вызов метода
d = Данные ()
d.foo ()
# проверка типов данных
печать (тип (foo))
печать (введите (d.foo))
Выход: функция foo foo метод <класс 'функция'> <класс 'метод'> Преимущества функций Python
Анонимная функция PythonАнонимные функции не имеют имени.Мы можем определить анонимную функцию в Python, используя ключевое слово lambda.
def квадрат (x):
вернуть х * х
f_square = лямбда x: x * x
print (квадрат (10)) # 100
print (f_square (10)) # 100
ЗаключениеФункции являются важной частью языка программирования. Функции Python определяются с помощью ключевого слова def. У нас может быть переменное количество аргументов в функции Python. Python также поддерживает анонимную функцию. Они могут возвращать одно значение или давать несколько значений одно за другим. Изменения встроенных функций - документация Conservative Python 3 Porting Guide 1.0 Python 3 претерпел некоторые изменения во встроенных функциях. Функция
До того, как Python впервые представил аргументы ключевого слова и даже функции с печать 'a + b =', напечатать a + b print >> sys.stderr, 'Вычислили сумму' В Python 3 этот оператор отсутствует. Вместо этого вы можете использовать print ('a + b =', конец = '')
печать (a + b)
print ('Вычислили сумму', file = sys.stderr)
Функциональная форма из __future__ import print_function Рекомендуемый фиксатор добавит будущий импорт и перепишет все использования Вход сейфа
В Python 2 функция Python 2 также имел нормальную версию В Python 3 Библиотека совместимости: шесть библиотек включают помощник, Рекомендуемый фиксатор импортирует этот помощник как Удалено
В Python 2
Рекомендуемый фиксатор предназначен для первого использования: он перепишет все вызовы в Исправитель не рассматривает второй случай. Есть много видов файловых Если необходима проверка типов файлов, мы рекомендуем использовать кортеж типов. импорт io
пытаться:
# Python 2: "файл" встроен
file_types = файл, io.IOBase
кроме NameError:
# Python 3: "файл" полностью заменен на IOBase
file_types = (io.IOBase,)
...
isinstance (f, типы_файлов)
Удалено
В Python 2 встроена функция Код: аргумента = [7, 3] применить (сложный, аргументы) можно заменить на: аргумента = [7, 3] сложный (* аргументы) Рекомендуемое средство исправления заменяет все вызовы Перемещено
В Python 2 встроена функция Новое местоположение также доступно в Python 2.6+, поэтому это удаление можно исправить. из functools import reduce Рекомендуемый установщик добавит этот импорт автоматически. Функция
В Python 2 Было три случая для формы заявления exec some_code exec some_code в глобальных переменных exec some_code в глобальных, локальных Аналогично, функция exec (some_code) exec (some_code, глобальные переменные) exec (some_code, глобальные, локальные) В Python 2 синтаксис был расширен, поэтому первое выражение может быть Рекомендуемый фиксатор преобразует все варианты использования Удалено
Python 2 включал функцию примерно соответствовал: из io import open
def compile_file (имя файла):
с open (имя файла, кодировка = 'utf-8') как f:
возвратная компиляция (ф.чтение (), имя файла, 'exec')
exec (файл_компиляции (имя файла))
Если ваш код использует Хотя в Automated fixer: python-modernize есть средство исправления Обратите внимание, что приведенное выше жестко кодирует кодировку В этом руководстве рассматривается функция io.open () . Перемещено
Функция Python 2.7 включал модуль Если в вашем коде используется попробуйте:
# Python 2: "перезагрузка" встроена
перезагрузить
кроме NameError:
из importlib import reload
Переехал
Функция Если в вашем коде используется попробуйте:
# Python 2: "стажер" встроен
стажер
кроме NameError:
от sys import intern
Удалено
Python 3 удаляет устаревшую функцию Если ваш код использует его, измените код, чтобы он не требовался. Если какой-либо из ваших классов определяет специальный метод . |